✍️ 탐색(search)
탐색(search)이란? 여러 개의 자료 중에서 원하는 자료를 찾는 작업
✍️ 순차 탐색(sequential search)
순차 탐색(sequential search)이란? 탐색 방법 중에서 가장 간단하고 직접적인 탐색 방법
정렬되지 않은 배열을 처음부터 마지막까지 하나씩 검사하는 방법
시간 복잡도: O(n)
일반적으로 순차 탐색을 구현할 경우, 배열의 처음부터 마지막까지 하나씩 우리가 찾는 key값과 같은 값을 비교해 나가면서 찾는다.
But, 배열의 마지막+1번째에 key값을 저장할 경우 하나씩 비교하는 과정이 필요하지 않기 때문에 개선된 효과를 얻을 수 있다.
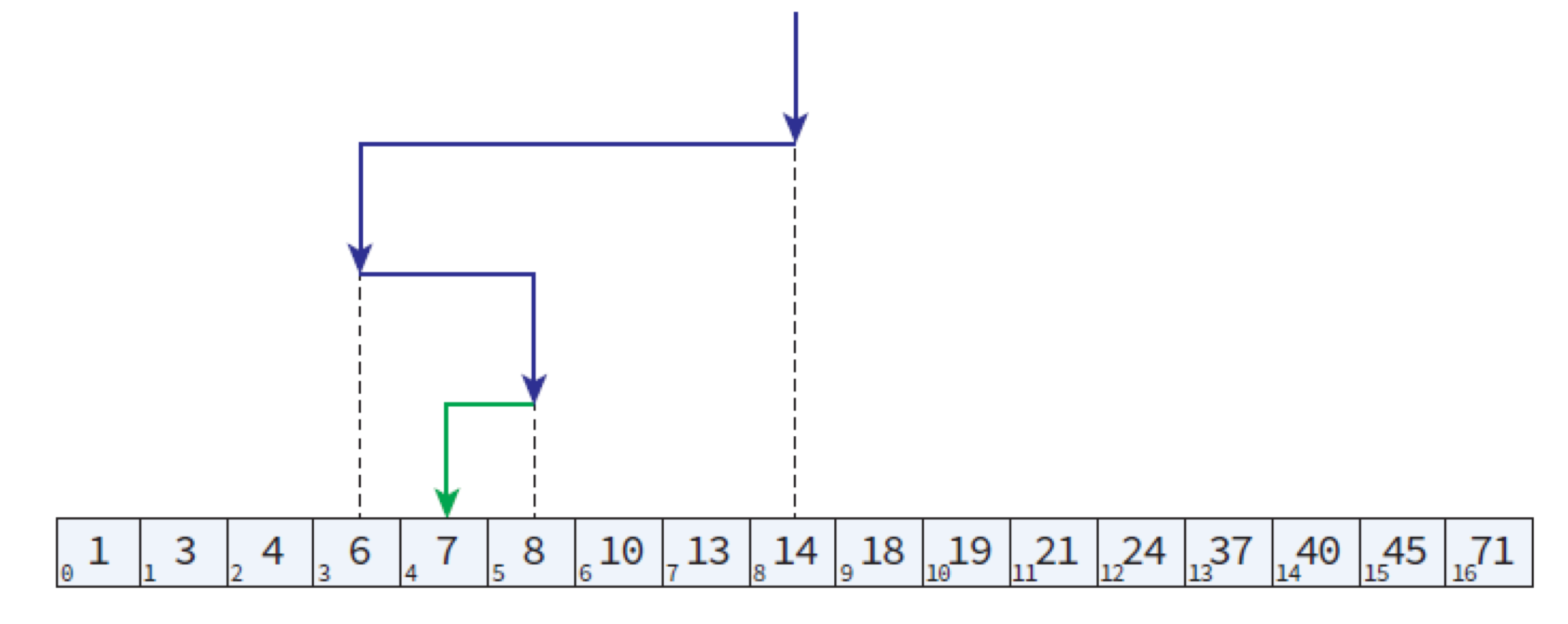
✍️ 이진 탐색(binary search)
이진 탐색(binary search)이란? 정렬된 배열의 중앙에 있는 값을 조사하여 찾고자 하는 항목이 왼쪽 또는 오른쪽 부분 배열에 있는지를 알아내어 탐색의 범위를 반으로 줄여가며 탐색 진행
✍️ 균형 이진 탐색 트리
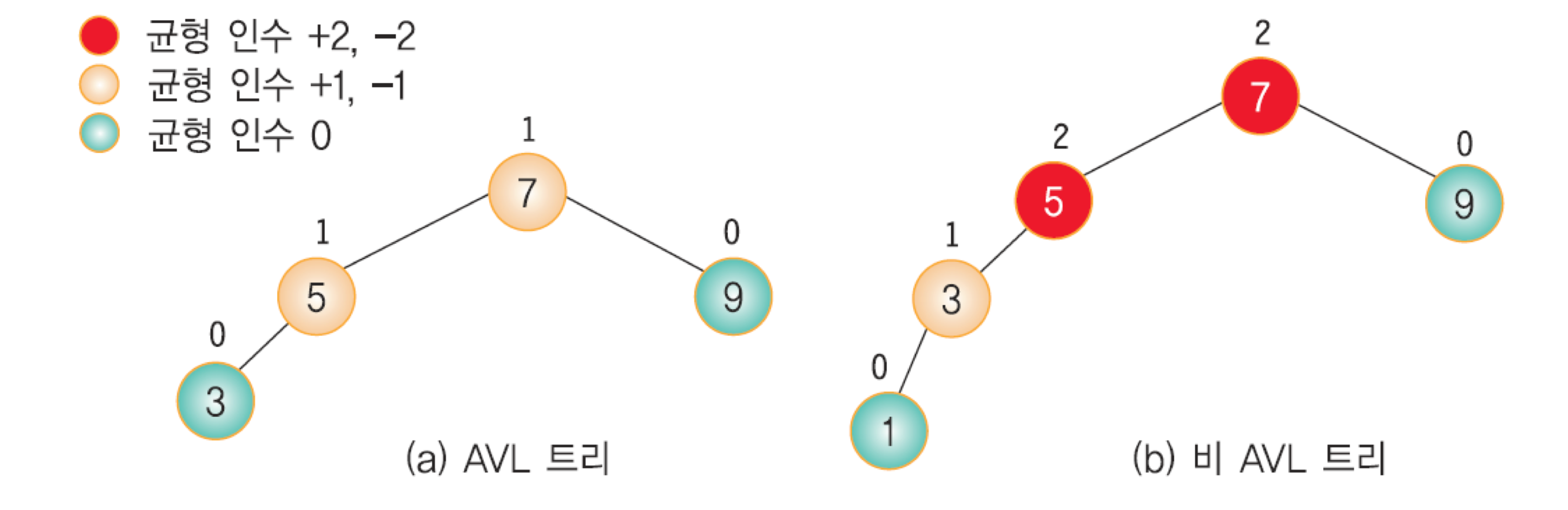
🔍 AVL 트리
왼쪽 subtree와 오른쪽 subtree의 높이 차이가 1이하로만 한다.
why? 트리가 불균형트리일 경우 시간 복잡도가 O(n)인 순차 탐색과 동일하기 때문
시간 복잡도: O(log(n))
모든 노드의 균형 인수가 ±1 이하이면 AVL 트리이다.
균형 인수(balance factor)? 왼쪽 서브 트리의 높이 - 오른쪽 서브 트리의 높이
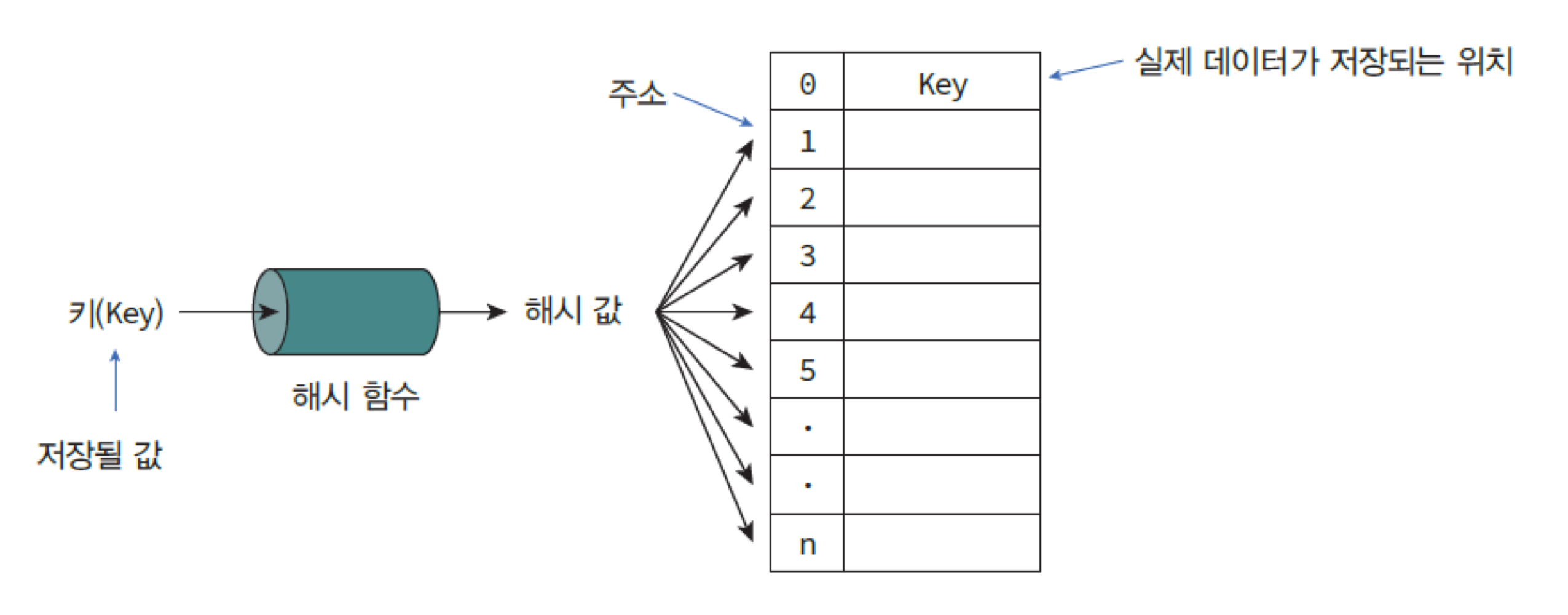
✍️ 해싱(hashing)
해싱(hashing)이란? 키 값에 대한 산술적 연산에 의해 테이블의 주소를 계산하여 항목에 접근
해시 함수(hash function)? 탐색키를 입력받아 해시 주소(hash address) 생성, 이 해시 주소가 배열로 구현된 해시 테이블(hash table)의 인덱스이다.
서로 다른 탐색키를 입력받는데 같은 인덱스일 경우가 발생한다.
즉, 서로 다른 두 개의 탐색키 k1과 k2에 대하여 h(k1) = h(k2)인 경우를 충돌(collision)이라고 한다.
좋은 해시 함수의 조건
- 충돌이 적어야 한다.
- 해시 함수 값이 해시 테이블의 주소 영역 내에서 고르게 분포되어야 한다.
- 계산이 빨라야 한다.
일반적으로 해시 함수는 제산 함수를 사용한다.
충돌을 해결하기 위해서 3가지 방법이 있다.
🔍 선형조사법
선형조사법이란? 충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장
비어있는 공간이 나올 때까지 계속 조사하여 비어있는 공간에 저장한다.
But, 실제 저장되어야 할 공간에 다른 데이터가 저장되는 즉, 자기 자신의 자리를 남에게 뺏기는 경우가 발생한다.
🔍 이중해싱법(double hashing)
이중해싱법(double hashing)이란? 오버플로우가 발생하면 원 해시함수와 다른 별개의 해시 함수 사용
🔍 체이닝
체이닝이란? 각 버켓에 삽입과 삭제가 용이한 연결 리스트 할당
