
🤔 동시성 이슈란?
여러 스레드가 동시에 같은 인스턴스의 필드 값을 변경 하면서 발생하는 문제이다. 만약 재고가 100개인 물품이 있을 때 다수의 스레드에서 한번에 재고를 감소하는 요청이 들어오면 어떻게 될까?
테스트는 Java17, SpringBoot 3.2.0, MySQL, SpringDataJpa를 사용해 진행했다.
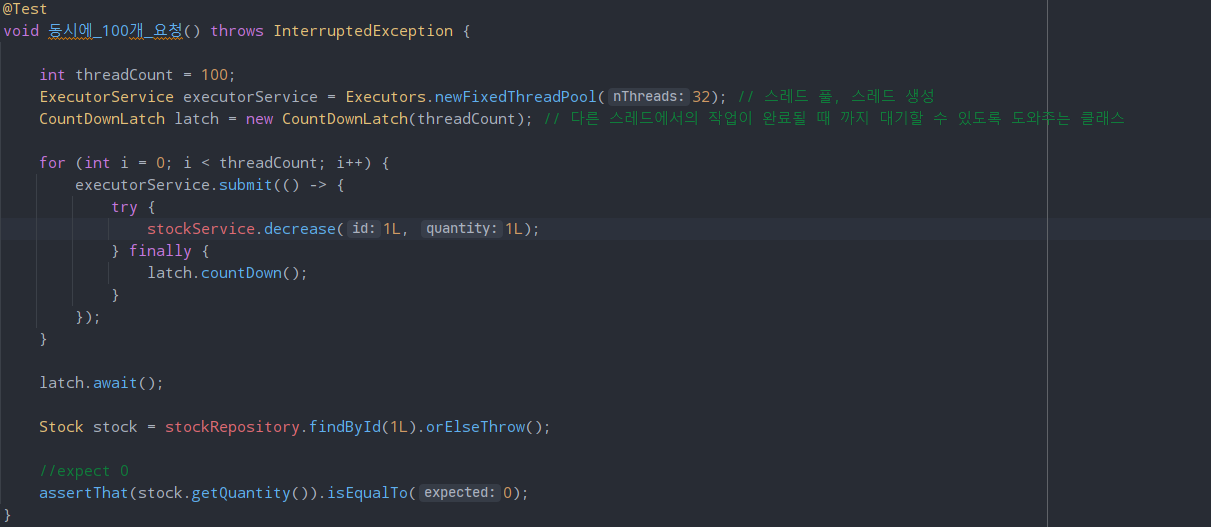
설명에 앞서 @BeforeEach를 사용해 id가 1이고 quantity가 100인 Stock 객체를 생성하고 테스트를 진행했다.
- CountDownLatch : 스레드가 작업을 완료하면 바로 다음 코드를 실행하지만 다른 스레드의 작업이 완료될 때까지 대기할 수 있도록 도와주는 클래스이다.
- countDown() : CountDownLatch에 파라미터로 넘겨준 숫자에서 -1씩 한다.
- await() : CountDownLatch를 생성할 때 파라미터로 넘겨준 숫자가 0이 될 때까지 대기한다.
따라서, 위 코드는 100개의 스레드를 생성하고 재고 id가 1인 Stock 객체의 quantity를 1씩 동시에 감소시켰다. 예상되는 결과는 id가 1인 Stock 객체의 quantity는 0이었지만 실제 테스트를 진행해 본 결과는 96개였다.
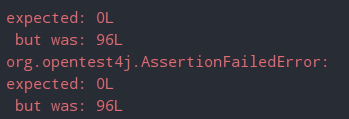
왜 이런 결과가 나왔을까?
이유는 스레드의 작업이 끝나기 전에 다른 스레드에서 작업을 수행했기 때문이다. 예를 들어 스레드 A와 스레드 B가 있고 위의 코드를 실행하면 스레드 A와 스레드 B가 접근한 id가 1인 객체의 quantity는 동일하게 100개이다. 스레드A, 스레드B는 각각 decrease 메서드를 실행했지만 id가 1인 Stock 객체의 quantity는 1개만 감소된 99개일 것이다.
그럼 어떻게 해결하지?
위에서 알아봤듯이 스레드가 동시에 접근하여 발생한 문제이기에 한개의 스레드 작업이 완료되고 다음 스레드가 작업을 수행하도록 만들어주면 된다. 이를 위해 synchronized, Lock, Redis를 사용해 문제를 해결해보자.
🧨 synchronized
java에서 제공하는 synchronized를 사용해 문제를 해결하는 방법이다.
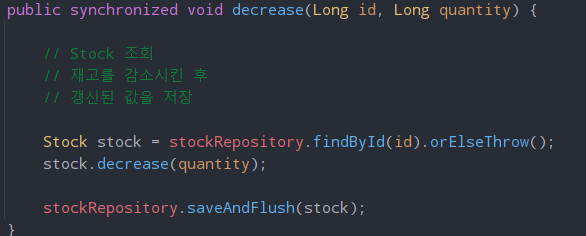
위와 같이 StockService의 decrease 메서드를 수정하고 테스트를 돌리면 테스트가 통과된다. 하지만, synchronized는 치명적인 문제점이 있어 근본적으로 동시성 이슈를 해결하지 못한다.
-
synchronized는 하나의 프로세스에서만 동작한다.
만약 서버가 여러대이고 서로 다른 서버에서 동시에 decrease 메서드에 접근한다면 synchronized는 기능을 발휘할 수 없기에 동시성 문제를 해결할 수 없다.
-
@Transactional애노테이션을 사용하면 트랜잭션이 종료되기 전에 다른 스레드에서 메서드에 접근할 수 있다.트랜잭션이 끝나기 전에 즉, 변경한 데이터가 데이터베이스에 커밋되기 전에 다른 스레드에서 메서드에 접근할 수 있으므로 동시성 문제를 해결할 수 없다.
💡 Lock (MySQL)
Pessimistic Lock (비관적 락)
데이터베이스의 table 또는 row에 락을 걸어 다른 스레드에서 접근하지 못하도록 하여 동시성 이슈를 해결한다.
예를 들어 스레드A, 스레드B가 1번 row에 동시에 접근하는 경우에 스레드A가 1번 row에 접근하고 락을 건다면 스레드B는 1번 row에 접근하지 못한다. 스레드 A의 작업이 모두 끝나고 락을 해제하면 그때서야 스레드 B는 1번 row에 접근할 수 있다.
SpringDataJpa에서는 Pessimistic Lock을 @Lock 애노테이션을 사용해 구현할 수 있다.

repository에서 Stock 조회 메서드를 위와 같이 작성하고 decrease 메서드에서 Stock 객체를 조회할 때 findByIdWithPessimisticLock 메서드를 사용한다. 그 후 테스트를 돌려보면 테스트가 통과한다.
비관적 락은 데이터 정합성을 보장하는 대신에 조회할 때 매번 락을 사용하므로 데이터베이스 부담을 줄 수 있다.
Optimistic Lock (낙관적 락)
스레드에서 데이터에 접근할 때 version을 가지고 접근한다.
스레드A, 스레드B가 동시에 version이 1인 데이터에 접근한 경우 스레드A가 작업을 완료하여 데이터를 변경하면 version은 2로 변경된다. 그 때 스레드B가 가지고 있는 version에 변경이 발생했으므로 스레드B는 새로운 version의 데이터를 조회한다.
SpringDataJpa에서는 Optimistic Lock도 @Lock 애노테이션을 사용해 구현할 수 있다.

조회 메서드를 위와 같이 작성하고 낙관적 락을 사용하기 위해서는 jakarta.persistence의 @Version 애노테이션을 사용해 version 필드를 Stock 객체 필드에 추가해줘야 한다.
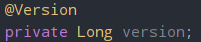
또한, 낙관적 락은 비관적 락이랑 달리 version에 변경이 감지됐을 때 재요청을 하므로 재요청하는 로직도 직접 작성해줘야 한다.
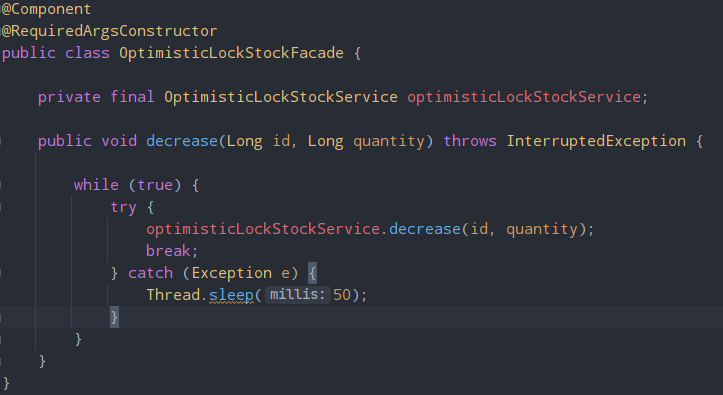
위와 같이 OptimisticLockStockFacade 클래스를 생성하여optimisticLockStockService.decrease(id, quantity) 가 실행될 때까지 재요청한다. 이 때, 예외가 발생하면 Thread.sleep을 사용해 데이터베이스의 부담을 줄여줄 수 있다.
OptimisticLockStockFacade의 decrease 메서드를 사용하여 테스트를 진행하면 테스트는 정상적으로 통과된다.
낙관적 락은 데이터를 조회할 때 Lock을 사용하지 않으므로 비관적 락보다 성능이 좋다. 하지만, version 충돌이 자주 발생하면 낙관적 락보다 성능이 떨어질 수 있다.
Named Lock
별도의 공간에 Lock을 생성하고 반환하여 동시성 이슈를 해결한다. Named Lock은 트랜잭션이 끝날 때 자동으로 반환되지 않기에 반환하는 로직을 직접 구현해줘야 한다.
MySQL의 NamedLock 기능을 사용하기 위해 새로 LockRepository를 만들었다.
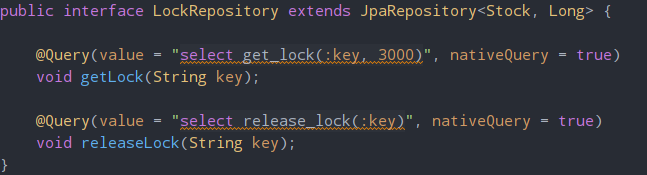
getLock은 락을 얻는 메서드, releaseLock은 락을 반환하는 메서드이다.
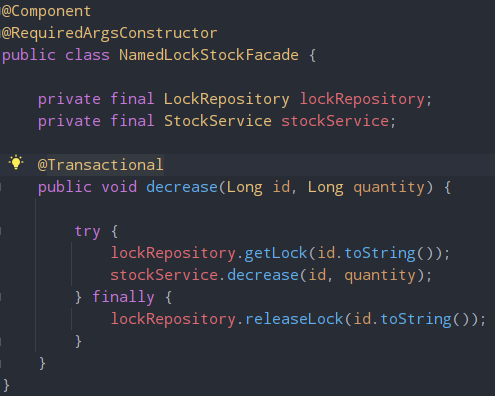
NamedLockStockFacade를 생성하여 락을 얻고, 조회 작업을 마친 후 락을 반납하는 로직을 작성했다.
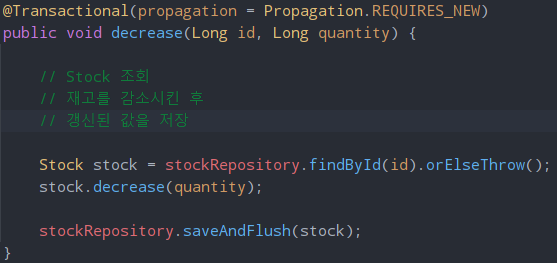
여기서 기존의 stockService의 decrease 메서드에 있던 트랜잭션과 NamedLockStockFacade에 있는 트랜잭션을 분리시켜야했다. NameLock의 작업 순서는 아래와 같다.
- 락을 얻는다.
- 스레드에서 작업을 마친 후 데이터베이스에 변경된 데이터를 commit 한다.
- 락을 반납한다.
기존 코드는 트랜잭션 전파로 인해 NamedLockStockFacade에 걸린 트랜잭션에 stockService의 decrease 트랜잭션이 속하게된다. 이렇게되면 변경된 데이터가 commit 되기 전에 락을 반납해버리기 때문에 데이터 정합성에 문제가 생길 수 있다.
이러한 문제를 해결하기위해 아래와 같이 트랜잭션을 분리했다.
💡 Redis
SpringBoot에서 Redis 기능을 사용하기 위해 build.gradle의 dependencies에 implementation 'org.springframework.boot:spring-boot-starter-data-redis'를 추가해준다.
Lettuce
setnx 명령어를 활용해 분산락을 구현하고, spin lock 방식을 사용하여 동시성 이슈를 해결하기 때문에 redis에 부하를 줄수 있다. 또한, spin lock 방식을 사용하기 때문에 lock을 획득할 때까지 재요청하는 로직을 직접 작성해야 한다.
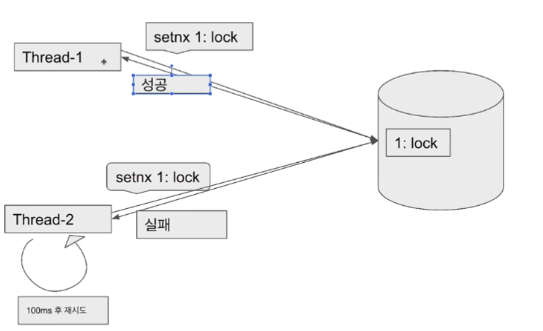
Lettuce 기능을 사용하기 위해 RedisLockRepository를 새로 만들어줬다.
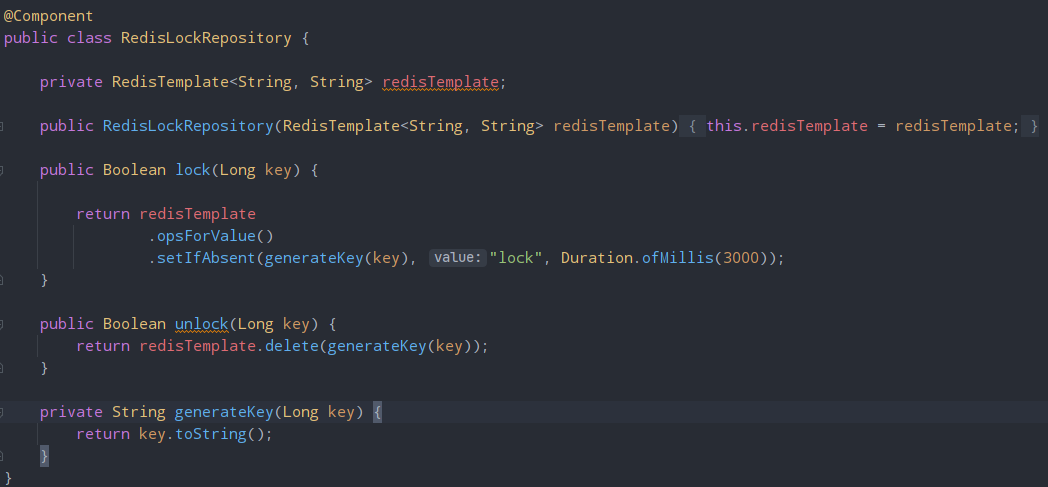
lock 메서드는 key를 이용해 락을 얻는 메서드이고, unlock 메서드는 작업을 완료하고 락을 해제하는 메서드이다.
LettuceLockstockFacade 클래스를 새로 생성하여 Lettuce의 기능을 사용했다.
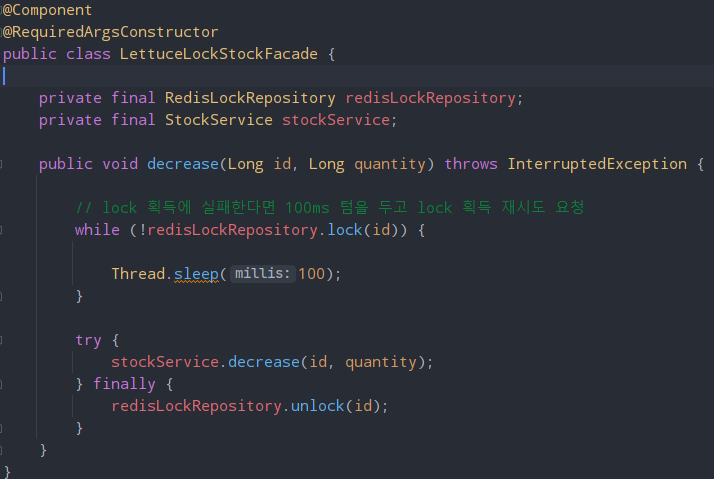
while문을 사용해 락을 얻을 때까지 재요청하는 로직을 구현하고 락을 얻었다면 stockService의 decrease 메서드를 실행시킨다. 그 후 작업이 완료되고 unlock 메서드를 통해 락을 해제한다.
- 락을 얻을 때까지 재요청
redisLockRepository.lock() - 락을 얻었으면 스레드에서 작업 -> 완료
stockService.decrease(id, quantity) - 작업이 완료된 후 락 해제
redisLockRepository.unlock()
장점
1.spring-data-redis를 사용하면 기본으로 설정된 라이브러리이기에 별도의 라이브러리를 사용하지 않아도 된다.
2. 구현이 간단하다.
단점
- spin lock 방식으로 작동하기에 재요청 로직을 직접 구현해야 한다.
- spin lock 방식을 사용하기에 redis에 부하를 줄 수 있다. ->
Thread.sleep을 사용해 부하를 줄여줄 수 있다.
Redisson
spring data redis의 기본 라이브러리는 Lettuce 이기에 별도의 라이브러리를 사용해야 한다.
https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter 에서 버전을 선택후 Gradle 탭을 누르면 의존성 추가 코드가 있다. 복사하여 build.gradle에 추가하자.
Redisson은 pub-sub 기반 Lock을 사용하여 동시성 이슈를 해결한다.
Redisson의 동작 방식을 알아보기 전에 간단히 Redis의 채널에 대해 알아보자.

A는 redis에 접속하여 채널 ch1을 구독한다. B는 A와 같은 redis에 접속하여 채널 ch1에 hello란 메시지와 bye란 메시지를 보낸다.
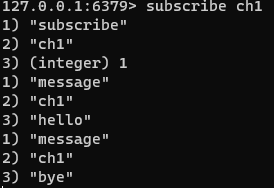
A는 B가 채널 ch1에 보낸 메시지를 확인할 수 있다.
Redisson은 이것을 활용해 스레드A가 작업이 끝나면 채널에 작업이 끝났다는 메시지를 보낸다. 그 때 대기하고 있던 스레드B가 메시지를 확인하고 락을 획득하기 위해 요청을 보낸다.

Redisson 라이브러리의 기능을 사용하기 위해 RedissonLockStockFacade 클래스를 생성했다.
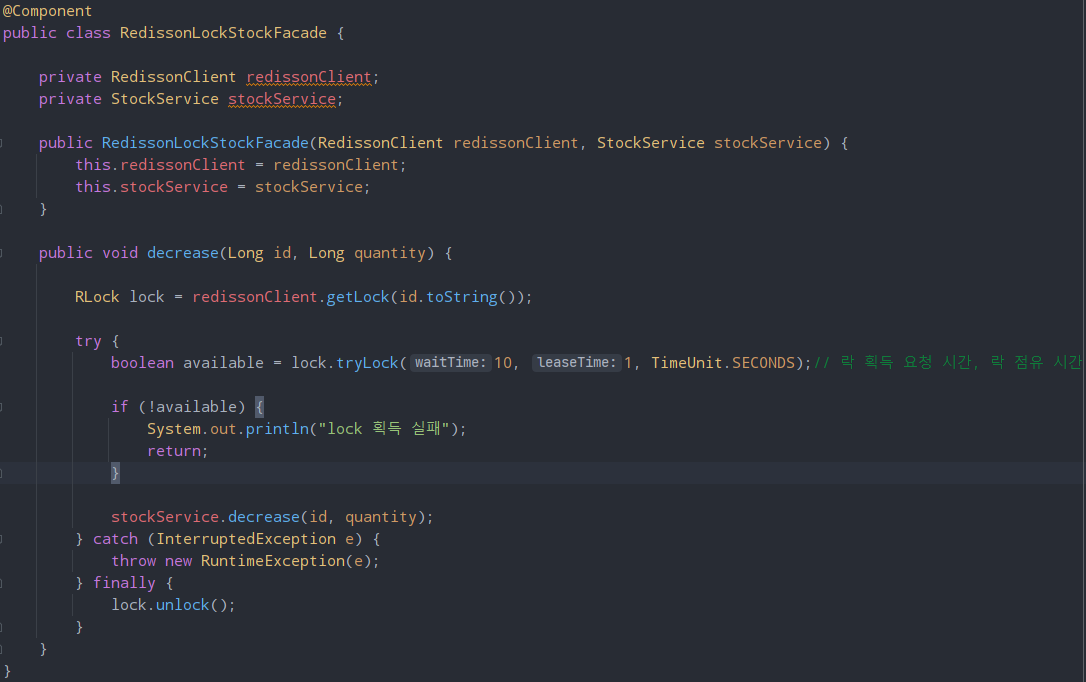
장점
- Redisson은 채널에서 메시지를 확인하고 락 획득 요청을 하기 때문에 redis에 부하가 적다.
단점
- Lettuce에 비해 구현이 복잡하다.
- 별도의 라이브러리를 사용해야 한다.
Redis 정리
-
락 획득 요청 재시도가 필요한 경우는 Redisson을 사용하자.
상품을 주문하는데 유저 A,B가 동시에 itemA를 주문 -> 유저 A가 Lock을 잡고 있다면 유저 B는 기다렸다가 락 획득 요청을 재시도하여 상품을 주문한다. -
락 획득 요청 재시도가 필요 없는 경우는 Lettuce를 사용하자.
유저 A,B가 선착순으로 재고가 1개인 itemA를 동시에 구매하는 경우 -> 먼저 Lock을 선점한 유저의 주문을 완료한다면 다른 유저는 다시 락 요청 재시도를 할 필요가 없다.
🤔 MySQL vs Redis
MySQL- 이미 MySQL을 사용하고 있다면 별도의 비용 없이 사용 가능하다.
- 어느 정도의 트래픽까지는 문제 없이 활용 가능하다.
- Redis 보다는 성능이 좋지 않다.
Redis- 활용중인 Redis가 없다면 별도의 구축 비용과 인프라 관리 비용이 발생한다.
- MySQL보다 성능이 좋다.
현재 환경에 맞게 아키텍쳐를 구현해서 사용하자!!
