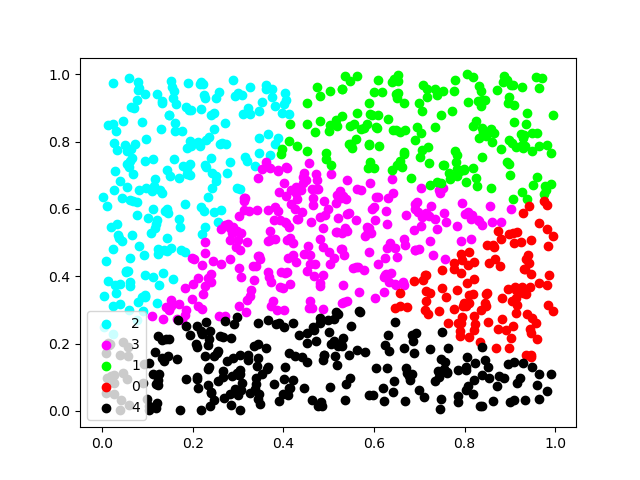
K-Means
주어진 데이터를 지정된 개수(K)의 그룹(Cluster)으로 나누는 알고리즘
주어진 데이터를 가장 잘 그룹화하는 방법을 찾아가면서 수행
순서
Step 1. 임의의 K개의 중심점(Centroids)을 선택
Step 2. 각 데이터를 가장 가까운 중심점에 속한 그룹으로 분류
Step 3. 그룹의 중심점을 새로 계산
Step 4. 새로운 중심점과 기존 중심점이 충분히 일치할 때까지 반복
장단점
장점
알고리즘 구현 난이도 쉬움
다양한 데이터에 활용 가능
단점
그룹의 개수를 사전에 정의해야 함
가중치 및 거리 정의가 필요
개선 포인트
다양한 K값을 갖는 알고리즘은 병렬 수행 가능?
다양한 결과에 대해 최적의 K값은 어떻게 도출?
각 K-Means 결과 :
