9장 : 웹 크롤러 설계
웹 크롤러는 몇 개의 웹 페이지에서 시작하여, 링크를 따라가며 새로운 콘텐츠를 수집
- 크롤러가 이용되는 곳
- 검색 엔진 인덱싱 : 웹 페이지를 모아 검색엔진을 위한
로컬 인덱스를 생성
ex) 구글봇 - 구글 검색엔진이 사용하는 웹 크롤러 - 웹 아카이빙 : 나중에 사용할 목적으로 장기보관을 위해 웹에서 정보를 모으는 절차
- 웹 마이닝 : 인터넷에서 유용한 지식을 도출해내는 것
- 웹 모니터링 : 저작권, 상표권이 침해되는 사례를 모니터링할 수 있음
1단계 : 문제 이해 및 설계 범위 확정
- 웹에는 수십억 개의 페이지가 존재하므로 규모 확장성을 고려하여 설계하자
- 비정상적 입력이나 환경에 잘 대응하도록 안정적으로 설계하자
- 수집 대상 웹 사이트에 짧은 시간 동안 너무 많은 요청을 보내지 말자
- 새로운 형태의 콘텐츠를 지원하기 쉽도록 확장성있게 설계하자
2단계 : 개략적 설계안 제시 및 동의 구하기
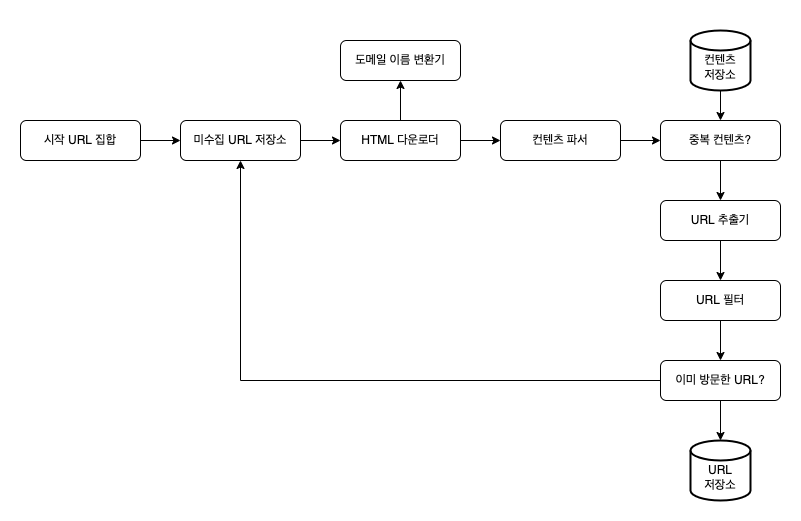
- 시작 URL 집합 : 크롤링을 시작하는 출발점으로, 크롤러가 최대한 많은 링크를 탐색할 수 있도록 하는 URL을 고르자
- 일반적으로, 전체 URL 공간을 작은 부분집합으로 나눈다
ex) 주제별로 URL 공간을 세분화하여 각각 다른 시작 URL 을 사용
- 일반적으로, 전체 URL 공간을 작은 부분집합으로 나눈다
- 미수집 URL 저장소 : 다운로드 할 URL을 저장 및 관리하는 컴포넌트 (FIFO 큐)
- HTML 다운로더 : 인터넷에서 웹 페이지 다운로드하는 컴포넌트
- 도메인 이름 변환기 : 웹페이지를 다운받기 위해 URL을 IP주소로 변환하는 절차를 담당
- 콘텐츠 파서 : 웹 페이지 다운 시 파싱, 검증 절차를 거쳐야 함
- 중복 콘텐츠인가? : 이미 시스템에 저장된 콘텐츠임을 알아내기 위해 웹 페이지의 해시값을 비교하여 중복 콘텐츠를 1번만 저장하도록 함
- 콘텐츠 저장소 : HTML 문서 보관하는 시스템
- URL 추출기 : HTML 페이지를 파싱하여 링크를 골라내는 역할
- URL 필터 : 특정 콘텐츠 타입/확장자를 갖는 URL을 크롤링 대상에서 배제하는 역할
- 이미 방문한 URL : 블룸 필터나 해시테이블로 이미 방문한 URL이나 미수집 URL 을 추적할 수 있게 함
* 블룸 필터(Bloom filter)는 원소가 집합에 속하는지 여부를 검사하는데 사용되는 확률적 자료 구조 - URL 저장소 : 이미 방문한 URL 보관하는 저장소
[웹 크롤러 작업 흐름]
- 시작 URL들을 미수집 URL 저장소에 저장하고
- 미수집 URL 저장소에 있는 URL들을 HTML 다운로더가 가져감
- HTML 다운로더는 도메인 이름 변환기를 사용해 IP 주소를 알아낸 후, 웹페이지를 다운 받음
- 콘텐츠 파서는 다운한 HTML 페이지를 파싱해서 올바른 페이지인지 검증
- 파싱과 검증이 끝나면, 중복 콘텐츠인지 확인하는 작업 수행
- 해당 페이지가 이미 콘텐츠 저장소에 있는지 확인하고, 있다면 버리고 / 없다면 저장소에 저장하고 URL 추출기로 전달
- URL 추출기는 해당 페이지에서 링크를 골라냄
- 골라낸 링크를 URL 필터로 전송
- 필터링 후 남은 URL만 중복 URL 판별 시작
- URL 저장소에 보관되어 있다면 버리고, 없다면 URL 저장소 + 미수집 URL 저장소에 저장
3단계 : 상세 설계
- 크롤링 프로세스는 페이지(노드) + 하이퍼링크(엣지) 로 구성된 방향성 그래프로 이루어진 거대한 웹을 탐색하는 과정
→ 따라서 그래프 탐색에 사용되는 BFS, DFS 알고리즘을 적용할 수 있음
하지만, DFS는 깊이를 가늠할 수 없으므로 보통 BFS 를 사용
- 이 설계법의 문제
- 한 페이지에서 나오는 많은 링크들이 같은 서버로 돌아감
ex) naver.com -> naver.com/page1 -> naver.com/page1/1
따라서, 크롤러가 같은 호스트에 속한 많은 링크를 다운받느라 바빠지고, 이 링크들을 병렬로 처리하는 경우에는 해당 페이지 서버가 과부하에 걸림
→ 이 경우,예의 없는크롤러로 간주됨 - 표준 BFS 알고리즘은 URL간에 우선순위를 두지 않음
따라서, 모든 웹페이지를 공평하게 대우하는데 페이지 순위 / 사용자 트래픽 / 업데이트 빈도에 따라 처리 우선순위를 구별해야 한다.
- 한 페이지에서 나오는 많은 링크들이 같은 서버로 돌아감
→ 이 문제는 미수집 URL 저장소로 해결가능하다
-
결국 첫번째 문제는
예의와 관련된 문제이다.- 수집 대상 서버로 짧은 시간 안에 너무 많은 요청을 보내는 것은
무례한일이며, DoS 공격으로 간주될 때도 있다 - 예의바른 크롤러는, 동일 웹사이트에 대해 한 번에 한 페이지만 요청해야 한다.
같은 웹 페이지를 다운받는 태스크는 시간차를 두고 실행하면 된다.
→ <웹 사이트의 호스트명 + 다운로드 수행하는 작업 스레드> 사이의 관계 유지를 통해 요구사항 만족 가능
다운로드 스레드는 별도의 FIFO 큐를 가지고 있음!
- 큐 라우터 : 같은 호스트에 속한 URL은 언제나 같은 큐로 가도록 보장하는 역할
- 매핑 테이블 : 호스트 이름 + 큐 사이의 관계 보관
호스트: naver.com, 큐: b1
호스트: apple.com, 큐: b2 - 큐 선택기 : 큐를 순회하면서 큐에서 URL을 꺼내서, 해당 URL을 다운로드하도록 지정된 작업스레드에 전달
- 작업 스레드 : 전달된 URL을 다운로드하는 작업 수행
- 수집 대상 서버로 짧은 시간 안에 너무 많은 요청을 보내는 것은
-
두번째 문제는
우선순위와 관련된 문제이다.- 순위 결정 장치 : URL을 입력받아 우선순위 계산
- 큐 : 우선순위별로 큐가 하나씩 할당되며, 우선순위가 높을 수록 선택될 확률도 높앚미
- 큐 선택기 : 임의 큐에서 처리할 URL을 꺼내는 역할 담당하며, 순위 높은 큐일수록 자주 꺼내도록 설계되어 있음
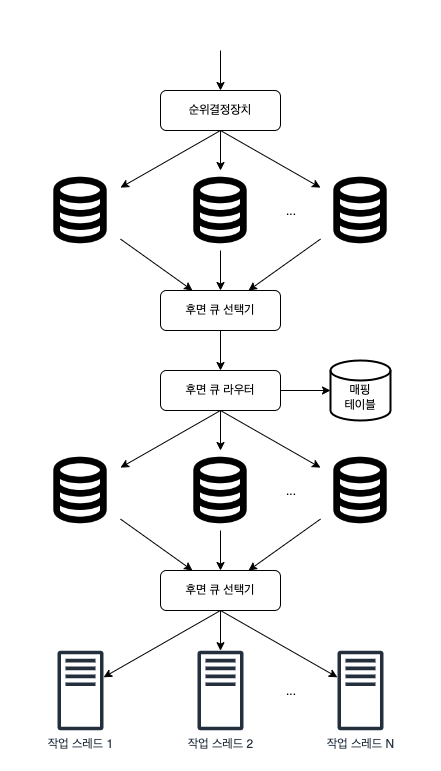
-
결국 전면 큐에서는 우선순위를 먼저 결정하고, 후면 큐에서 크롤러가 예의바르게 동작하도록 한다.
-
신선도 : 웹 페이지는 수시로 변경되므로, 이미 다운로드 했더라도 주기적으로 재수집할 필요성이 있음
하지만, 모든 URL을 재수집하는 것은 많은 시간과 자원이 필요하므로, 웹 페이지 변경 이력을 활용하거나 / 우선순위를 활용해서 중요 페이지를 자주 재수집한다 -
지속성 저장장치 : 대부분의 URL 은 디스크에 두지만, IO 비용을 줄이기 위해 메모리 버퍼에 큐를 두어
10장 : 알림 시스템 설계
이번장의 목표 : iOS/안드로이드 푸시 알림, SMS 메시지, 이메일을 지원하는 알림 시스템의 개략적 설계안을 그려보는 것
- 알림유형별 지원방안을 파악한다.
- iOS / 안드로이드 푸시 알림 : 알림 제공자, APNS/FCM, iOS 단말/안드로이드 단말
- 알림 제공자 : 알림요청을 만들어서 APNS로 보내는 주체
- 알림요청 : 단말토큰 (알림요청 보내는데 필요한 고유 식별자)
- 페이로드 : 알림내용을 담은 JSON 딕셔너리
- APNS : 애플푸시 알림 서비스로, 푸시 알림을 iOS 장치로 보내는 역할
- iOS 단말 : 푸시 알림을 수신하는 사용자 단말
- 알림 제공자 : 알림요청을 만들어서 APNS로 보내는 주체
- SMS 메시지 : 제3사업자의 서비스 이용
- 이메일 : 상용 이메일 서비스 or 고유 이메일 서버 구축
<개략적 설계안>
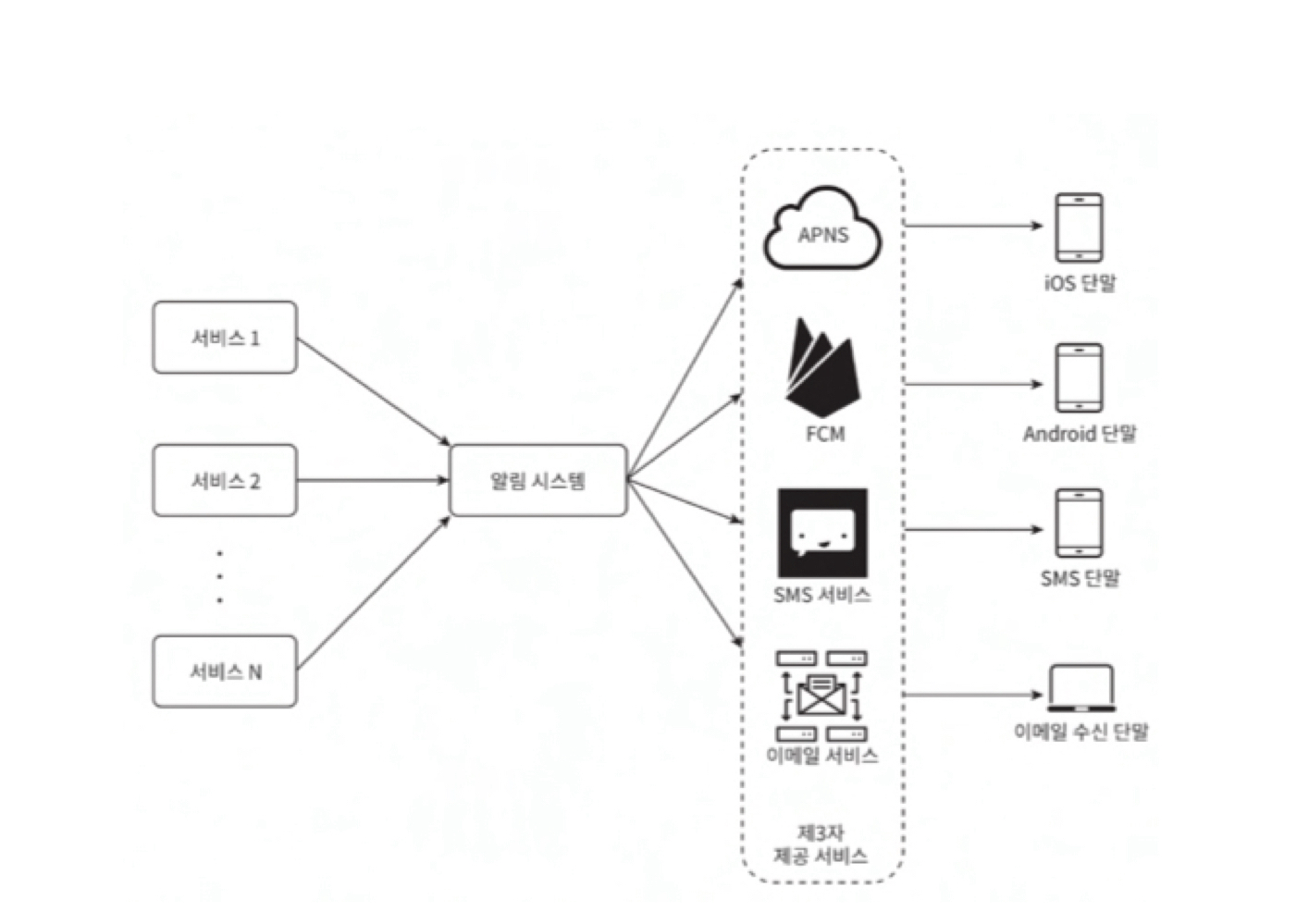
-
제 3의 서비스는 사용자에게 알림을 실제로 전달하는 역할을 하며, 제3자 서비스와의 통합을 진행할 때는
확장성을 고려해야 한다 = 쉽게 새로운 서비스 통합 및 기존 서비스 제거가 가능해야 한다.
ex) 중국에서는 FCM을 사용할 수 없으므로 제이푸시와 같은 다른 서비스를 사용해야 함 -
이 설계의 문제점
- SPOF : 알림 시스템 서버가 1개뿐
- 규모 확장성 : 한대의 서비스로 푸시 알림과 관련된 모든 것을 처리하니까, DB나 캐시 등 중요 컴포넌트 규모를 개별적으로 늘릴 방법이 없다.
- 성능 병목 : 알림을 처리하고 보내는 것은 자원을 많이 필요로 하는 작업이므로, 한 서버로 처리하면 사용자 트래픽이 몰려 과부하 상태가 될 수 있음
<개선된 개략적 설계안>
- DB와 캐시를 알림 시스템의 주 서버에서 분리
- 알림 서버를 증설하고 자동으로 수평적 규모 확장이 이루어지도록
- 메시지 큐를 이용해 시스템 컴포넌트 사이의 강한 결합을 끊음
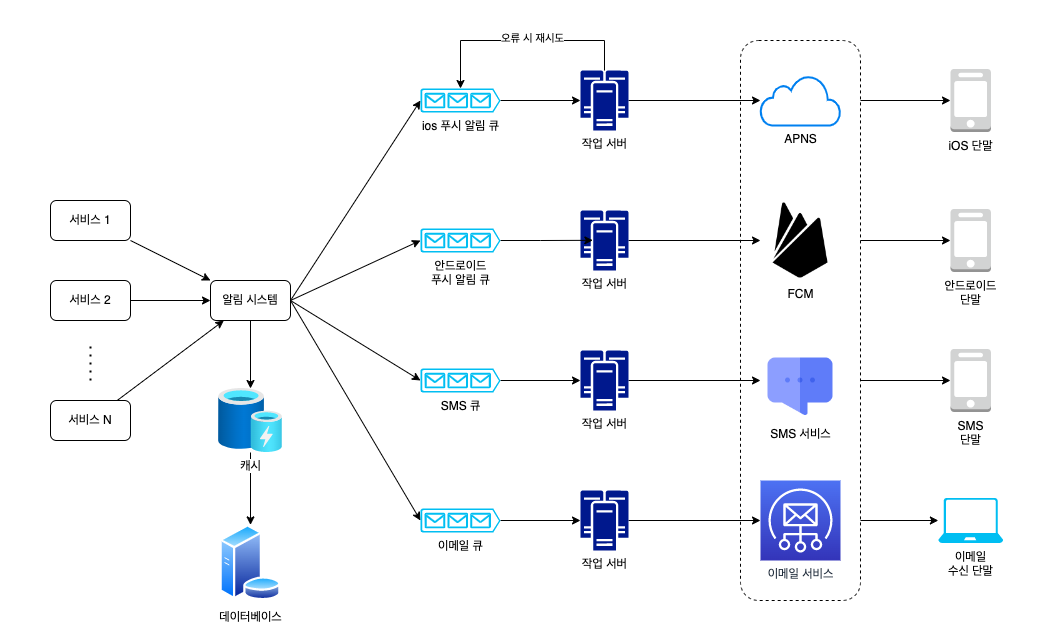
- 알림 서버 : 알림 서버는 알림 데이터를 메시지 큐에 넣는데, 이 설계안의 경우 하나 이상의 메시지 큐를 사용하므로 병렬 처리가 가능
- 캐시 : 사용자 정보, 단말 정보, 알림 템플릿 등을 캐시
- 메시지 큐 : 시스템 컴포넌트 간 의존성을 제거하려고 사용, 다량의 알림 전송되어야 하는 경우를 대비한 버퍼 역할
- 알림 시스템은 제3자 서비스에 의존성을 갖게 되고, 제 3자서비스에 장애가 발생하면 알림 서버가 보내는 알림데이터가 유실될 수 있음
- 메시지큐가 들어가면 제 3자 서비스가 죽더라도 알림 시스템이 보내는 알림은 큐에 저장되기 때문에 정상적인 요청이 가능하다
3단계
-
안정성
- 데이터 손실 방지 : 알림데이터를 DB에 보관하고, 재시도 메커니즘을 구현해야 한다.
ex) 알림 로그 DB 유지 - 알림 중복 전송 방지 : 같은 알림이 여러번 반복되는 것을 막는다. 알림도착 시 이벤트ID를 검사하여 본 적 있는 이벤트인지 살피고, 중복된 경우 버림
- 데이터 손실 방지 : 알림데이터를 DB에 보관하고, 재시도 메커니즘을 구현해야 한다.
-
추가로 필요한 컴포넌트
- 알림 템플릿 : 인자나 스타일, 추적 링크를 조정하기만 하면 사전에
지정한 형식에 맞춰 알람을 만들어내는 틀 / 전송될 알림형식을 일관성 있게 유지 가능하며 알림 작성에 드는 시간 절약 - 알림설정 테이블에 알림 설정 항목 저장
- 전송률 제한 : 한 사용자가 받을 수 있는 알림 빈도 제한
- 재시도 방법 : 제 3자 서비스가 알림전송에 실패하면, 해당 알림을 재시도 전용 큐에 넣음
- 푸시 알림과 보안 : iOS, 안드로이드의 경우 알림 전송 API가 appKey와 appSecret을 사용하여 보안을 유지함. 따라서 인증된 클라이언트만 알림 전송 가능
- 큐 모니터링 : 알림 시스템을 모니터링 할 때 큐에 쌓인 알림 개수를 보고, 그에 맞게 작업 서버 증설
- 이벤트 추적 : 클릭율, 알림 확인율과 같은 이벤트를 추적하고 데이터를 분석하는 서비스와 통합
- 알림 템플릿 : 인자나 스타일, 추적 링크를 조정하기만 하면 사전에
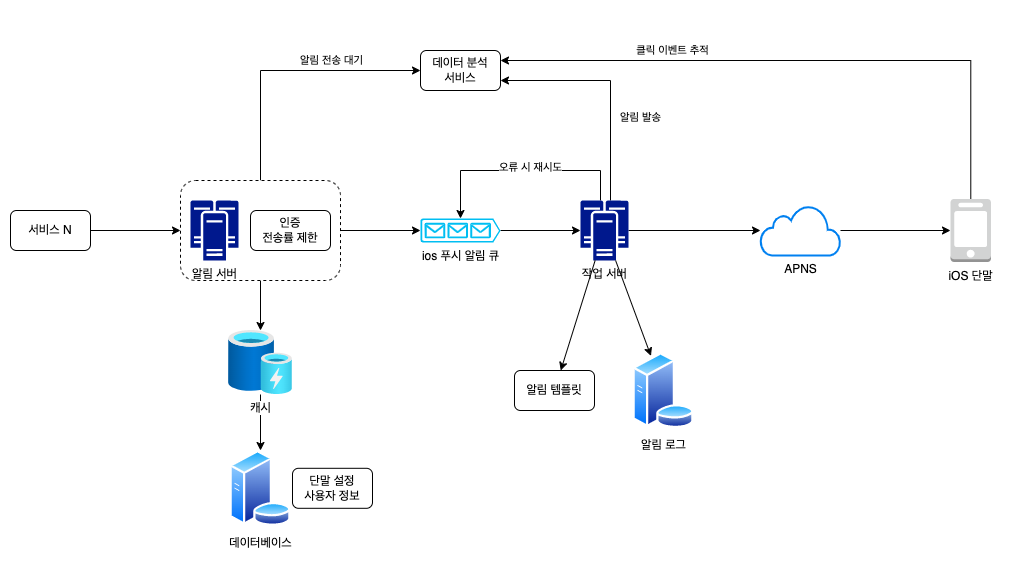
- 재시도 기능 추가
- 전송 템플릿을 사용하여 알림 생성 과정 단순화
- 모니터링, 추적 시스템 추가
4단계
- 안정성 : 메시지 전송 실패율 낮추기 위해, 안정적인 재시도 메커니즘 도입
- 보안 : 인증된 클라이언트만 알림 전송하도록 appKey, appSecret 사용
- 이벤트 추적 및 모니터링 : 알림 생성 후 전송까지의 과정 추적, 시스템 상태 모니터링하기 위해 알림전송의 각 단계마다 이벤트를 추적하고 모니터링하는 시스템 통합
- 사용자 설정 : 사용자가 알림 수신 설정 조정
- 전송률 제한 : 사용자에게 알림 전송 빈도를 제한

되면 한다