🧐 Similarity algorithms
유사도(Similarity)란 두 데이터가 얼마나 유사한 지를 나타내는 척도이다.
1. Cosine Similarity


코사인 유사도(Cosine Similarity)는 두 벡터가 이루는 각도를 통해 유사도를 측정하는 방식이다. 두 벡터가 이루는 각이 작을 수록 유사도가 높고, 각이 클수록 유사도가 작다. 따라서 이 방식은 벡터의 크기를 고려하고 싶지 않을 때 사용할 수 있다.
-1에서 1사이의 값을 가지며, -1은 서로 완전히 반대되는 경우, 0은 서로 독립적인 경우, 1은 서로 완전히 일치하는 경우를 의미한다.
2. Pearson Similarity


피어슨 유사도(Pearson Similarity)는 두 변수 X 와 Y 간의 선형 상관 관계를 계량화한 수치다. 특정 인물의 점수 기준이 극단적으로 너무 낮거나 높은 경우 유사도에 큰 영향을 주기 때문에, 이를 막기 위해 상관계수를 사용한다.
값의 범위는 -1과 1 사이이다. -1은 완전히 다른 경우, 1은 완전히 유사한 경우를 의미한다.
🙉 Practice in Neo4j!
1) Consine Similarity 계산하기
RETURN gds.alpha.similarity.cosine([3,8,7,5,2,9], [10,8,6,6,4,5]) AS similarity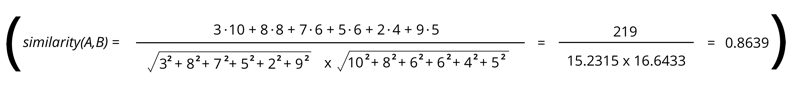
-> 결과 : 0.8638935626791597
2) 데이터 생성
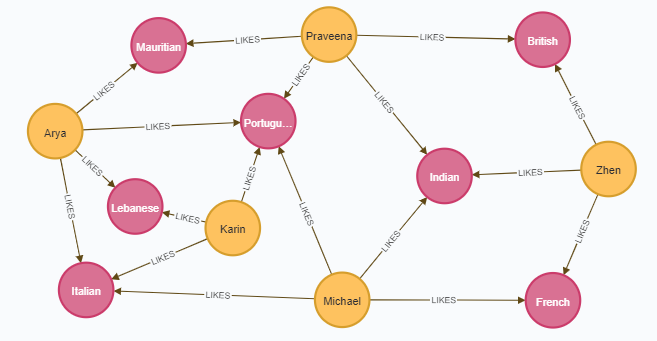
CREATE (french:Cuisine {name:'French'})
CREATE (italian:Cuisine {name:'Italian'})
CREATE (indian:Cuisine {name:'Indian'})
CREATE (lebanese:Cuisine {name:'Lebanese'})
CREATE (portuguese:Cuisine {name:'Portuguese'})
CREATE (british:Cuisine {name:'British'})
CREATE (mauritian:Cuisine {name:'Mauritian'})
CREATE (zhen:Person {name: "Zhen"})
CREATE (praveena:Person {name: "Praveena"})
CREATE (michael:Person {name: "Michael"})
CREATE (arya:Person {name: "Arya"})
CREATE (karin:Person {name: "Karin"})
CREATE (praveena)-[:LIKES {score: 9}]->(indian)
CREATE (praveena)-[:LIKES {score: 7}]->(portuguese)
CREATE (praveena)-[:LIKES {score: 8}]->(british)
CREATE (praveena)-[:LIKES {score: 1}]->(mauritian)
CREATE (zhen)-[:LIKES {score: 10}]->(french)
CREATE (zhen)-[:LIKES {score: 6}]->(indian)
CREATE (zhen)-[:LIKES {score: 2}]->(british)
CREATE (michael)-[:LIKES {score: 8}]->(french)
CREATE (michael)-[:LIKES {score: 7}]->(italian)
CREATE (michael)-[:LIKES {score: 9}]->(indian)
CREATE (michael)-[:LIKES {score: 3}]->(portuguese)
CREATE (arya)-[:LIKES {score: 10}]->(lebanese)
CREATE (arya)-[:LIKES {score: 10}]->(italian)
CREATE (arya)-[:LIKES {score: 7}]->(portuguese)
CREATE (arya)-[:LIKES {score: 9}]->(mauritian)
CREATE (karin)-[:LIKES {score: 9}]->(lebanese)
CREATE (karin)-[:LIKES {score: 7}]->(italian)
CREATE (karin)-[:LIKES {score: 10}]->(portuguese)3) 각각 노드 쌍들의 코사인 유사도 측정
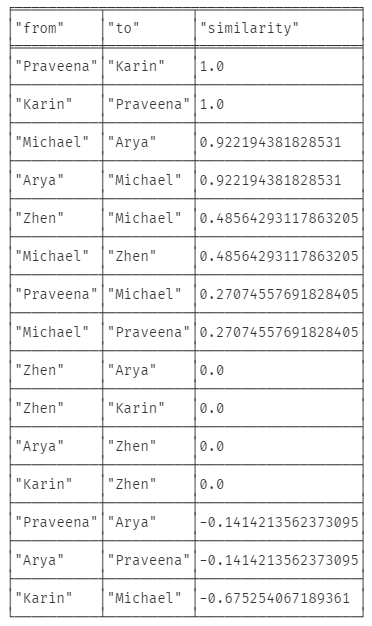
MATCH (p:Person), (c:Cuisine)
OPTIONAL MATCH (p)-[likes:LIKES]->(c)
WITH {item:id(p), weights: collect(coalesce(likes.score, gds.util.NaN()))} AS userData
WITH collect(userData) AS data
CALL gds.alpha.similarity.cosine.stream({data: data})
YIELD item1, item2, count1, count2, similarity
RETURN gds.util.asNode(item1).name AS from, gds.util.asNode(item2).name AS to, similarity
ORDER BY similarity DESC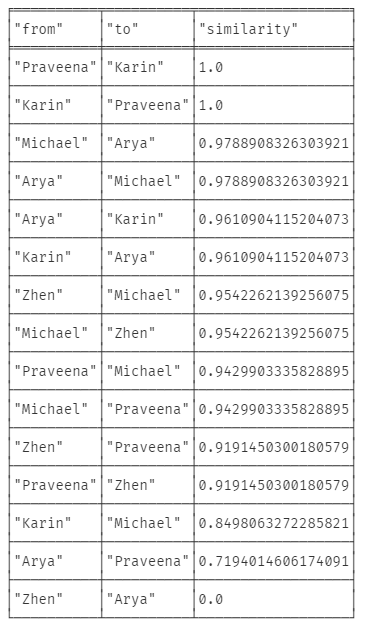
4) 각각 노드 쌍들의 피어슨 유사도 측정
MATCH (p:Person), (c:Cuisine)
OPTIONAL MATCH (p)-[likes:LIKES]->(c)
WITH {item:id(p), weights: collect(coalesce(likes.score, gds.util.NaN()))} AS userData
WITH collect(userData) AS data
CALL gds.alpha.similarity.pearson.stream({data: data})
YIELD item1, item2, count1, count2, similarity
RETURN gds.util.asNode(item1).name AS from, gds.util.asNode(item2).name AS to, similarity
ORDER BY similarity DESC