7. multiprocessor scheduling
멀티코어 프로세스의 증가는 멀티프로세서 스케쥴링 확산의 원인
- Multicore : 여러개의 CPU core가 하나의 칩에 패킹된 것
더 많은 CPU를 더하는 것은 하나의 애플리케이션이 더 빠르게 만든다는 뜻이 아니다.
당신은 threads를 사용하여 병렬로 처리할 수 있을 뿐.
💡 ***Multiple CPUs***에서의 job은 어떻게 schedule 될까?Single CPU with cache

- Cache
- 주로 SRAM
- 작고, 빠른 기억장치이고
- main memory에서 자주 사용되는 데이터를 찾아서 복사해 저장해둔다.
- Utilize temporal and spatial locality
- Main memory
- 주로 DRAM
- 모든 데이터를 저장하고 있다.
- cache보다 느리게 main memory에 접근한다.
Cache coherence
여러 캐시에 저장된 공유 데이터의 일관성(consistency)
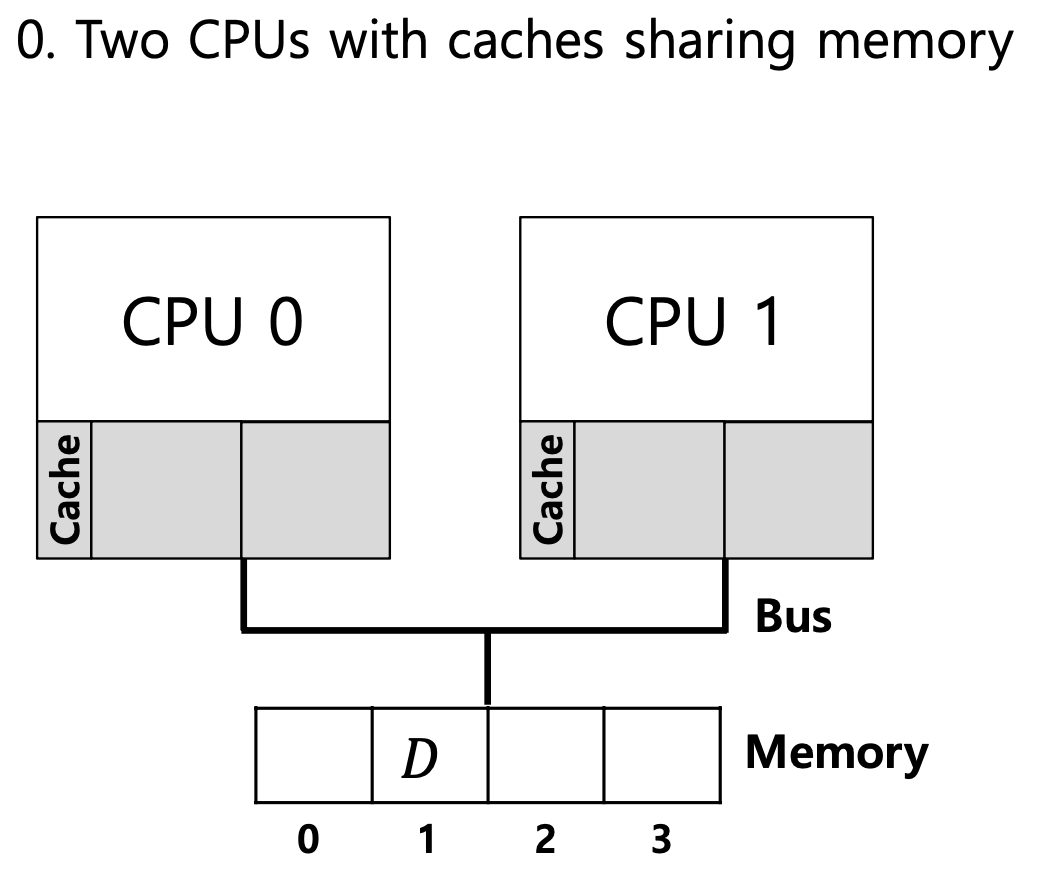
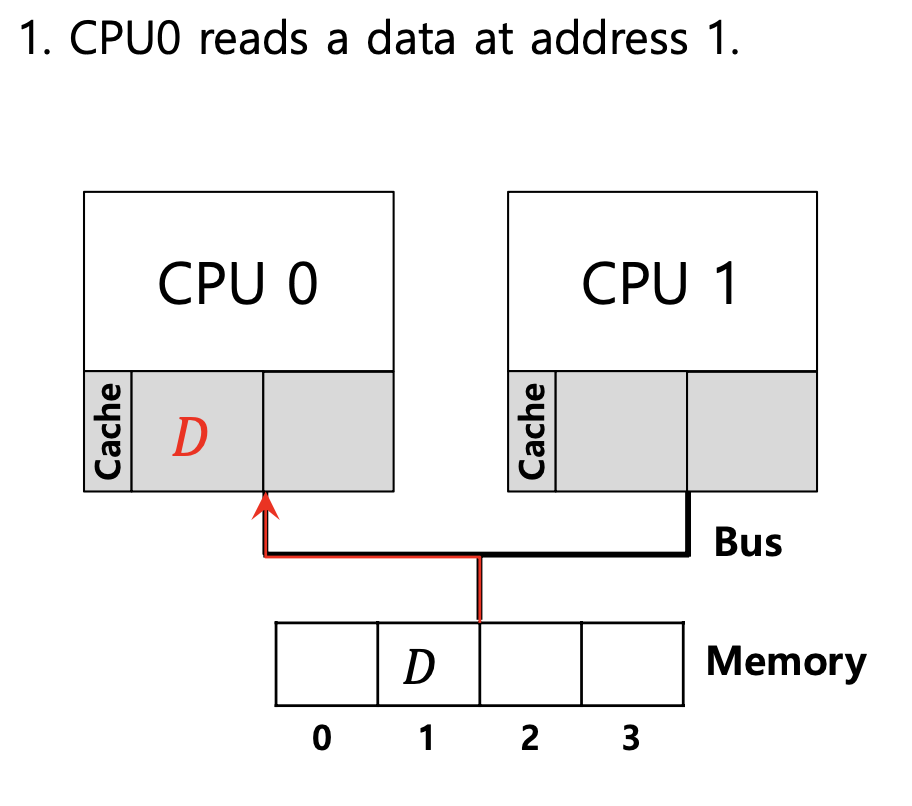
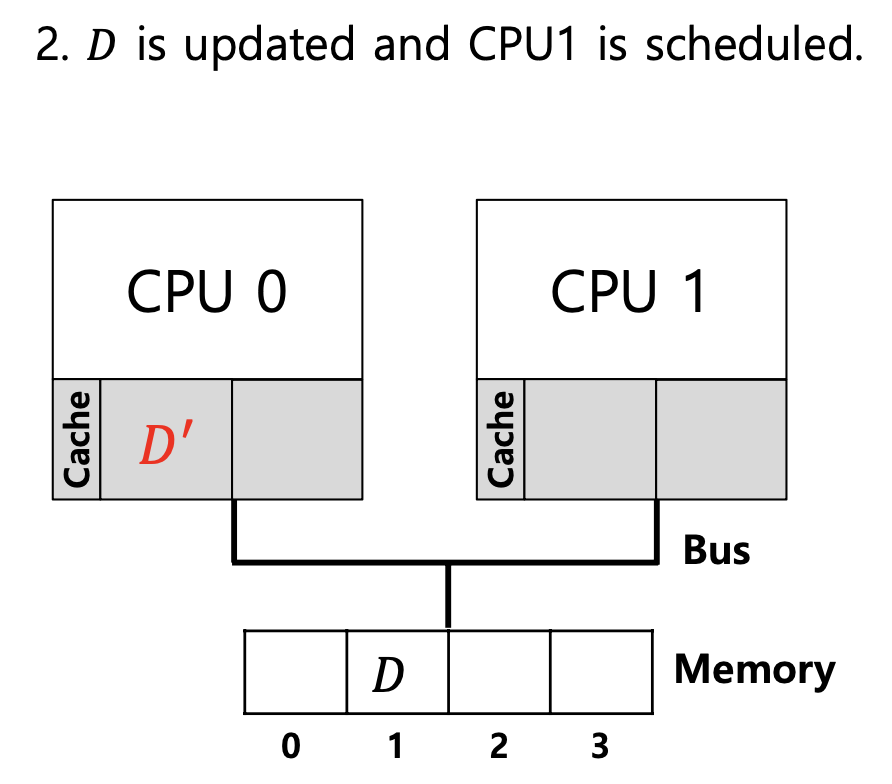
→ 이 상황에서 CPU1 은 예전의 D 값을 가지고 있음.
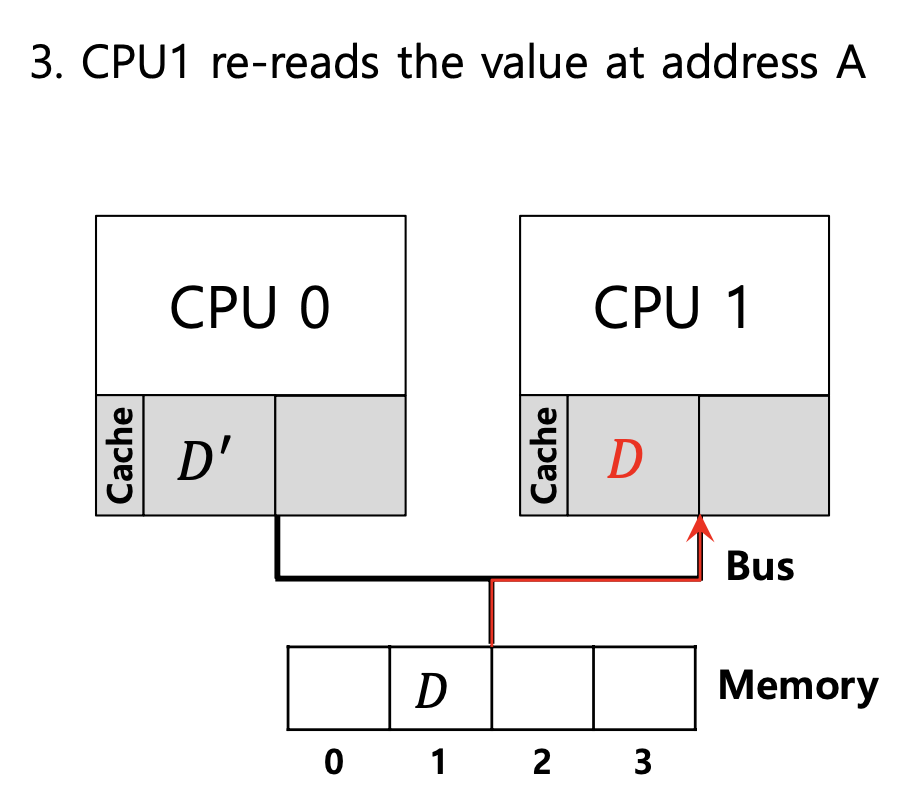
이것이 바로 coherence 문제
Cache coherence solution
1. Bus snooping
bus를 계속 지켜보는 것임.
각각의 cache가 bus를 관찰함으로써 메모리가 update되는지 집중하는 것
cpu가 캐시에 저장된 데이터 항목에 대한 업데이트를 보면, 변경 사항을 인식하고 해당 복사본을 무효화(invalidate)하거나 업데이트 한다.
Synchronization
- cpu를 통해 공유된 데이터에 접근할 때 mutual exclusion이 정확성을 보장하기 위해 사용될 가능성이 높다.
- mutual exclusion = 상호 배제

Cache Affinity
가능하면 프로세스를 동일한 CPU에 유지
- 프로세스는 CPU의 캐시에 상당한 양의 state를 구축한다.
- 다음 프로세스가 실행될 때, 그 상태 중 일부가 이미 CPU의 캐시에 있다면 더 빨리 실행될 것이다.
SQMS
Single Queue Multiprocessor Scheduling
- schedule 해야하는 모든 작업을 하나의 단일 큐에 넣는다.
- 각각의 CPU는 단순하게 다음에 일할 작업을 글로벌하게 공유된 큐에서 선택한다.
- 단점은
-
어떤 형태의 잠금장치를 삽입되어야 한다. → Lack of scalability(확장성)
-
Cache affinity
-
예시
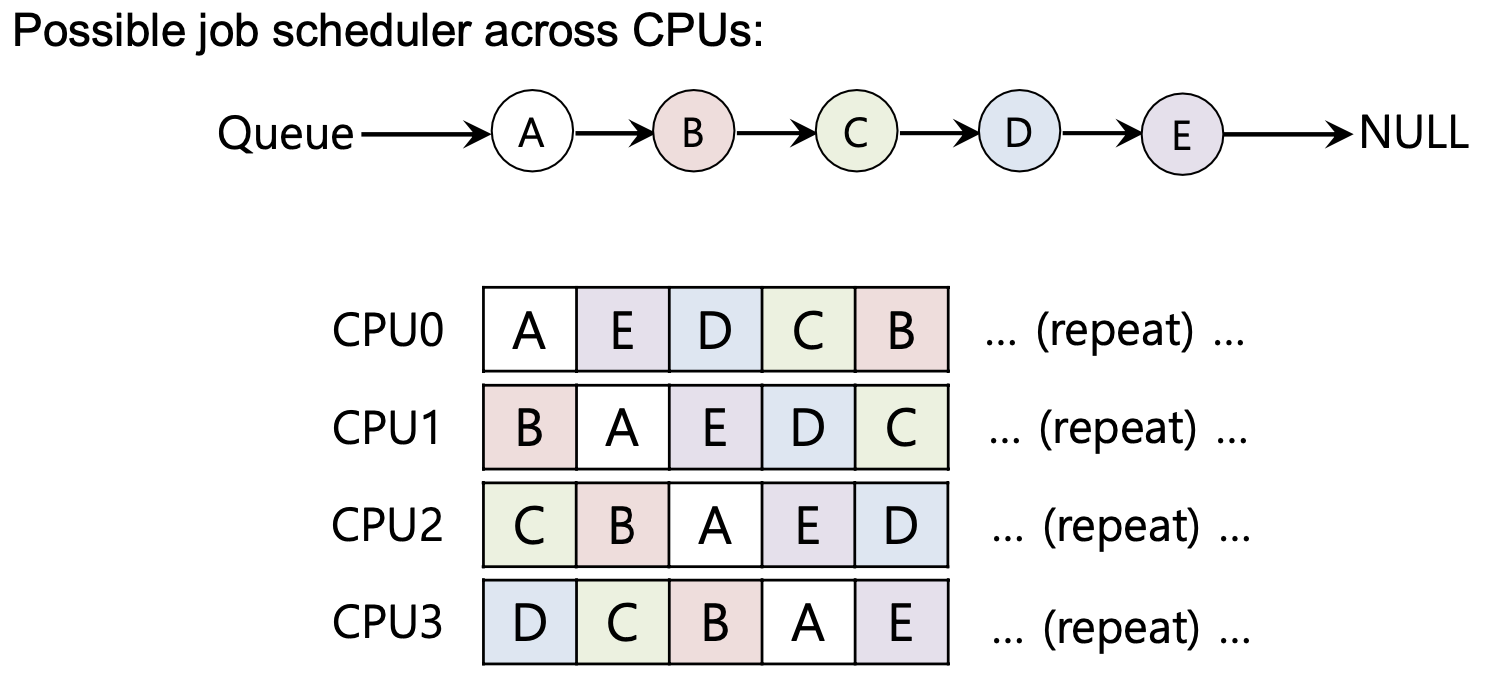
-
- 만약 cache affinity를 가진다면 다음과 같을 수도
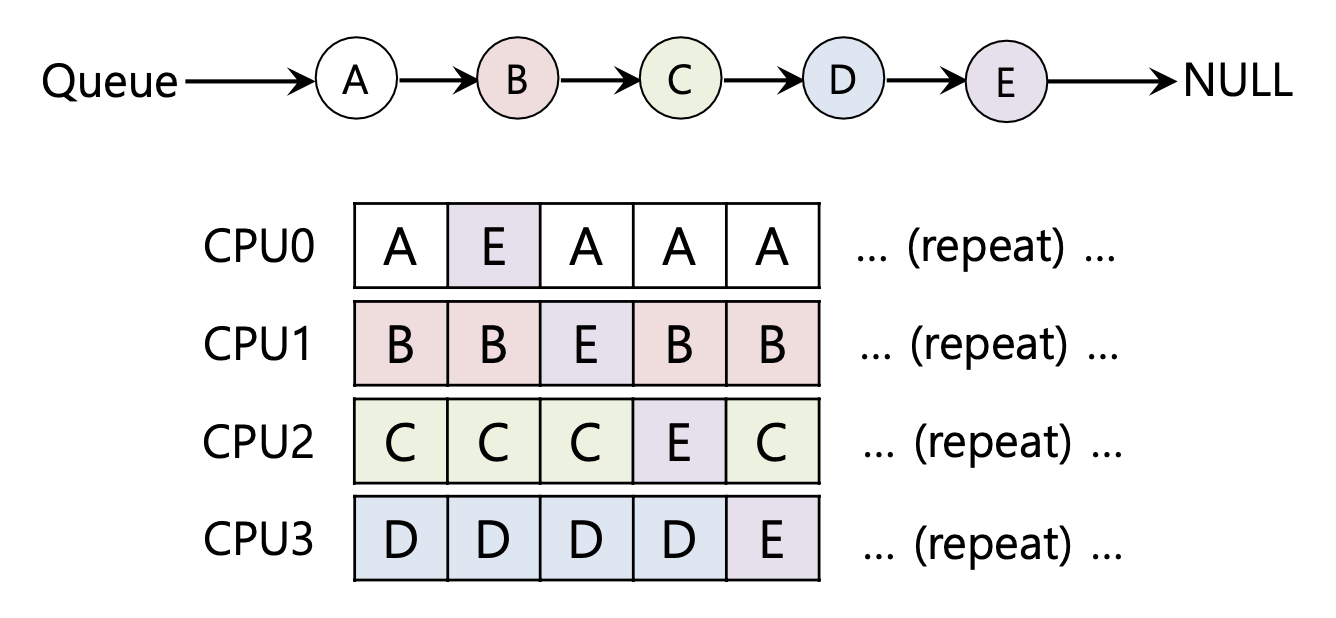
- 가급적 썼던 CPU를 계속 사용한다.
- 대부분의 affinity를 유지한다.
- A부터 D까지는 프로세서 사이를 이동하지 않는다.
- 오직 E많이 cpu에서 cpu로 이동한다.
- 이러한 구조는 구현하기엔 복잡할 수 있다.
MQMS
Multi-queue Multiprocessor Scheduling
MQMS는 multiple scheduling queues을 구성한다.
- 각 큐는 특정 스케쥴링 규율을 따른다.
- 작업이 시스템으로 들어오면 정확히 하나의 스케쥴링 큐에 위치한다.
- 정보 공유와 동기화 문제를 피할 수 있다.
round robin을 사용해서 시스템은 다음과 같은 스케쥴을 생성할 수 있다.
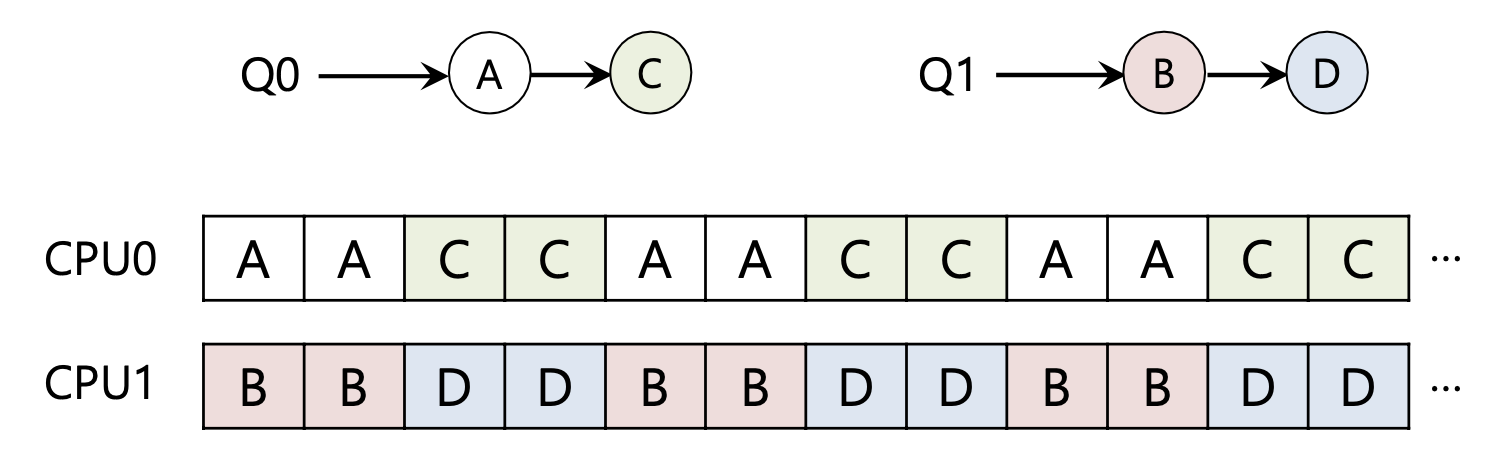
Load Imbalance 작업량 불균형
C 작업이 끝나면 다음과 같은 불균형이 발생할 수 있다.
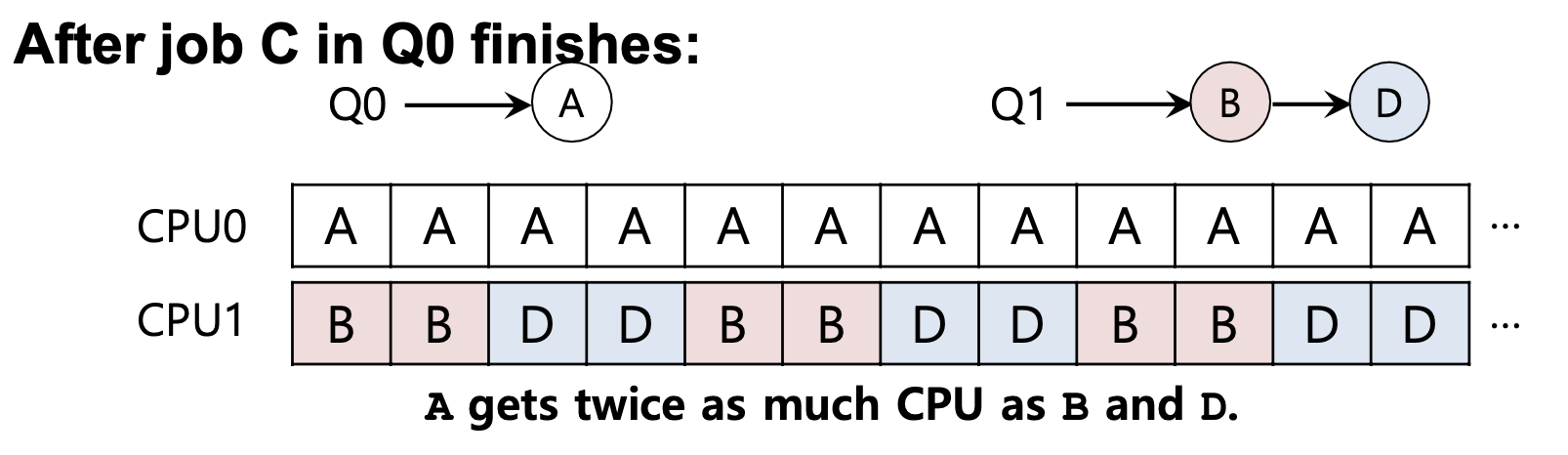
A까지 끝나면 CPU0를 사용되지 않는다.
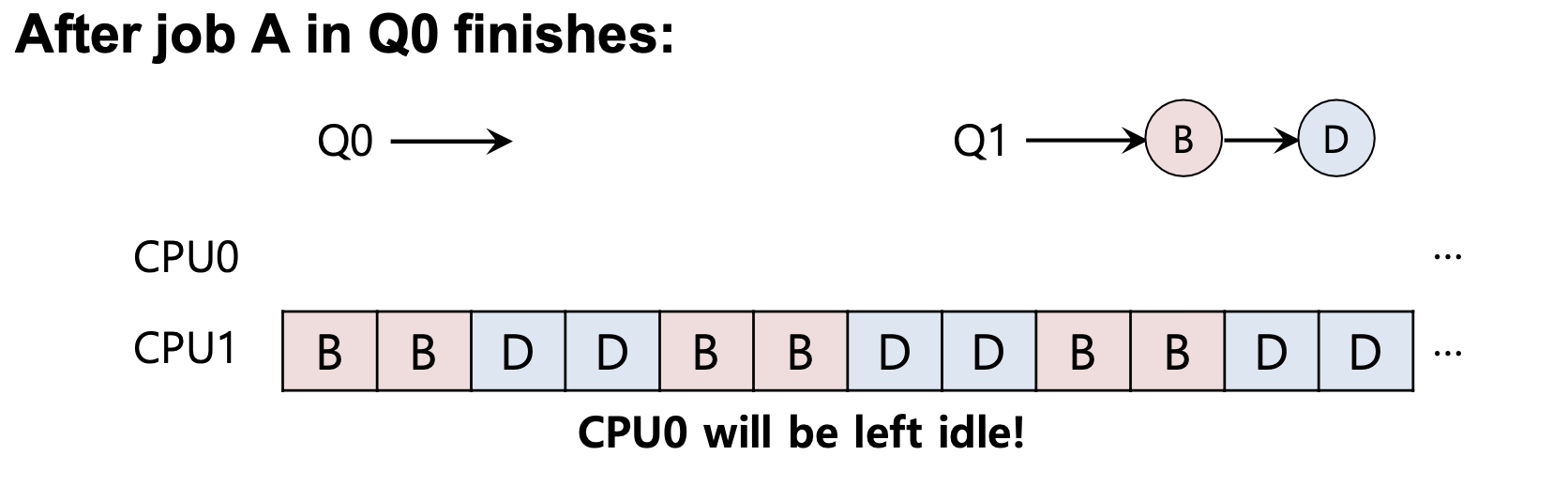
이러한 작업 불균형을 처리하기 위해 작업을 이동하는 Migration을 사용한다.
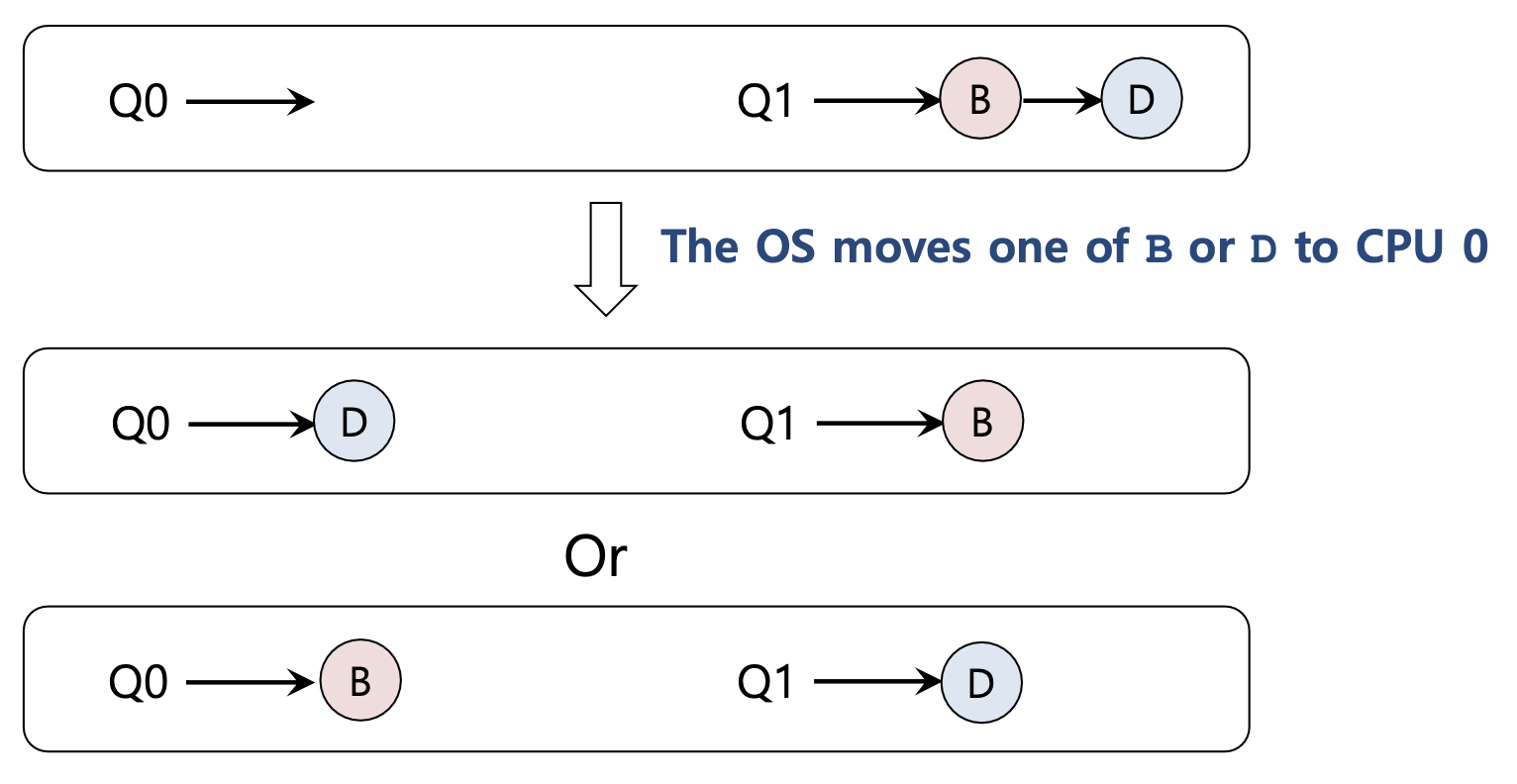

Work Stealing 작업 스틸
큐 사이에서 작업을 이동하는 것
- 구현
- source queue는 짧은 줄로 고른다.
- 때때로 다른 target queue를 들여다 본다.
- 만약 target queue가 source queue보다 더 꽉찼으면, source는 target queue에서 하나 이상의 작업을 steal 한다.
- 단점
-
높은 오버헤드와 scaling의 문제
-
Linux Multiprocessor Schedulers
Time slice로 Time-sharing
- 오직 time slice를 가진 프로세스만 실행 가능하다.
- timer interrupt가 발생했을 때 Time slice를 뺀다.
- time slice = 0일 때, 다른 프로세스가 선택된다.
- 모든 프로세스가 time slice=0일 때, 다시 time slice를 계산해서 수행된다.
Real-time with priority
- 가장 높은 우선순위의 프로세스는 항상 먼저 실행된다.
- 140개의 우선순위 레벨이 있다.
- 낮은 값일 수록 높은 우선순위이다. 0 lv > 140 lv
O(1) Scheduler
이것은 a constant aomunt of time을 가진 ready queue에서 가장 높은 우선순위의 프로세스를 선택한다. 얼마나 많은 프로세스가 실행되고 있는지와는 관계없이.
이것은 ready queue를 우선순위에 따라 multiple queue들로 나눈다.
- 0~99 : real time processes
- 100~139 : non-real time processes
Time slice is given based on the priority

- Active array : 그들의 time slice가 남아있는 프로세스들의 리스트
- Expired array : time slice를 다 쓴 프로세스들의 리스트
- 스케쥴러는 active array에서 가장 높은 우선순위의 프로세스를 선택한다.
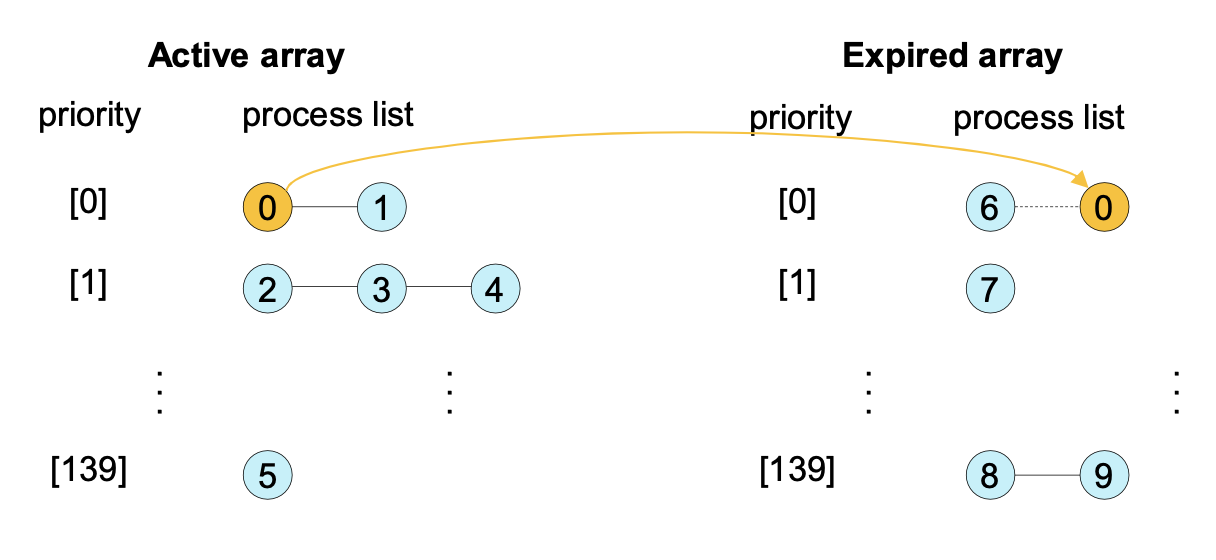
- active array가 모두 비면, two arrays are exchanged 한다.
CFS(Complete Fair Scheduling) scheduler
kernel 2.6.23. 버전부터 들어가있음,
O(1) 스케줄러의 이상한 것을 극복하기 위해 제안되었다.
O(1) 스케쥴러의 우선순위를 기반으로 한 time slice는 다음과 같다.
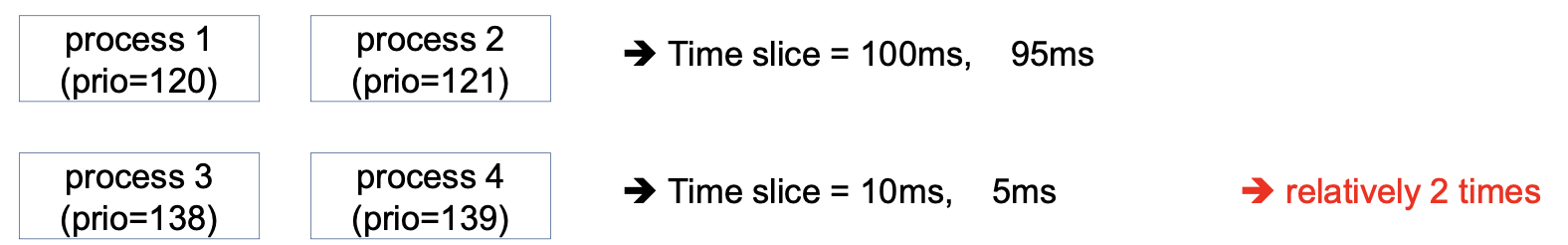
만약 프로세스가 3, 4번 두개밖에 없다면 두 개는 2배 차이가 나는거다.
그래서 weight(가중치)를 기반으로 한 CFS 스케쥴러가 있다.
→ 각 우선순위마다 대략 1.25배 정도 차이가 난다.

Algorithm Evaluation 알고리즘 평가법
1. Deterministic modeling 결정론적 모델링
- 미리 정해진 특정 작업량을 처리한다.
- 그리고 각 알고리즘의 성능을 결정한다.

이것은 SJF(Shortest Job First) 알고리즘의 간트차트이다.
단순하고 빠르며, 알고리즘을 묘사하고 예시를 제공하는데 유용하다.
2. Implementation 구현
- 알고리즘을 평가하는 정확한 방식이다.
- 알고리즘을 코딩하고 운영체제를 수정하는 것이 매우 어렵다.
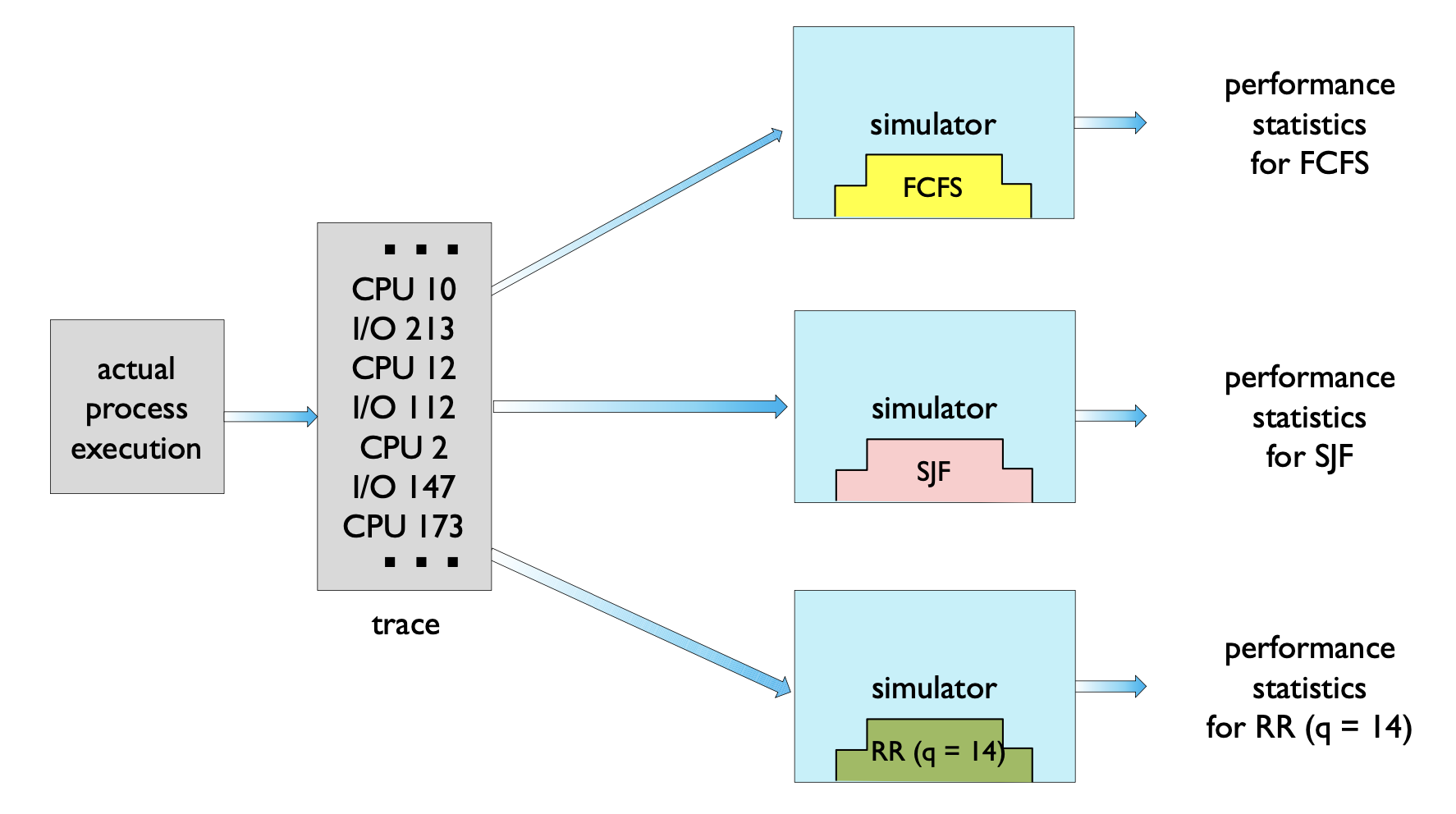
3. Simulation 시뮬레이션
- 컴퓨터 시스템의 모델을 프로그래밍한다.
- 데이터 구조는 시스템의 주요 구성요소로 나타난다.
- 예를 들면 clock 변수
- 랜덤 난수 생성이 요구된다.
- 수많은 프로세스들, CPU burst time, arrivals, departures 등
- Uniform, exponential, poisson 등
- 비쌀 수 있다.
- 디자인, 코딩, 그리고 디버깅하는 것은 시간이 많이 걸린다.
- 큰 저장 공간과 많은 시간이 요구된다.
4. Queueing models
- 수학적인 공식과 함께 사용된다.
- 간단한 큐 네트워크 모델이다.
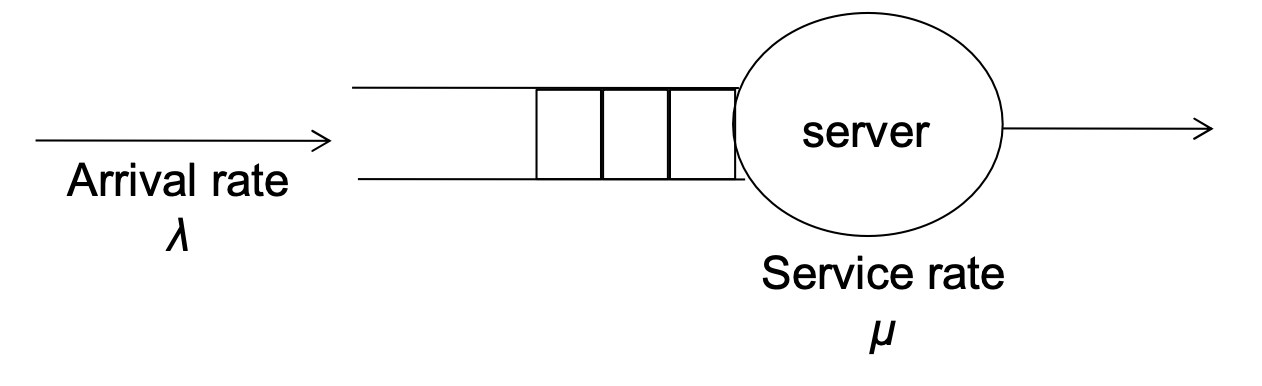
-
arrival rate는 얼마나 자주 들어오는지
-
service rate는 시간당 몇개를 처리할 수 있는지
-
이렇게 arrival rates와 service rates가 주어지고
- utilization, average queue length, average waiting time도 파생될 수 있다.
-
몇몇 평가법에서 제한적으로 사용된다.
