I/O Scheduler
1. 디스크 스케쥴링
목표
디스크 서비스 시간이란?
디스크 드라이브가 I/O 요청을 처리하는데 걸리는 시간을 의미한다.
데이터를 읽거나 쓸 때 소요되는 시간을 측정하는 지표이다. 디스크 서비스 시간이 짧을수록 디스크 I/O 성능이 우수하다고 할 수 있고, 이를 최소화하기 위해 I/O 스케쥴링 알고리즘이 사용된다.
디스크 서비스 시간 = 탐색 시간(seek time) + 회전 시간(rotation delay) + 전송 시간(transfer time)여기서 탐색 시간(seek time)과 회전 시간(rotation delay)를 최소화하면 디스크 서비스 시간을 줄일 수 있다.
- 다만, 회전 지연 시간은 운영체제 입장에서는 고려하기 어렵다.
- 따라서 탐색 시간의 최소화에 주력한다.
Request(요청)
- Request는 데이터를 디스크로부터 읽거나 디스크에 쓰기 위해 운영 체제나 응용 프로그램에 의해 생성되는 작업
- 예를 들어, 파일을 읽거나 쓸 때, 해당 작업은 디스크에 대한 요청이다.
- I/O 스케쥴의 단위
- struct request로 표현
Requeste queue(요청 큐)
- request queue는 처리하지 않은 디스크 I/O 요청의 대기열을 나타낸다.
- 요청들의 대기 큐
- struct request_queue로 표현
I/O Scheduler의 기능
- merging, sorting
I/O 스케줄러 종류
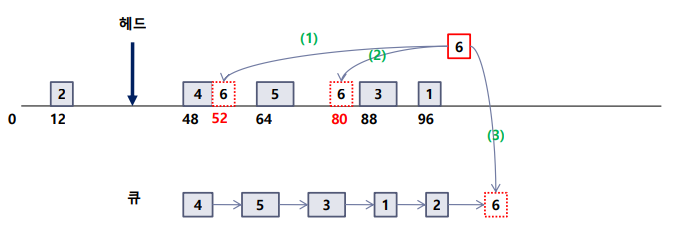
1) Elevator scheduler
- Linux Kernel 2.4에서 사용한다.
- 디스크 헤드의 이동 방향을 고려한다.
- 디스크 헤드가 디스크의 트랙을 오르내리며 I/O 요청을 처리하는 방식을 모방한 것이다.
- Mmerge
- 인접한 I/O 요청이 들어오면 이들을 병합하여 단일 요청으로 처리하려고 시도한다. 이렇게 함으로써 디스크 헤드의 이동을 최소화하고 I/O 처리 효율을 높인다.
- Front, Back
- Elevator 스케쥴러는 큐를 사용하여 I/O 요청을 관리한다. 즉,
Front는 큐의 시작 부분(디스크의 한쪽 끝)을 나타내고,Back은 큐의 끝 부분(다른 쪽 끝)을 나타낸다.
- Elevator 스케쥴러는 큐를 사용하여 I/O 요청을 관리한다. 즉,
- Insertion point : 새로운 I/O 요청이 큐에 삽입될 위치를 결정하는데 사용되는 개념이다.
- 큐에 요청을 삽입할 때는 헤드의 이동 방향에 따라 Front 또는 Back에 위치시키려고 노력한다.
- 삽입 규칙
(1) 기존 요청과 인접한 요청이 들어오면 병합
(2) 물리적으로 적당한 위치에 삽입 : 디스크 헤드의 이동 방향에 따라 위치 정함
(3) 큐에 오랫동안 기다린 요청이 있을 경우, 큐의 맨 끝에 삽입
2) Deadline I/O Scheduler
미리 정의된 마감 시간(deadline) 내에 I/O 요청을 처리하는 데 중점을 둔다.
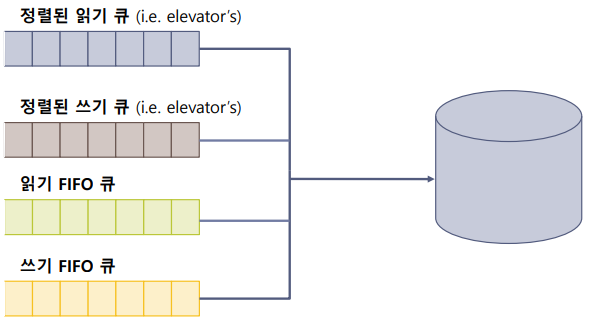
- 4개의 큐 사용
- 정렬된 읽기 큐(Sorted Read Queue), 정렬된 쓰기 큐(Sorted Write Queue), 입력 FIFO 큐(Input FIFO Queue), 출력 FIFO 큐(Output FIFO Queue)
- Deadline이 지난 요청이 없을 경우에 정렬된 큐에서 다음으로 처리할 요청을 꺼내서 처리한다.
- 모든 요청은 해당 요청이 완료되어야 하는 마감시간을 가짐
- 읽기 요청(500ms), 쓰기 요청(5s) : 읽기 요청은 빠르게 처리되고 쓰기 요청은 상대적으로 오랜 시간 동안 대기할 수 있다.
- 기아 현상(starvation) 방지
기아 현상이란? 특정 I/O 요청이 계속해서 우선적으로 처리되어 다른 요청들이 무시되는 상황- 읽기 요청에 상대적으로 높은 우선순위를 부여하고, 읽기 요청을 우선적으로 처리한다.
3) Anticipatory I/O Scheduler
데드라인 스케쥴러를 기반으로 인접한 위치에서 짧은 시간 간격으로 읽기 요청이 발생하는 상황에서 발생하는 문제를 해결하고, 디스크의 효율성을 향상시키는데 목적을 두고 설계되었다.
- 데드라인 I/O 스케쥴러에 기반
- 데드라인 스케쥴러를 기반으로 하며, 개선을 한 버전이다.
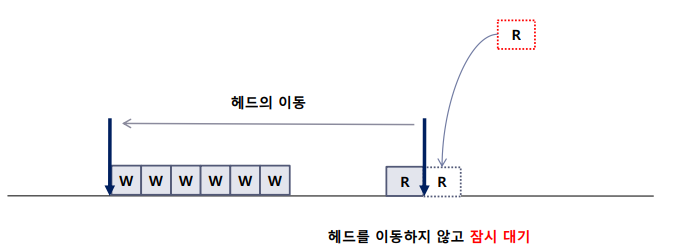
- 인접한 위치에서 짧은 시간 간격으로 읽기 요청이 발생하는 경우, 이러한 읽기 요청을 빈번하게 처리하기 위해 헤드를 끊임없이 이동시키는 것은 비효율적
- Anticipatory 스케쥴러는 헤드를 이동하지 않고, 대신 일정 시간(ex 6ms - 설정 가능한 값) 동안 새로운 읽기 요청을 기다린다.
- 예측 실패 시 오버헤드(Overhead)
- 즉, 위에서 언급한 대기 시간동안, 새로운 읽기 요청이 발생하지 않는 경우,
예측 실패(Prediction Failure)로 간주되며, 이때에는 새로운 요청을 처리하기 위해 헤드를 이동한다.
- 즉, 위에서 언급한 대기 시간동안, 새로운 읽기 요청이 발생하지 않는 경우,
4) CFQ(Complete Fair Queueing) I/O Scheduler
입출력 요청을 하는 모든 프로세스에 대해 디스크 대역폭을 공평하게 할당하는 기법을 제공한다.
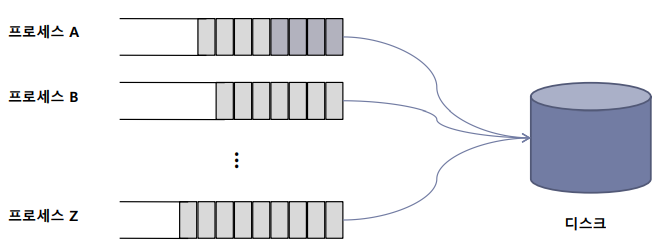
- 프로세스 별 큐 할당
- CFQ 스케쥴러는 I/O 요청한 각 프로세스에 대해 별도의 큐를 할당한다.
- 각 큐는 해당 프로세스의 I/O 요청을 관리하고, 이를 통해 각 프로세스가 독립적으로 I/O 대역폭을 할당받을 수 있다.
- 섹터 순으로 정렬
- 각 프로세스 큐에 들어오는 I/O 요청은 섹터(디스크 블록) 순서대로 정렬된다.
- 이렇게 하면 디스크 헤더의 이동을 최소화하고 I/O 처리를 효율적으로 진행할 수 있다.
- 라운드 로빈 스케쥴링
- CFQ 스케줄러는 각 큐에 있는 I/O 요청을 라운드 로빈 스케쥴링(RR) 방식으로 처리한다
- 이는 각 큐에 공평하게 서비스를 제공하기 위한 메커니즘으로 사용된다.
- 요청 처리 단위 설정
- 설정 가능한 값으로, 각 큐에서 동시에 처리되는 I/O 요청의 수를 나타낸다.
- Default value = 4이며 이렇게 함으로써 프로세스가 짧은 시간 내에 여러번 I/O를 요청하는 경우에도 다른 프로세스에게 CPU 시간을 공평하게 나눠주는 역할을 한다.
5) NOOP(NO Operation) I/O Scheduler
다른 스케쥴러와는 달리 매우 간단한 동작을 수행하며, 주로 특정 환경과 디바이스 유형을 위해 사용된다.
- 인접한 요청 병합
- NOOP 스케쥴러는 인접한 I/O 요청을 병합하는 작업만 수행하고, 그 외에는 아무런 스케쥴링 작업을 하지 않는다.
- 인접한 블록들을 연속적으로 읽거나 쓰는 경우에 유용하다.
- Request FIFO 큐만 유지
- Request FIFO 큐는 요청이 도착한 순서대로 I/O 요청을 처리한다.
- 따라서 요청이 도착한 순서대로 디바이스에 서비스된다.
- Random Access 디바이스를 위한 스케쥴러
- 디스크 헤더의 탐색 비용을 고려하지 않고, 요청이 도착한 순서대로 처리하여 효율적으로 랜덤 엑세스 패턴에 대응한다.
- 탐색에 대한 부담 없음
- 디스크 헤더의 탐색에 대한 부담이 없으므로 디스크 헤더의 이동을 최소화할 필요가 없다.
- 따라서 정렬 작업이 필요하지 않다.
- 플래시 메모리에서 주로 사용
- 플래시 메모리는 랜덤 액세스에 강점을 가진다.
- 디스크의 회전 딜레이나 탐색 비용이 없다.
스케쥴러 확인 / 선택 방법
스케쥴러 확인

스케쥴러 변경
- noop로 변경

Benchmark - IO Zone
- 파일 시스템 벤치마크 프로그램
- Linux, Window, NFS client 환경에서의 I/O 동작의 성능 측정
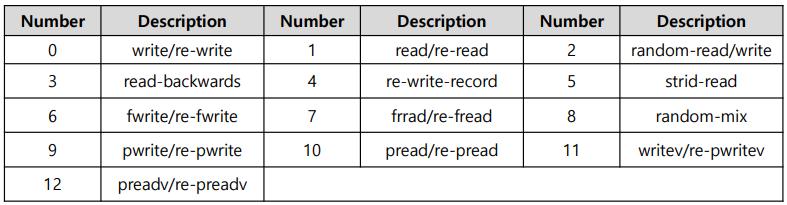
- read, write, re-read, re-write, read backwards, read strided, fread, fwrite, random read, pread, mmap, aio_read, aio_write 등 다양한 테스트 제공
- IO Zone 설치
$ sudo apt-get install iozone3
- IO Zone Options
- -R : Excel report 생성
- -b[filename] : Excel과 호환 가능한 binary file 생성
- -i : test 실행 (ex, -i 1 -i 2)
- -I : 파일에 대한 모든 operation은 buffer cache를 우회 및 disk 직접 이동 (i.e. transferring data synchronously)
- -r# : record size 설정(기본 4K)
- ex. -r 512m -> record size 512MB로 설정
| name | Description |
|---|---|
| k | Size in KB |
| m | Size in MB |
| g | Size in GB |
- -s : file size 설정
- -t : throughput test에 사용할 thread 또는 process 개수 설정
- -F : throughput test에서 각 thread 또는 process 파일 이름
- IO Zone 사용 예제
- 조건
- I/O 실험 결과에 대한 excel file로 작성 및 file name : file_name.xls
- read, write, random write 연산 수행
- buffer cache 거치지 않고 연산 수행
- record size: 512KB
- file size : 512MB
- thread or process 개수 : 1
- thread or process의 파일 경로 : ~/iozone_test
- 조건
$ iozone -R -i 0 -i 1 -i 2 -I -r 512k -s 512m -t 1 -F ~/iozone_test -b file_name.xls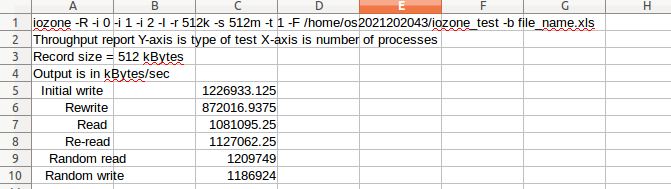

아무것도 모르는 말하는 감자 입니다