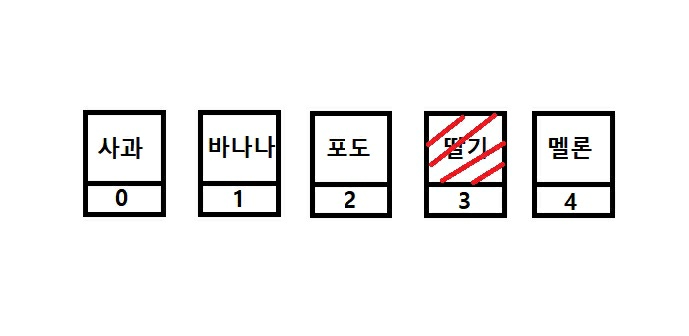
배열(Array)
fruits = ['사과', '바나나', '포도', '딸기', '멜론'];
-data 삭제 시 없어지는 것이 아닌 비워지게 됨
-index가 data에 종속적으로 연결되어 있음
리스트(List)
배열과 달리 index가 data에 종속적이지 않음
data 삽입과 삭제에 대한 data 낭비가 줄고 검색시간이 길어짐
Array List
-내부적으로 배열을 사용 -> index를 이용해 data접근가능 -> data조회속도 UP -data 추가,삭제 시 각 순서를 일정하게 변경되어야 함으로 상대적으로 오랜시간 소요Linked List
-배열사용 X -> 하나의 data에 다음 element의 위치포함 -> 조회속도 DOWN -data 추가,삭제 시 다른 data의 영향을 주지 않기 때문에 상대적으로 빠른시간내에 data추가,삭제 가능
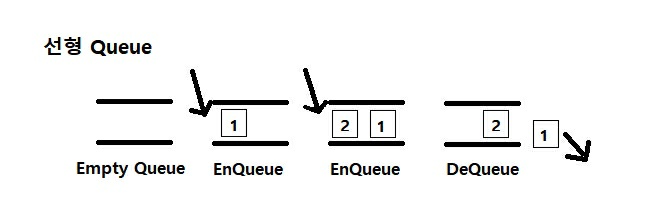
큐(Queue)
-선입,선출로 data가 쌓이며 data를 삽입하는 enqueue와 data를 추출하는 dequeue라는 keyword로 data관리
-Queue는 보편적으로 순서대로 처리해야 하는 작업을 임시로 저장해두는 버퍼(Buffer)로서 사용됨(맛집에서 줄서는 것과 같음)
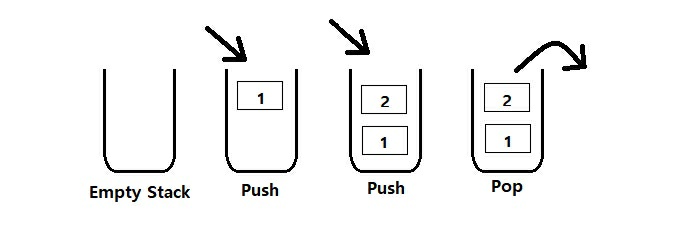
스택(Stack)
-Queue와 다르게 선입,후출 / 후입,선출로 data가 쌓임
-Web browser의 앞으로가기, 뒤로가기와 같음
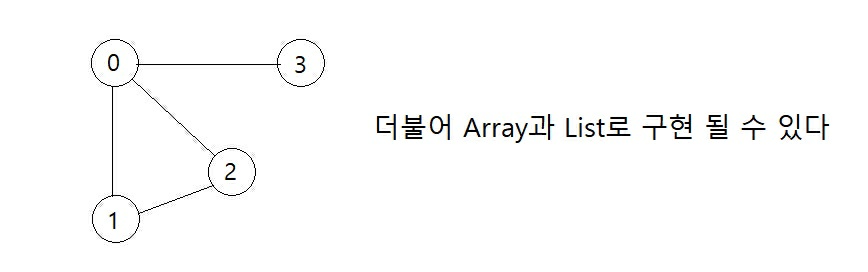
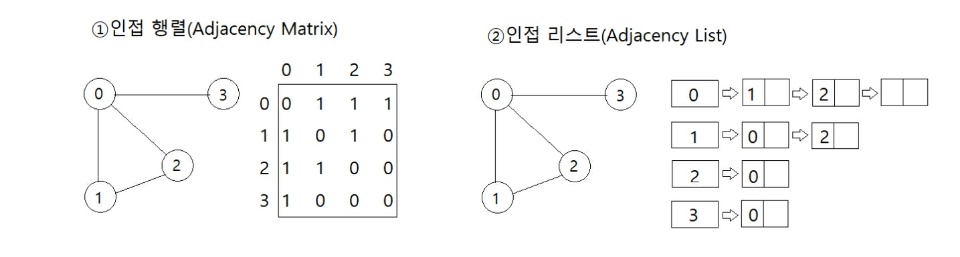
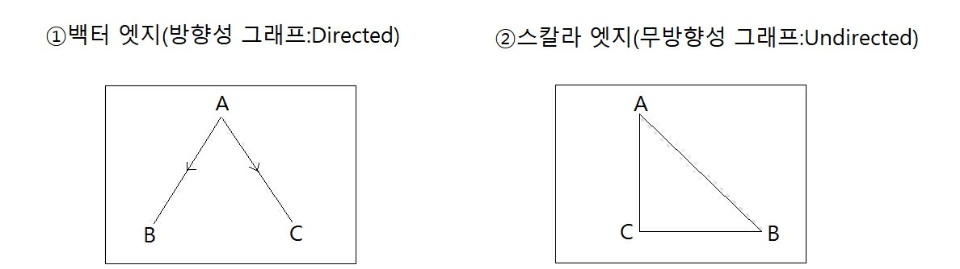
그래프(Graph)
상하위 개념이 없는 Node(혹은 버텍스(vertex))와 Node 사이의 Edge(엣지 혹은 아크(Arc))의 집합으로 데이터를 이루는 형태
트리(Tree)
-여러 data가 계층구조로 연결 된 형태
-root(뿌리)를 기준으로 Leafs(잎사귀)들이 아래로 자라는 나무
트리는 다음의 용어로 정의
1.node(노드): 트리의 data를 저장하는 각 항목 2.child node(자식노드): 노드A의 하층에 노드B가 있다면 노드B는 노드A의 자식노드 3.parend node(부모노드): 노드B의 상층에 노드A가 있다면 노드A는 노드B의 부모노드 4.root node(뿌리노드): 트리의 가장 상층에 있는 노드 5.leaf node(잎 노드): 자식노드가 없는 노드 6.ancestor node(조상노드): 노드 A의 자식을 따라 내려갔을 때 노드 B에 도달할 수 있다면, 노드 A를 노드 B의 조상 노드 7.descendant node(자손노드): 노드 A가 노드 B의 조상 노드일 때, 노드 B를 노드 A의 자손 노드 8.sibling node(형제노드): 같은부모를 가진 다른노드

거북이개발자