[논문 리뷰] Physics-informed neural networks (PINNs)

이 글은 논문 [Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations]의 내용을 읽고 정리한 리뷰입니다.
1. Introduction
1.1 데이터 부족 문제와 물리 기반 학습
물리, 생명, 공학 시스템에서는 데이터 수집 비용이 높아 충분한 데이터를 확보하기 어렵다. 이러한 데이터 부족 환경에서는 CNN, RNN 등 최신 딥러닝 기법이 강건성 부족, 수렴 불안정 등의 문제를 보인다.
반면, 물리 법칙이나 도메인 지식과 같은 사전 정보는 학습 과정에서 정규화 역할을 하여, 물리적으로 타당한 해만을 고려하도록 제한할 수 있다. 이를 통해 적은 데이터로도 높은 정확도와 일반화 성능을 기대할 수 있다.
1.2 Gaussian Process Regression(GPR)의 한계
GPR은 함수 자체를 확률적으로 모델링하여, 데이터가 적어도 예측과 함께 불확실성 추정이 가능하다. 선형 문제에서는 효과적이었으나, 비선형 문제에는 다음과 같은 제약이 존재한다:
- 국소 선형화 필요: 시간 축을 작게 나누어 비선형 항을 선형으로 근사해야 하며, 이로 인해 계산량 증가 및 정확도 저하가 발생한다.
- 사전 가정의 제약: GPR은 베이지안 방식으로, 커널 함수 등 사전 가정이 필요하다. 가정이 실제와 다를 경우, 표현력이 제한되고 강건성이 저하된다.
2. Problem Setup: PINN의 기본 구조와 적용 대상
본 연구에서는 기존의 선형화나 시간 분할 기법 없이, 딥 뉴럴 네트워크를 활용하여 편미분방정식(PDE) 을 직접적으로 근사한다. 이를 통해 사전 가정 없이도 비선형 문제를 처리할 수 있으며, 자동 미분 기법을 활용하여 물리 법칙을 손실 함수에 통합할 수 있다.
PINN은 시간 의존 및 비선형 PDE를 포함하는 다양한 물리 시스템에 적용 가능하며, 일반적으로 다음과 같은 수식 형태를 따른다:
여기서:
- 는 시간과 공간에 따른 상태 변수 (예: 온도, 속도),
- 는 해당 시스템의 물리 법칙을 나타내는 연산자,
- 는 물리적 특성을 나타내는 계수(예: 점성, 확산 계수)이다.
예를 들어, 1차원 버거스 방정식은 다음과 같이 표현된다:
여기서 는 점성 계수이며, PINN은 이 방정식을 만족하도록 신경망을 학습시킴으로써 시스템의 상태 또는 계수 를 추정할 수 있다.
또한 PINN은 다음 두 가지 문제 유형에 적용 가능하다:
- Data-driven solution: PDE 구조는 알려져 있고, 상태 변수 를 예측
- Data-driven discovery: 상태 변수는 관측되었고, PDE의 계수 를 추정
PINN 수식의 기본 형태에 시간 미분 항 가 포함되어 있지만, 시간 변화가 없는 정적 문제(steady-state) 의 경우에는 이를 제거한 형태로도 동일한 원리를 적용할 수 있다.
3. Data-driven solutions of partial differential equations
Physics-Informed Neural Networks(PINNs)는 관측 데이터뿐만 아니라, 물리 법칙이 내포된 편미분방정식(PDE)을 손실 함수에 통합함으로써, 시스템의 상태를 신경망을 통해 직접 근사한다. 본 절에서는 시간 의존 PDE를 풀기 위한 연속 시간 모델(Continuous Time Models) 의 구성 방식을 소개한다.
PINN은 다음과 같은 일반 형태의 PDE를 대상으로 한다:
여기서:
- 는 시간과 공간에 따른 상태 변수이며,
- 는 비선형 미분 연산자로 정의되는 물리 법칙이다.
3.1. Continuous time models; 연속적 시간 도메인에서 PDE 푸는 방법
신경망은 상태 함수 u(t,x)를 근사하며, 이 출력값에 대해 자동 미분(automatic differentiation) 을 수행하여 PDE 좌변 전체를 계산한다. 이 과정에서 PDE 수식의 잔차를 다음과 같이 정의한다:
PINN은 와 를 동시에 학습 대상에 포함하며, 다음과 같은 평균 제곱 오차(MSE) 손실 함수를 최소화하도록 학습한다:
- : 초기 및 경계 조건 등 관측 데이터를 기준으로 한 오차
- : PDE 잔차 가 0에 가까워지도록 하는 오차
이때, 는 콜로케이션 포인트(collocation points) 라 불리는 특정 시공간 위치에서 평가되며, 해당 지점에서는 관측값 없이도 물리 법칙만으로 오차를 계산할 수 있다.
차별점과 특징
기존의 물리 기반 머신러닝 접근법들이 신경망을 블랙박스 형태로 사용하는 반면, PINN은 물리 법칙을 네트워크 내부 구조에 통합한다. 특히, 입력값(시간, 공간)에 대한 자동 미분을 통해 물리 제약을 계산함으로써, 정규화 효과를 유도하고, 적은 양의 데이터와 단순한 신경망 구조로도 안정적인 학습이 가능하다.
본 연구에서는 수백~수천 개 수준의 데이터만으로도 학습이 가능하였으며, 최적화에는 L-BFGS 알고리즘을 사용하였다. 이 방식은 이론적 수렴 보장은 없으나, PDE가 well-posed하고 신경망이 충분한 표현력을 가질 경우 높은 예측 정확도를 달성할 수 있음을 실험적으로 확인하였다.
Adam vs. L-BFGS
- (최적화 방식) Adam은 1차 미분만 사용(경사하강법) / L-BFGS는 2차 근사 사용 (quasi-Newton)
- (주요 대상) Adam은 주로 딥러닝 (대규모 데이터, 미니배치) / L-BFGS는 소규모 문제 (전체 배치, 정밀 계산)
- (업데이트 속성) Adam은 미니배치 기반, 확률적 / L-BFGS는 full-batch, 결정적
- (수렴 속도) Adam은 빠르지만 진동 많음 / L-BFGS는 느릴 수 있으나 정확한 수렴 경향
3.1.1. Example: Schrodinger Equation
본 실험은 PINN이 복소수 해를 가지는 비선형 편미분방정식도 정확하게 예측할 수 있는지를 검증하기 위해 설계되었다. 특히, 다음 세 가지 요소에 대한 모델의 표현력을 평가한다:
- 주기적 경계조건 (Periodic boundary conditions)
- 복소수 해 (Complex-valued solution)
- 비선형성 (Nonlinearity)
문제 설정
고전적인 비선형 슈뢰딩거 방정식은 다음과 같은 형태를 갖는다:
여기서 는 복소수 함수이며, 초기조건과 주기적 경계조건이 주어진다. PINN은 이 복소수 해를 예측하기 위해 실수부 , 허수부 를 각각 출력하는 다중 출력 신경망 구조를 사용한다.
학습 데이터 구성
- 초기 조건 h(0,x)에서 샘플링한 50개의 데이터 포인트
- 경계 조건을 만족시키기 위한 50개의 시공간 포인트
- PDE를 강제하기 위한 콜로케이션 포인트 20,000개 → 라틴 하이퍼큐브 샘플링(LHS)을 통해 시공간 전역에서 고르게 선택
실제로 관측된 데이터는 초기 및 경계 조건뿐이며, 나머지 영역은 PINN이 PDE 구조를 학습하여 예측한다.
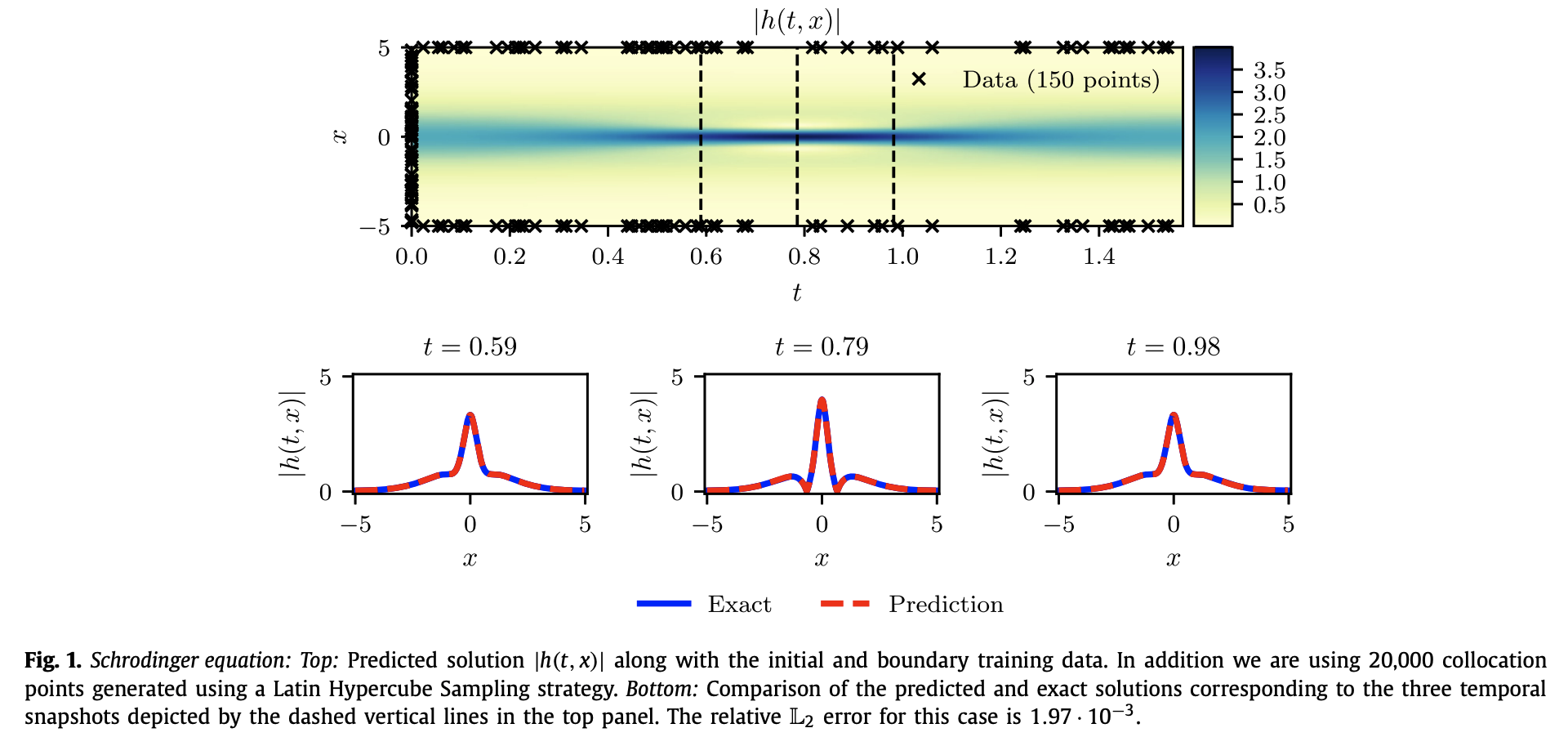
결과 및 해석
- Fig. 1 상단은 예측된 의 전체 시공간 분포를 시각화한 것이다.
- 하단은 세 시점 에 대해 예측값과 정답의 비교를 보여준다.
- 상대 오차는 로 매우 낮은 수준
3.2. Discrete time models; 시간축을 불연속적으로 나누는 방법
앞서 소개한 연속 시간 모델은 시간 t을 입력으로 받아 전 구간의 해 u(t, x)를 신경망으로 근사하는 접근 방식이었다. 본 절에서는 시간 축을 명시적으로 이산화(discretization)하여, Runge–Kutta 방식 기반의 PINN 구조를 제안한다.
Runge–Kutta 기반 시간 전개
Runge–Kutta 방법은 시간에 따라 변화하는 물리 시스템의 상태를 여러 개의 중간 단계(stage)를 통해 예측하는 대표적인 수치적 기법이다. 이를 비선형 편미분방정식(PDE)에 적용하면 다음과 같은 형식으로 표현할 수 있다:
여기서 는 시간 에서의 해를 의미하며, 은 PDE의 비선형 연산자, 는 Runge–Kutta 계수이다.
PINN에의 적용
이산 시간 PINN에서는 다음 시점까지의 해 상태를 동시에 예측하는 다중 출력 신경망을 설계한다. 신경망은 입력 공간 좌표 x를 받아, 다음과 같은 여러 시점의 해를 동시에 출력한다:
이러한 구조는 PDE의 시간 전개 방정식(Runge–Kutta)를 손실함수 내에서 강제함으로써, 신경망이 물리 법칙을 만족하도록 학습되도록 한다. 이 방식은 특히 고차 시간 정확도와 계산 안정성이 필요한 경우 유리하며, 연속 시간 PINN의 한계로 지적된 콜로케이션 포인트 수의 증가 문제를 어느 정도 완화할 수 있다.
3.2.1. Example (Allen–Cahn equation)
Allen–Cahn 방정식은 반응-확산 시스템(reaction–diffusion systems)에서 흔히 나타나는 비선형 편미분방정식(PDE)으로, 다성분 합금의 상분리 현상 등을 기술하는 데 사용된다. 본 예제에서는 PINN의 시간 이산(discrete time) 모델이 복잡한 비선형성을 가진 방정식도 안정적으로 해석할 수 있음을 보인다.
문제 설정
다음과 같은 PDE를 고려한다.
- 초기 조건:
- 경계 조건: 주기적 조건
학습 데이터 구성
- 초기 시점 t = 0.1에서의 해를 수치 시뮬레이션으로 생성하고, 이 중 200개의 샘플을 추출하여 학습 데이터로 사용하였다.
- 예측 목표는 t = 0.9 시점에서의 해 u(x)를 추론하는 것이다.
PINN 구성 및 Runge–Kutta 통합
- PINN은 4층의 완전연결 신경망으로 구성되었으며, 각 층마다 200개의 뉴런을 사용하였다.
- 출력은 Runge–Kutta 방식에 따라 q = 100개의 중간 단계 와 최종 시점 을 동시에 예측한다.
- 이 방식은 수치적으로 이론적 시간 오차가 로, 사실상 머신 정밀도 아래의 오차를 유도할 수 있다.
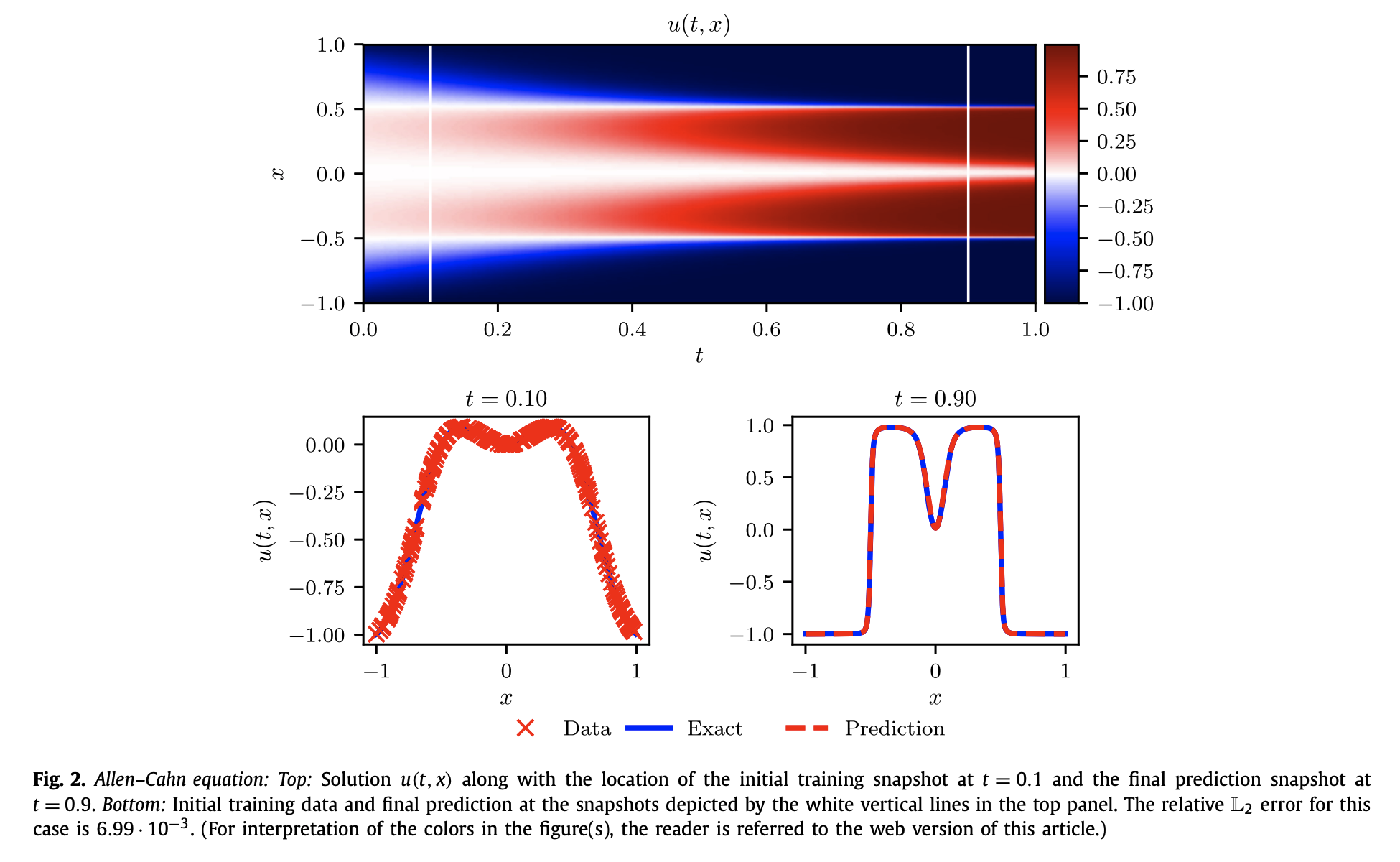
결과 및 해석
- Fig. 2는 PINN이 예측한 의 시공간 해와, 시점 t = 0.1 및 t = 0.9에서의 실제 해와 예측 해를 비교한 결과이다.
- PINN은 오직 t = 0.1의 해만 보고도, 단 한 번의 시간 스텝으로 t = 0.9 시점의 복잡한 해를 정확히 예측하였다.
- 상대 오차는 로, 약 0.7%의 오차만 발생하였다.
시사점
기존 수치 해석에서는 정확한 예측을 위해 시간축을 수천 단계로 분할해야 했지만, 본 예제는 100단계의 Runge–Kutta 연산을 하나의 신경망으로 내재화함으로써 단일 스텝 예측이 가능함을 보여준다. 이는 특히 높은 시간 해상도가 필요한 문제에 대해 계산 효율성과 정확성을 동시에 확보할 수 있는 새로운 접근 방식이다.
(7월 31일 기준)
4. Data-driven discovery of partial differential equations
물리 시스템을 지배하는 편미분방정식(PDE)의 형태나 계수를 데이터로부터 추론하는 문제는 과학적 모델링에서 매우 중요하다. 이 섹션에서는 PINN(Physics-Informed Neural Networks)을 활용하여 관측된 데이터를 바탕으로 PDE 자체를 학습하는 방법을 제안한다.
4.1 Continuous Time Models
PINN은 본래 PDE의 해 를 추정하는 데 사용되지만, PDE 내의 계수 가 미지수인 경우, 이 계수 또한 신경망 학습 대상에 포함시킬 수 있다.
- 일반적인 PDE 형태는 다음과 같다: 여기서
- : 관측 가능한 해 (예: 온도, 밀도 등)
- : PDE의 구조 및 계수를 포함한 미지의 연산자
- : 우리가 추정하고자 하는 물리 계수
- 신경망은 를 근사하고, 자동미분을 통해 이를 t, x에 대해 미분함으로써 를 구성한다.
- 를 0에 가깝게 만드는 방향으로 학습하면서, 동시에 PDE 계수 역시 최적화된다.
구조적 제약과 정규화 역할
PDE가 제공하는 물리 법칙은 신경망에 강한 정규화(regularization) 효과를 준다. 이로 인해:
- 적은 양의 관측 데이터만으로도 일반화 성능을 확보할 수 있으며,
- 기존의 블랙박스 신경망보다 더 해석 가능한 모델을 구축할 수 있다.
(Continue....)
