
Executors
Executors는 Executor를 상속 및 구현하고 있는 ExceutorService, ScheduledExecutorService
그리고 같이 사용되는 ThreadFactory, Callable 클래스들을 쉽게 구현할 수 있도록 도와주는 팩토리 메소드와 유틸리티 메소드를 제공하는 클래스이다.
팩토리 메소드들을 통해 자주 사용되는 ExecutorService을 쉽게 사용할 수 있도록 도와준다.
그 중에서 가장 많이 사용되는 4가지 메소드를 살펴보려고 한다.
ThreadPoolExecutor
Executors를 살펴보기 앞서서 지금부터 살펴볼 4가지 메소드는 결국 ThreadPoolExecutor를 생성하는 factory method이다.
Executor와 ThreadPoolExecutor에 대한 내용은 Executor를 통한 비동기 작업에서 확인할 수 있다.
아래는 ThreadPoolExecutor의 기본 생성자이다. 생성자를 통해 각 파라미터들의 의미만 간단히 확인하고 넘어가자.
public ThreadPoolExecutor(int corePoolSize, // 최소 thread 개수
int maximumPoolSize, // 최대 thread 개수
long keepAliveTime, // thread가 corePoolSize를 초과한 경우 종료되기 전까지의 시간
TimeUnit unit, // keepAliveTime의 단위
BlockingQueue<Runnable> workQueue, // task가 실행하기 전 저장되는 queue
ThreadFactory threadFactory, // executor가 thread를 생성할 때 쓰는 factory class
RejectedExecutionHandler handler) // thread나 queue 용량이 초과했을 경우 불리는 handler1. newFixedThreadPool(int nThreads)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newFixedThreadPool는 고정된 개수의 thread를 사용하는 ThreadPoolExecutor를 생성한다.
파라미터로 전달된 nThread(thread 개수)가 각각 corePoolSize와 maximumPoolSize이 된다.
이 때 생성된 thread는 계속 새로 생성되는 것이 아니라 진행 중인 작업이 끝나면 종료되지 않고 다음 작업을 받아 수행하게 된다. 그리고 workQueue로는 LinkedBlockingQueue를 사용하고 쓰레드가 당장 처리하지 못하는 작업들을 queue에 대기시킨다.
corePoolSize와 maximumPoolSize가 같아서 thread pool에 있는 thread의 개수는 항상 같은 값으로 유지되기 때문에 잉여 corePoolSize 이상의 thread는 생기지 않아keepAliveTime는 0으로 입력된다.
만약 thread가 shut down되기 전에 에러로 인해 종료될 경우 ThreadPoolExecutor는 새로운 thread를 생성하여 다음 작업을 처리한다.
2. newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}newSingleThreadExecutor는 newFixedThreadPool(int nThread) 메소드에 변수로 1을 넣어준 것과 같다.
corePoolSize와 maxPoolSize가 각각 1로 설정되어 하나의 thread가 작업들을 실행하게 된다.
newFixedThreadPool(1) 과 다른 점은 FinalizableDelegatedExecutorService라는 클래스로 한 번 감싸져 있는 것인데 이 클래스는ExecutorService 메소드만 외부로 노출시키기 위한 wrapper class이기 때문에 실제 동작은 같다.
3. newCachedThreadPool()
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}newCachedThreadPool는 주어진 작업량에 따라 새로운 thread를 생성하는 ExecutorService를 생성한다. ThreadPoolExecutor를 생성하는 부분을 살펴보면 corePoolSize가 0이고 maxPoolSize가 Integer.MAX_VALUE이다.
그래서 이론적으로 작업이 없을 때는 thread 개수를 0로 유지하고 사용 가능한 thread가 없는 경우 thread 개수가 엄청 큰 수로 늘어날 수 있다.
Java doc를 살펴보면 newCachedThreadPool은 실행 시간이 짧은 작업들을 실행하는데 효과적이라고 한다. 어떤 이유 때문에 더 효과적이다 라고 말하는걸까?
처음 든 생각은
"짧은 시간 실행되고 끝날 작업들 때문에 비용이 큰 thread가 계속 생성, 종료되는게 오히려 더 비효율적이지 않나?" 였다.
그래서 반대로 크기가 고정된 thread pool에서 실행 시간이 짧은 작업을 실행하는 것이 왜 불리한가를 생각해보았다.
thread pool의 크기가 고정되어 있을 때 worst case인 경우
실행 시간은 길고 우선순위는 낮은 작업들이 모든 thread를 차지하고 있는 상황이 생길 수 있다.
이 때 실행 시간이 짧고 우선 순위가 높은 작업들이 추가된다면 바로 실행되지 못하고 이전의 긴 작업들이 모두 끝나길 기다려야 하고 이미 queue에 중요하지 않은 작업들이 쌓여있어 한참을 더 기다려야 중요한 작업이 실행될 수 있다.
이는 프로그램 측면에서 봤을 때 매우 비효율적이다.
그래서 thread pool 사이즈가 유동적으로 변할 수 있는 newCachedThreadPool을 사용하면 짧게 끝나는 중요한 작업들이 기다리지 않고 새로운 thread를 생성함과 동시에 빠르게 처리될 수 있다.
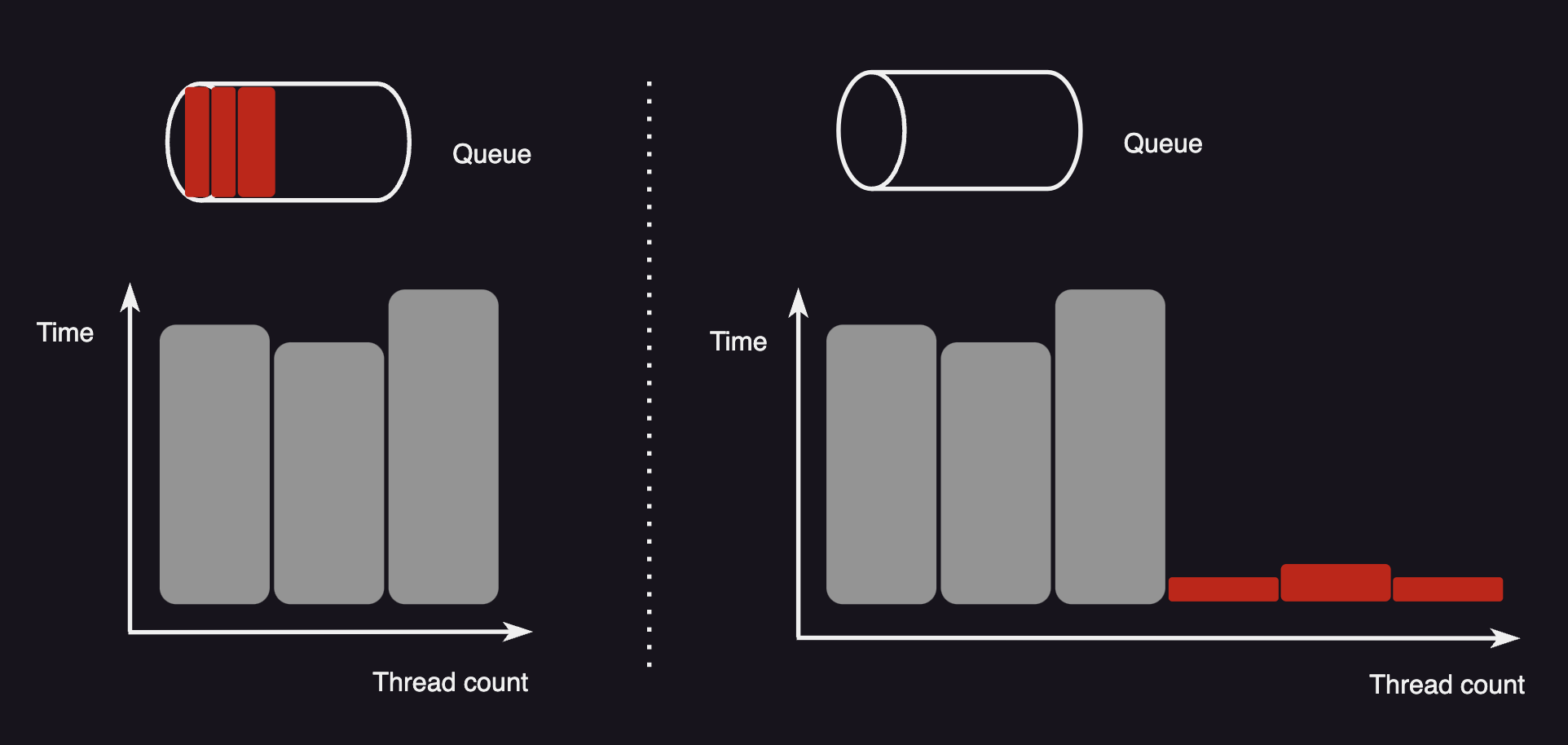
여기에 keepAliveTime이 60초로 설정되어 있어 작업 실행 후 60초 내에 다른 작업들을 받아 수행할 수 있기 때문에 thread의 생성과 종료라는 비용을 어느정도 줄여줄 수 있다.
정리하자면 java doc에서 말하는 효과적이라는 의미는 thread가 생성되고 종료되는 비용적인 측면에서 효과적인게 아니라 작업을 처리하는 측면에서 더 효율적인 것이다.
또한 newCachedThreadPool은 이론적으로 Integer.MAX_VALUE까지 thread 개수가 늘어날 수 있으므로 느린 작업이 쌓일 경우 메모리에 부하가 많이 쌓일 수 있지만 실행 시간이 짧은 작업들은 과부하없이 많은 작업들을 빠르게 처리할 수 있다.
newFixedThreadPool과 newCachedThreadPool 둘 중 어떤 상황에서 어떤 걸 써야되는지 완벽하게 나눌 수 없지만 장비의 자원이 한정적이고 thread pool 개수가 얼마까지 늘어날지 예상할 수 없다는 점에서 우선은 예상 가능한 newFixedThreadPool을 사용하는게 안정성 측면에서 더 나은 것 같다.
그러다가 모니터링을 거친 후 생각보다 효율이 안나오거나 간헐적으로 많은 작업들이 생기는 경우 테스트를 거친 후 thread 개수가 유동적인 newCachedThreadPool의 사용을 생각해보면 좋을 것 같다.
마지막으로 queue로는 SynchronousQueue를 사용한다. SynchronousQueue는 사실상 크기가 0인 queue로 이 queue에 작업을 넣으려고 할 때 대기 중인 thread가 없으면 block되고 반대로 대기 중인 thread가 있는데 작업이 없는 경우는 thread가 block된다.
4. newScheduledThreadPool(int corePoolSize)
/**
* Creates a thread pool that can schedule commands to run after a
* given delay, or to execute periodically.
* @param corePoolSize the number of threads to keep in the pool,
* even if they are idle
* @return the newly created scheduled thread pool
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}newScheduledThreadPool은 ScheduledThreadPoolExecutor를 생성한다.
ScheduledThreadPoolExecutor는 threadPoolExecutor를 상속받고 ScheduledExecutorService를 구현하고 있는데 기존의 ThreadPoolExecutor에 주어진 작업들을 정해진 시간 뒤에 실행하거나 정기적으로 실행하는 기능이 추가되었다.
corePoolSize는 입력받은 값으로 설정되고 maxThreadPoolSize는 Integer.MAX_VALU값이다. 그리고 keepAliveTime은 10 milliseconds이다.
ScheduledThreadPoolExecutor의 주요 메소드들을 살펴보자.
// 주어진 delay 이후 commnad가 한 번 실행된다.
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
// initialDealy 이후 command가 주기적으로 실행된다. 작업이 다음 실행되는 시간은 이전 작업이 끝남과 상관 없이 initialDelay 이후 period 주기로 계속 실행된다.
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
// initialDealy 이후 command가 주기적으로 실행된다. 작업이 다음 실행되는 시간은 이전 작업이 끝나고 delay 시간 만큼 지난 후이다.
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
위와 같이 특정 시간 이후, 특정 주기로 비동기 작업을 실행할 수 있기 때문에 특정 주기로 진행되어야되는 작업에 사용할 수 있다.
queue로 사용하는 DelaydWorkQueue의 코드를 살펴보면 heap 자료구조를 사용하는 것을 알 수 있다. ScheduledFutureTask의 time 값을 이용해서 heap에 정렬되고 우선순위가 생겨 작업들을 주어진 시간순으로 실행할 수 있도록 한다.
5. 정리
Executors 팩토리 메소드 클래스를 통해 우리가 필요한 ExecutorService를 조금 더 쉽게 사용할 수 있게 되었다.
앞서 두 글에서 살펴본 것 처럼 Executor는 비동기 처리에 대한 역할을 부여하고 사용자는 실제 실행에 대해 더 집중할 수 있다. 하지만 여기서도 몇가지 부족한 점은 존재하였고, 비동기로 실행한 결과를 조합하거나 예외처리 등 비동기 작업을 더 쉽게 유연하게 작업할 수 있는 CompletbleFuture를 java8부터 사용할 수 있게 되었다.
