Pytorch to ONNX
Docker Container 준비
NVIDIA Docker runtime 설치
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list \
&& sudo apt-get update \
&& sudo apt-get install -y nvidia-docker2 \
&& sudo systemctl restart docker
sudo apt install -y nvidia-container-toolkit \
&& sudo systemctl restart dockerimage 설치
Tags > 21.12-py3
docker pull nvcr.io/nvidia/pytorch:21.12-py3
소스 코드 다운
컨테이너를 생성하기 전 미리 볼륨을 만들어 놓는 것 권장
컨테이너 내부에서 sudo 권한으로 파일을 생성하면 외부에서 관리 힘들어짐
git init \
&& git remote add origin https://github.com/2damin/yolov3-pytorch.git \
&& git pull origin onnx-1.6yolov3-tiny.weights 다운
wget https://pjreddie.com/media/files/yolov3-tiny.weights컨테이너 생성 및 진입
--name 컨테이너 이름
--gpus GPU 연결
-p 호스트와 컨테이너의 포트 연결
-it 대화형 모드로 실행
--rm 종료 후 컨테이너 삭제
-v 호스트 경로와 컨테이너 내 경로를 연결
docker run \
--name yolov3_kitti \
--gpus all \
-p 8888:8888 \
-it \
-v ${PWD}/DockerFile/yolov3-pytorch:/yolov3-pytorch \
-v /home/bert/Downloads/datasets/kitti/kitti_dataset:/yolov3-pytorch/datasets \
nvcr.io/nvidia/pytorch:21.12-py3 /bin/bash
재진입
docker start yolov3_kitti
docker exec -it yolov3_kitti /bin/bash종속성 확인
GPU 확인
nvidia-smi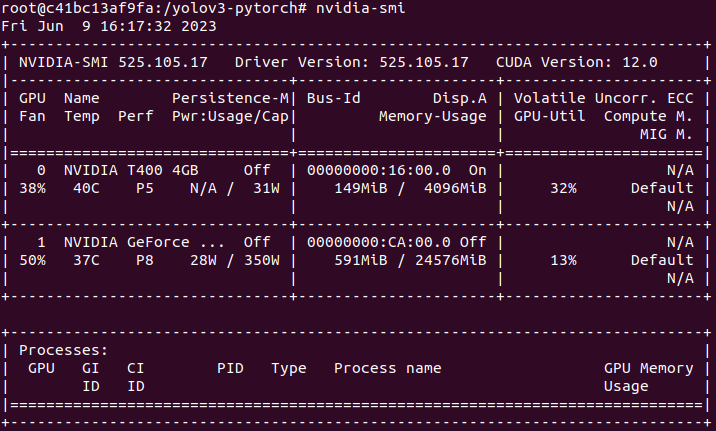
CUDA 확인
nvcc -V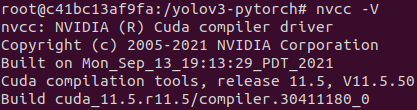
종속성 설치
pip install -r requirements.txt
pip install "opencv-python-headless<4.3"
pip install protobuf==3.20가동
Train kitti
model > yolov3.py : ONNX_EXPORT = False
dataloader > yolodata.py : 데이터 경로 설정
dataloader > yolodata.py
tstl_data class_str :
['left', 'right', 'stop', 'crosswalk', 'uturn', 'traffic_light']
kitti_data class_str : ['Car','Van','Truck','Pedestrian','Person','Cyclist','Tram','Miscellaneous']
python main.py \
--mode train \
--cfg yolov3-tiny_kitti416.cfg \
--gpus 0 \
--pretrained yolov3-tiny.weights \
--output kitti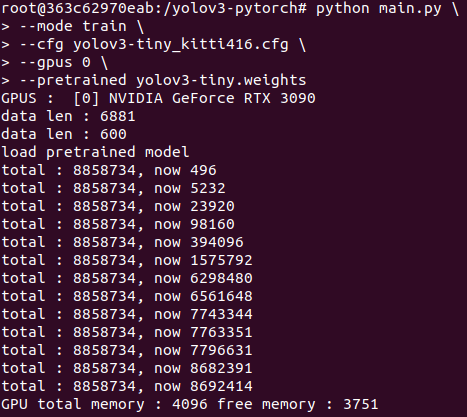
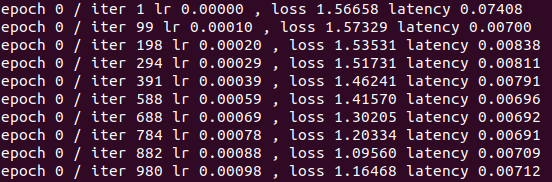
epoch 10
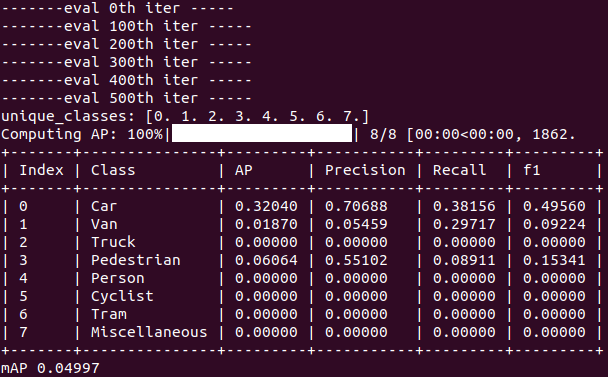
epoch 20
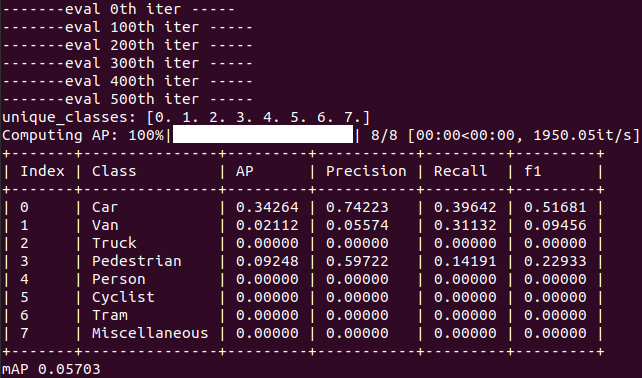
tensorboard
웹에서 localhost:8888으로 접속
tensorboard --logdir=./output/kitti --port 8888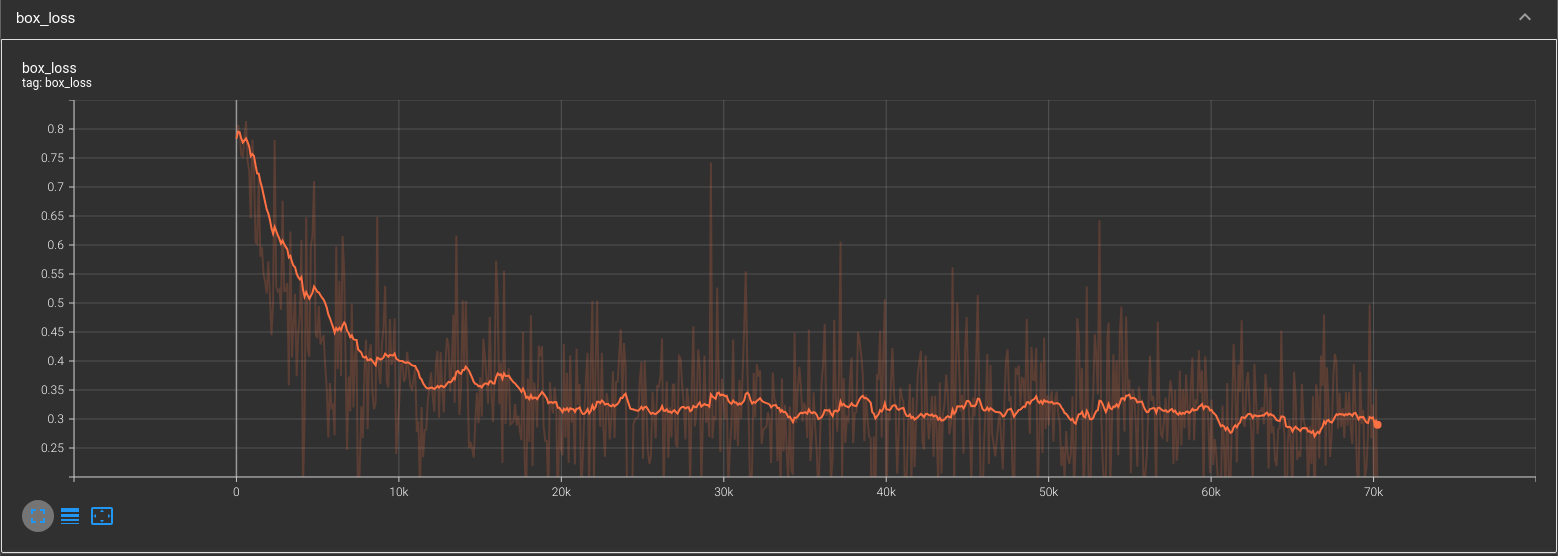
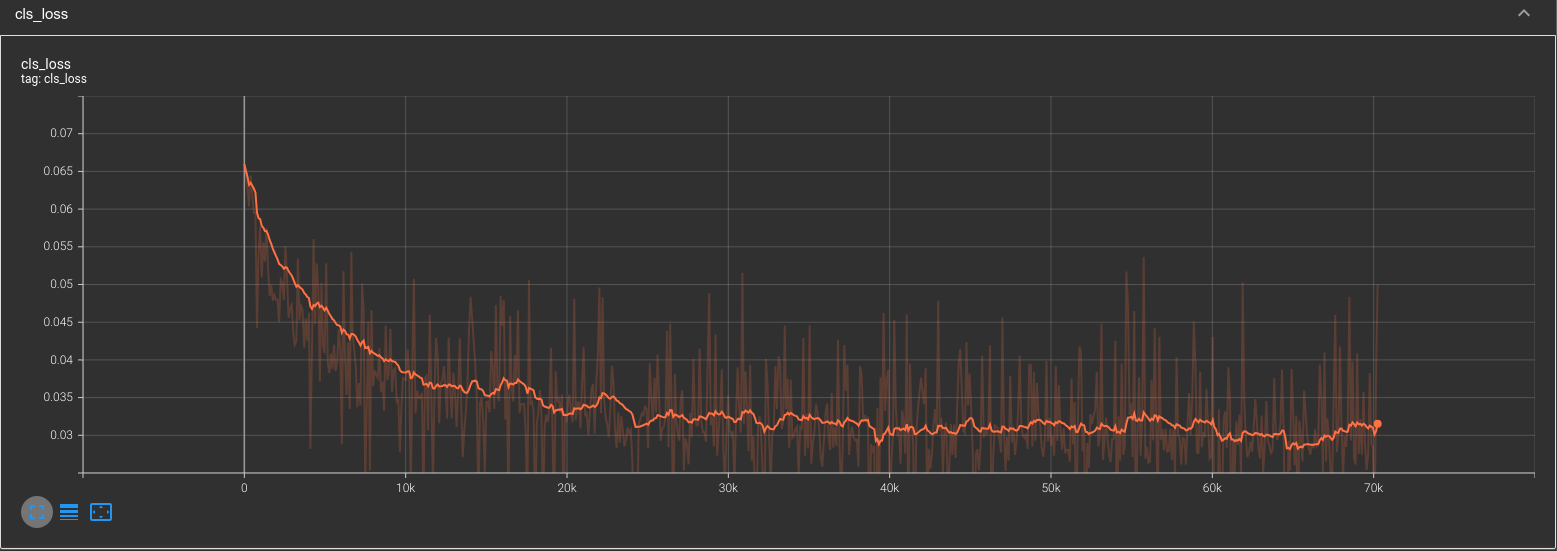
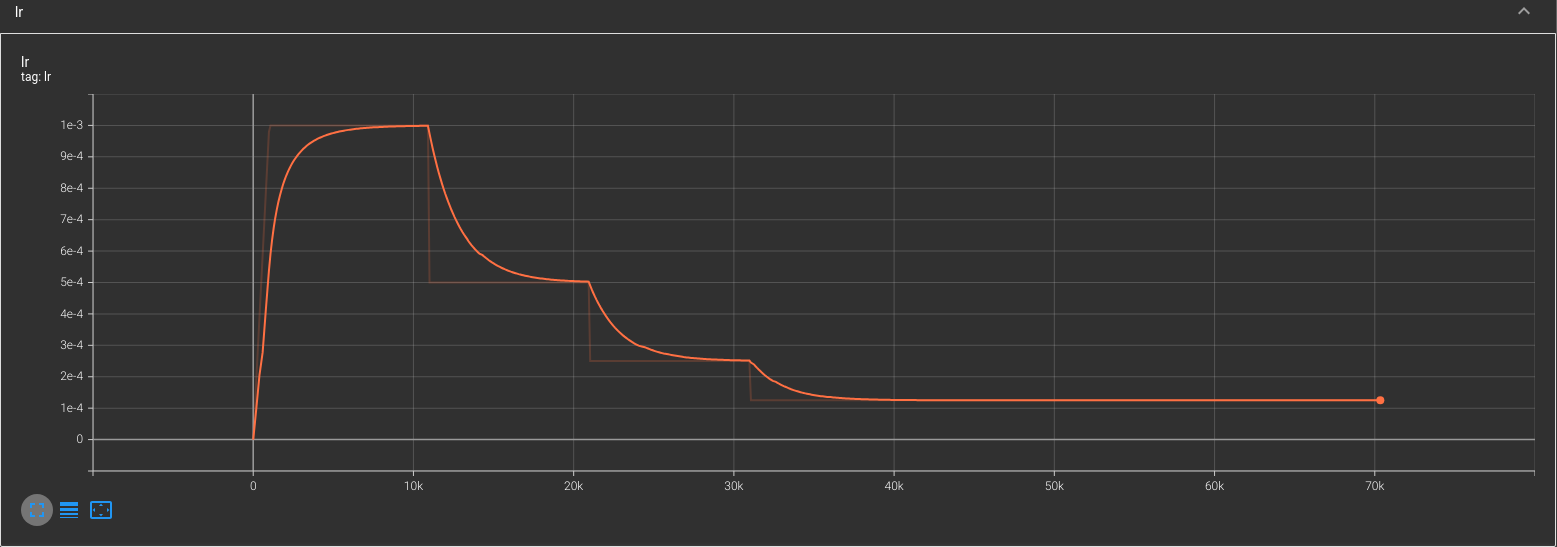
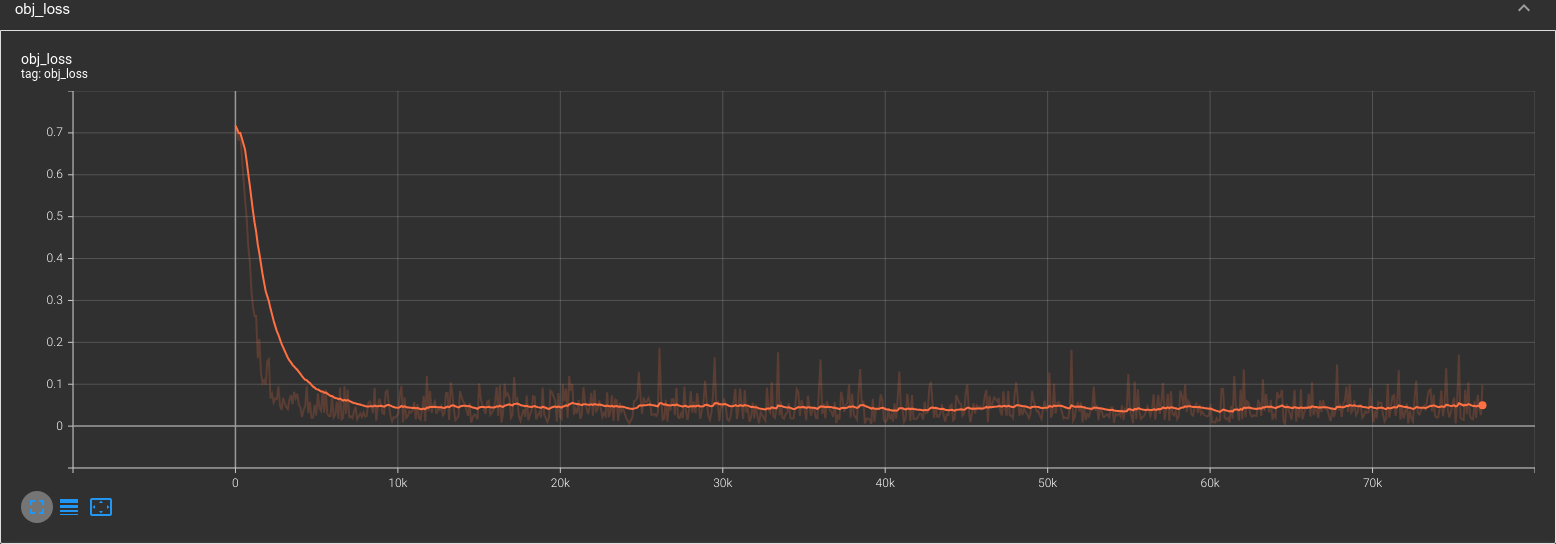
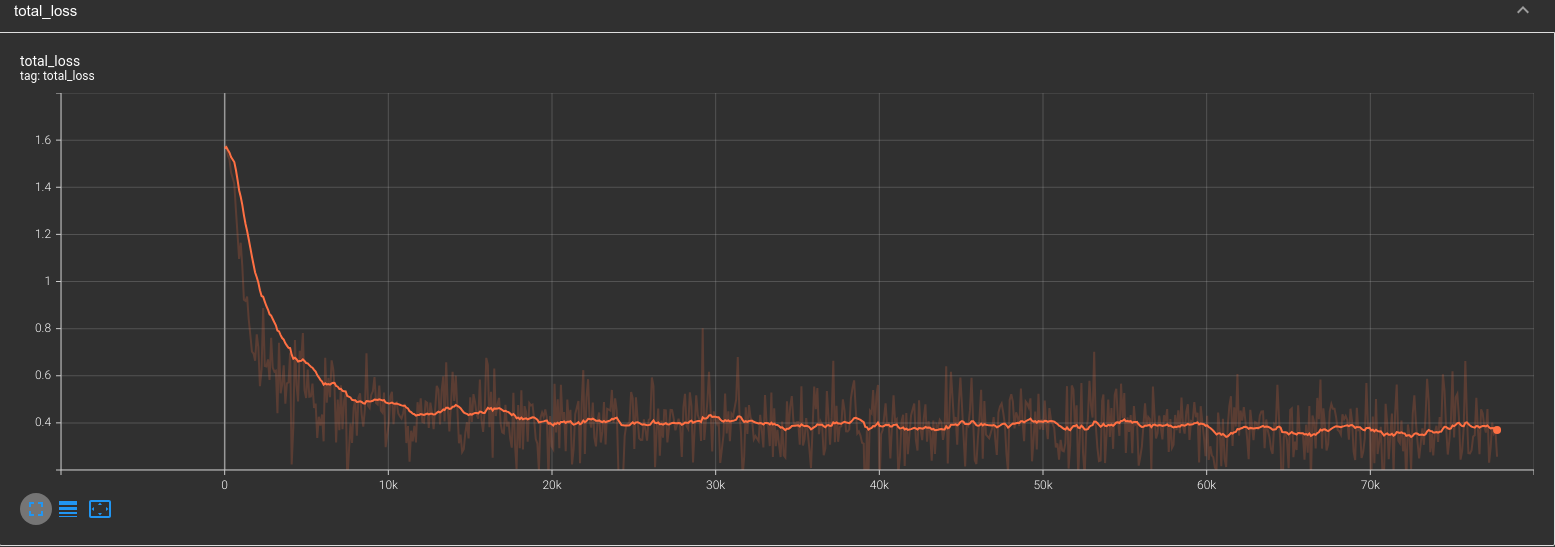
Error
yolov3-tiny_tstl_352.cfg : batch 수 변경(64 16) 후 해결
--gpus 변경 후 배치 원상 복구
RuntimeError: CUDA out of memory.
Tried to allocate 30.00 MiB (GPU 1; 3.81 GiB total capacity;
2.52 GiB already allocated;
25.56 MiB free; 2.56 GiB reserved in total by PyTorch)
If reserved memory is
>> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFEval
python main.py \
--mode eval \
--cfg ./yolov3-tiny_kitti416.cfg \
--gpus 0 \
--checkpoint ./output/sample/model_epoch10.pth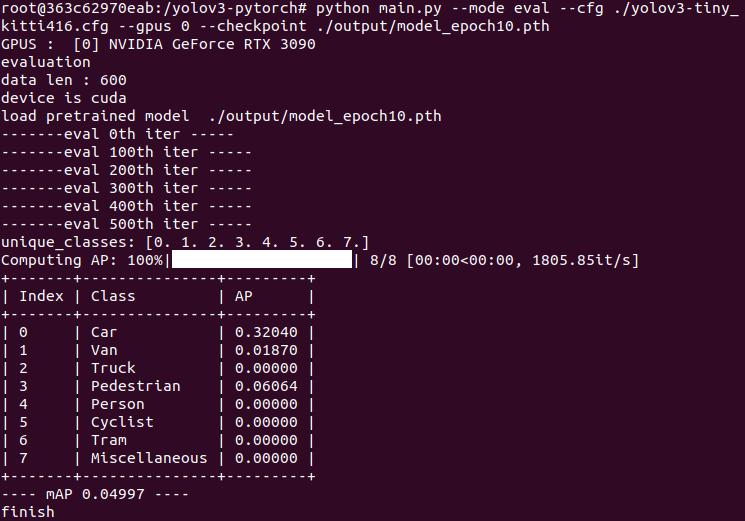
Demo
python main.py \
--mode demo \
--cfg ./yolov3-tiny_kitti416.cfg \
--gpus 0 \
--checkpoint ./output/sample/model_epoch10.pth
--output sample


ONNX
model > yolov3.py : ONNX_EXPORT = True
.weights .onnx 추출
python main.py \
--mode onnx \
--cfg ./yolov3-tiny_kitti416.cfg \
--gpus 0 \
--checkpoint ./output/model_epoch10.pth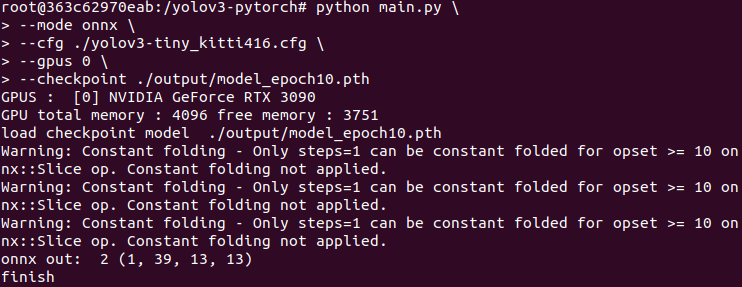
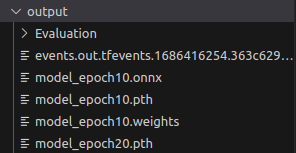
python yolov3_to_onnx.py \
--cfg ../yolov3-pytorch/yolov3-tiny_kitti416.cfg \
--weights ../yolov3-pytorch/output/model_epoch20.weights \
--num_class 8ONNX to TensorRT
TX2에서 진행
해당 하드웨어에 최적화되게 만드는 엔진
