데이터엔지니어링?
- 특정 목적의 서비스를 만들기 위해 빅데이터에 파이프라인을 설계하여 구축
데이터 처리 파이프라인
- 데이터 수집, 가공, 저장
Data Structure, 자료구조, 데이터 구조
- 효율적인 접근 조작을 가능하게 하는 데이터 조직, 관리, 저장 구조
Array
- 동종한 값의 모음
- 고정된 값 저장
- 고정된 개수의 값을 저장하여 크기가 초기에 저장
- 크기를 초기에 작게 설정하여 데이터를 다 담지 못하면 큰 배열에 다시 옮겨 담아야 함
리스트 기반의 자료구조의 필요성 야기
공간: 파일시스템> 메모리
속도: 메모리> 파일 시스템
데이터가 메모리에 적재 -> 힙 메모리에 저장된 이메일 데이터를 이용하면 속도의 향상 예상
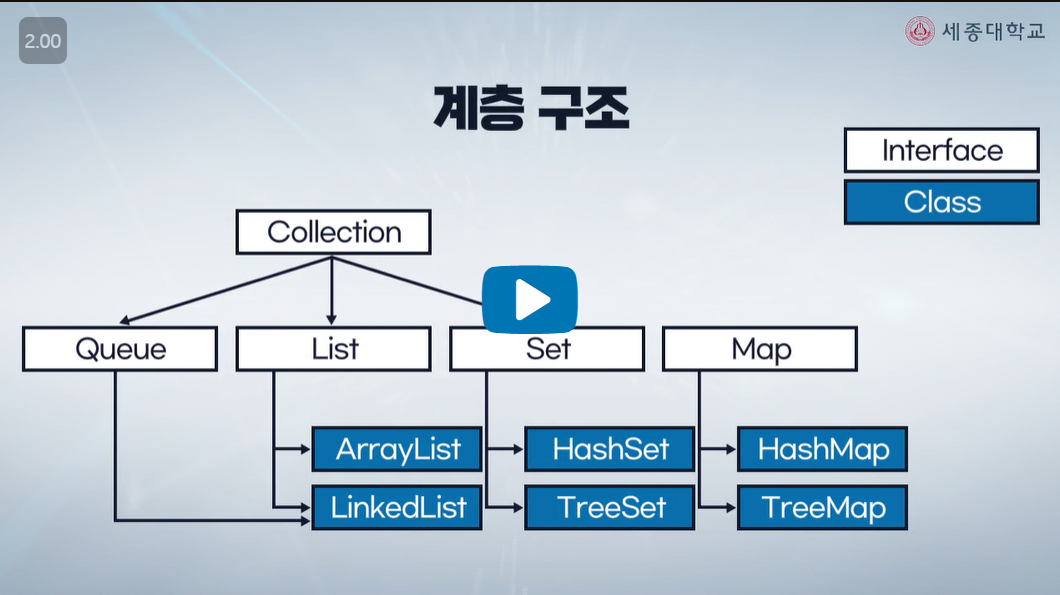
List
- 동적인 크기를 가지고 있어 다루기 편함
- ArrayList, LikedList 효율적으로 구현
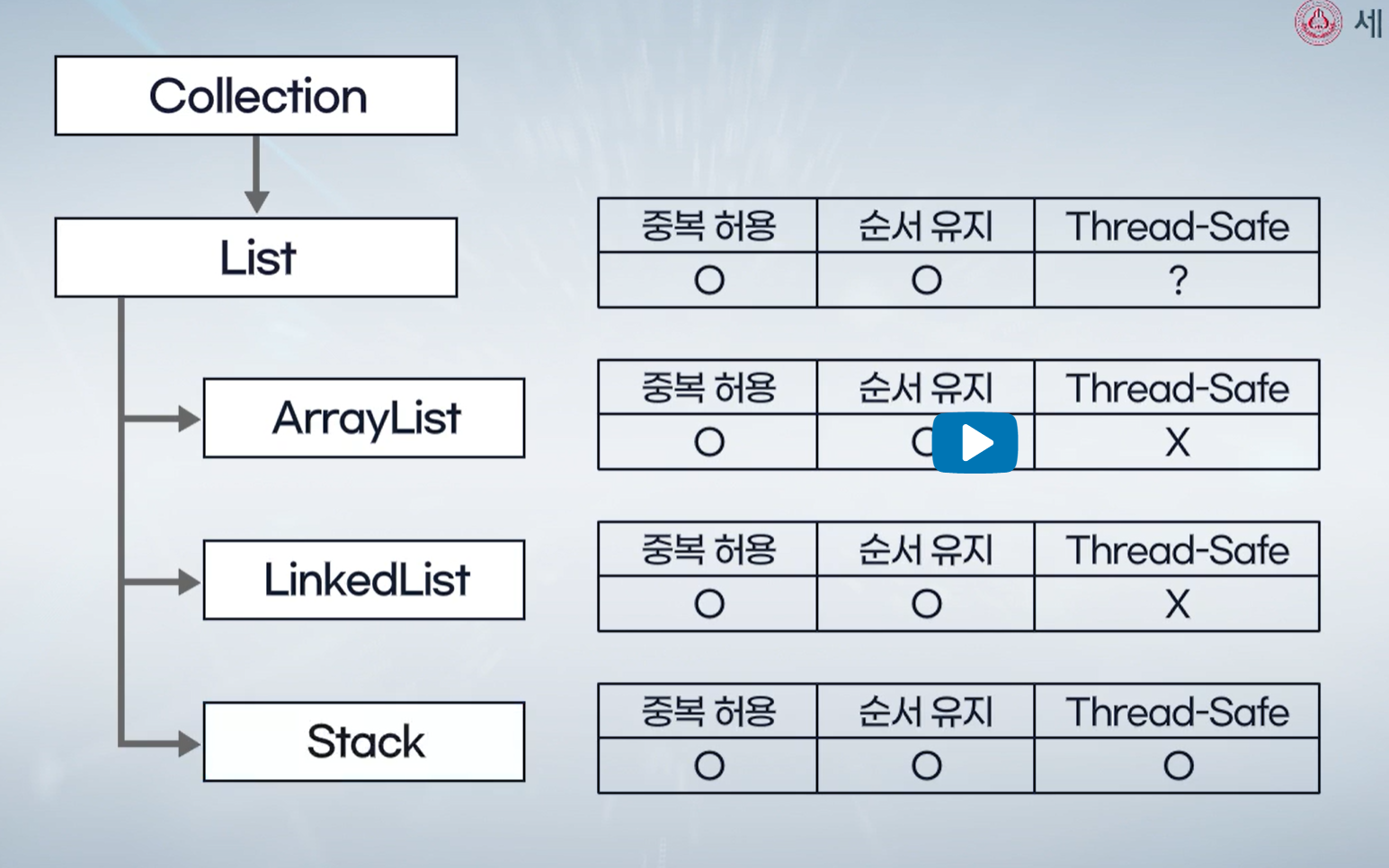
- 순서화된 중복을 허용하는 Collection
- Collection 내에 Instance가 위치할 index를 통해 collection을 조작할 수 있는 기능
- ArrayList: 배열을 기반
- LinkedList: 객체 간의 참조를 기반

Treeset
- 값 사이에 이전 이후 관계 유지
- 최솟값, 최댓값, 이후값, 이전값, 오름차순 순회, 내림차순 순회 효율적
Collection
- 데이터의 모음
- Java Collection Framework의 최상위 Interface
- 멀티스레드 관점에서 어떠한 Collection은 둘 이상의 스레드에 의한 동시 접근에 안전하기도 하며, 그렇지 않기도 함
- Stack은 동시 접근에 안전한 Thread-safe Collection
- LinkedList는 Thread-unsafe한 Collection으로 멀티스레딩 프로그래밍을 할때 개발자가 직접 동기화 논리 구현
- View제공 동기화 용이
- Unmodifiable Collection: 변경이나 조작이 불가능한 Collection도 있다.

Framework
- 일반적인 기능성이 추상화된 소프트웨어
Java Collection Framework
- 효율적인 데이터 접근 조작 가능
- 조직, 관리, 저장 --> 추상화
- Interface + Class
- JDK 1.2 버전부터 제공
ArrayList
- Capacity이 변경 가능한 Array
- 크기 배열 부족 -> 큰 배열 생성 및 기존의 값 복사
- List : 순서화된 중복을 허용하는 Collection
- ArrayList: 배열을 기반으로 List를 구현
- Collection 내에 Instance가 위치할 위치인 index를 통해 조작이 가능
Iterator.remove()
- 현재 iterator가 가르키고 있는 값을 지우는 method
- next를 수행한 이후 한번만 호출하는 것을 권장
ListIterator(index)
-
초기 위치 설정 가능(index-1)
-
Iterator()는 ListIterator(0)과 동일
toArray
-
Collection을 T타입의 배열에 담음
-
들어온 T[]의 사이즈가 size보다 작게 된다면, 사이즈에 맞는 크기의 array를 새로 생성
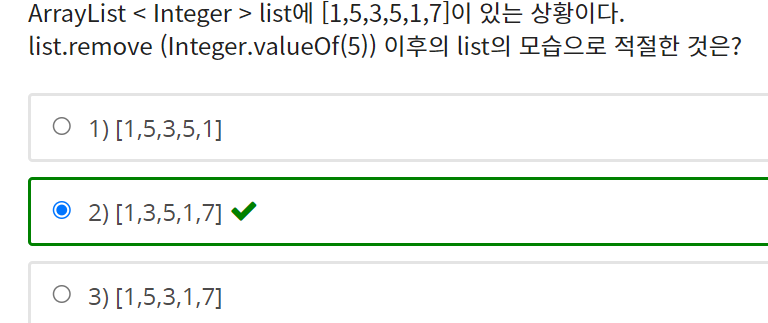
Integer가 String으로 캐스트 될 수 없다
subList
-
View collection
-
반환된 List에 대한 연산은 원래 List에 적용
Iterator
-
set과 같이 index가 없는 Collection은 불가능
-
배열 기반이 아닌 참조 기반 List는 매우 비효율적
next()-> data[++cursor]
previous()-> data[cursor--]toArray
public <T> T[] toArray(T[] a){ if(a.length<data.length){ a=(T[]) Array.newInstance(a.getClass().componentType(),data.length) } for(int i=0;i<data.length;i++){ a[i]=data[i]; } }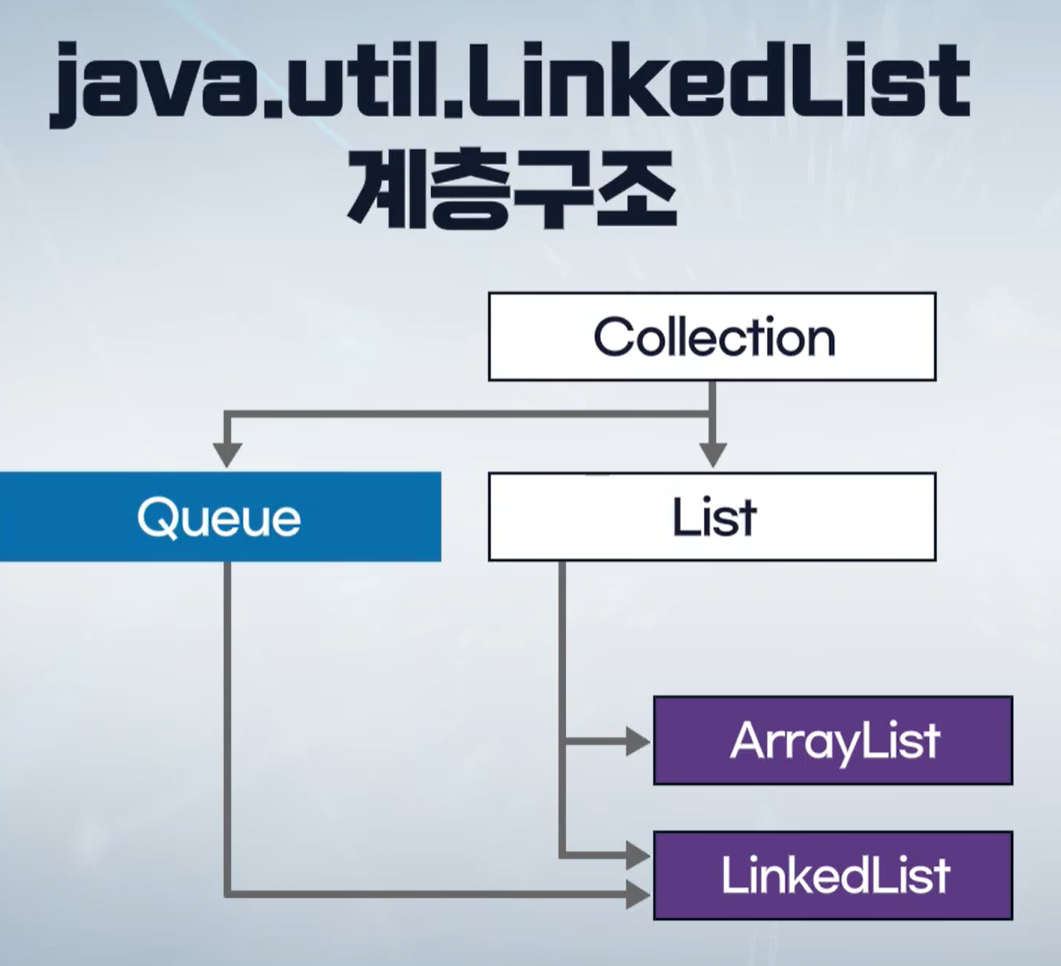
Queue
- 삽입과 추출이 한 방향
- 먼저 삽입된 instance부터 추출
- 버퍼, 스케줄러에 사용
LinkedList
- Doubly LinkedList
- List이자 Queue
- List: 각 노드는 index로서 접근 가능
- Queue: 뒤쪽으로 값을 삽입하고 앞에서 값을 추출
- 노드들이 링크로 연결됨
- 특정 index를 가지고 있기 않기 때문에 특정 위치에 넣으려면 그 index 값을 찾아야 한다.
- 특정 위치를 찾는 비용 소모 되지만, ArrayList와 다르게 요소들을 뒤로 밀 필요가 없다.
- get(index)는 인덱스에 직접 접근하지 않음
- 참조기반 List는 인덱스를 지원하나 배열을 참조하는 것과 같이 상수 시간이 소요되는 것은 아니다.
- 맨 처음에 인덱스가 위치한 listiterator를 만들기 위해 인덱스에 해당하는 Node를 찾아서 유지
- Listiterator는 ArrayList에 비해 비용이 더 든다.
- RandomAccess 구현하지 않음-> subList를 이용해 만들어짐
- Queue : Capacity를 초과할 일이 없다. capacity 초과시 false반환
- 순회할 때 index기반으로 순회하면 엄청 느려짐, iterator를 사용하든지, for each loop문을 사용해서 순회하기
Deque
- 삽입과 추출이 양쪽 방향에서 전부 일어남




Let's study!