Django ORM 구조와 최적화 전략
Django ORM (QuerySet)구조와 원리 그리고 최적화전략 - 김성렬 PyCon Korea 2020 을 보고 정리한 내용을 공유합니다.
ORM 특징
- Lazy loading : 정말로 필요한 시점에 쿼리셋을 평가한다. 필요하지 않은 순간에는 SQL문을 호출하지 않는다. 이러한 특성 때문에 실제 비효율적으로 ORM이 동작하기도 한다. 정말 필요한 만큼만 호출하기 때문에 첫번째 유저만 가져오고 나면 실제 쿼리셋은 전체를 가져오는 문이었지만 다시 전체를 가져올땐 다시 SQL문을 호출한다.
users: QuerySet[User] = User.objects.all()
users[0]
list(users)이를 해결하기 위해 쿼리셋 캐싱을 재사용해야한다.
list(user) 를 하게되면 전체 SQL 결과문을 캐싱한다. 이걸 result caching
- Eager Loading 즉시로딩
lazyloading 에서 발생하는 대표적인 이슈인 1+N 문제를 해결하기위해 prefetch-related, select-related 메서드를 제공한다.
user table - userinfo table (1:1 관계)
users: QuerySet[User] = User.objects.all() # 1번
for user in users:
user.userinfo 1번의 유저 불러오는 쿼리
N번의 유저인포를 불러오는 쿼리
총 1+100 번의 쿼리문이 생성됨
유저 인포의 정보가 1번 시점에선 필요하지 않았기 때문에 호출이 지연되었고, 그로 인해 N+1번의 쿼리가 생성되게 됨
- 쿼리셋의 구성요소
쿼리셋은 최소 한개의 쿼리와 0또는 N개의 추가 쿼리로 이루어졌다는 점.
eager loading
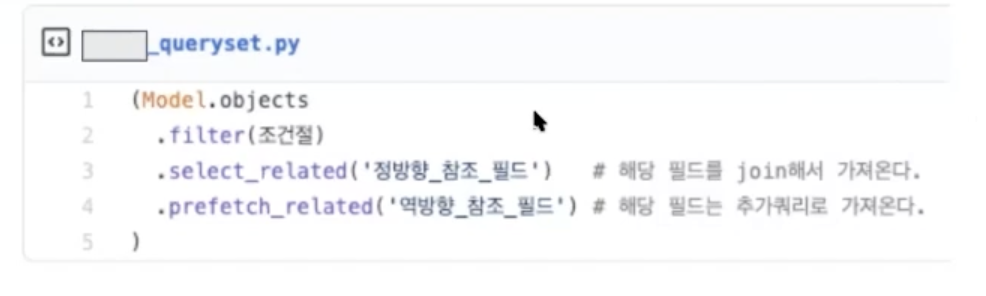

select_related는 join을 통해 데이터를 즉시 로딩함
prefetch_related는 추가 쿼리로 가져온다.
join
inner join : null 허용 안했을 때 (교집합)
outer join : null 허용 했을 때 (left를 기준으로 생각하면 된다)
select * from table A left outer join table B
성능이 좋게 테이블을 구성해야한다. 조인을 해도되도록..
정규화 : 중복을 제거한다. 중복을 제거한다는 것은 A, B 테이블 둘다 이름이 저장되어있을때 A만 변경되면 무결성이 깨진다. 데이터 무결성을 지키기 위해서
불필요한 유니크키를 없애고,
데이터를 쪼개면 조인을 많이 해야하기 때문에
무결성을 포기하고 회원 이름을 넣어버린다. => 역정규화
이걸 application 단에 짜야한다.
DB의 무결성을 포기하고 성능을 잡는걸 역정규화라고 한다.
정답이 없다.
비즈니스 상황에 따라
최대한 쪼개놓고 필요할 때마다 역정규화를 한다.
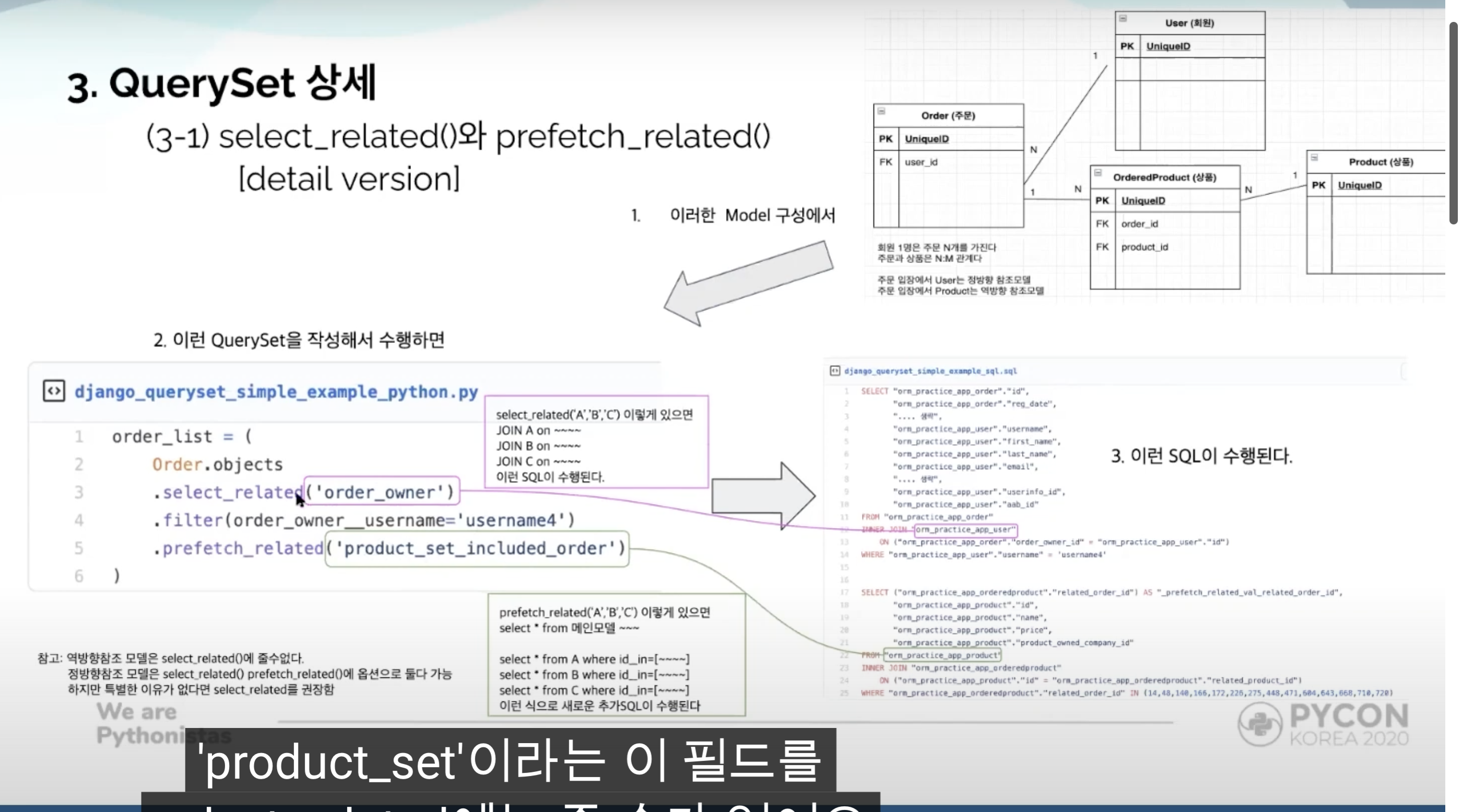
select related는 정참조인 경우에만 사용할 수 있다.
학생(N) -> 반(1)
prefetched related는 추가 쿼리를 통해 가져오는 것이기 때문에
정참조 역참조 모두 가능함
지키면 좋을 순서 왜냐? SQL문이 작성되는 순서와 가장 유사함
User.objects.all()
.select_related()
.filter
.prefetch_related()쿼리셋 캐시가 재사용되지 못하는 케이스
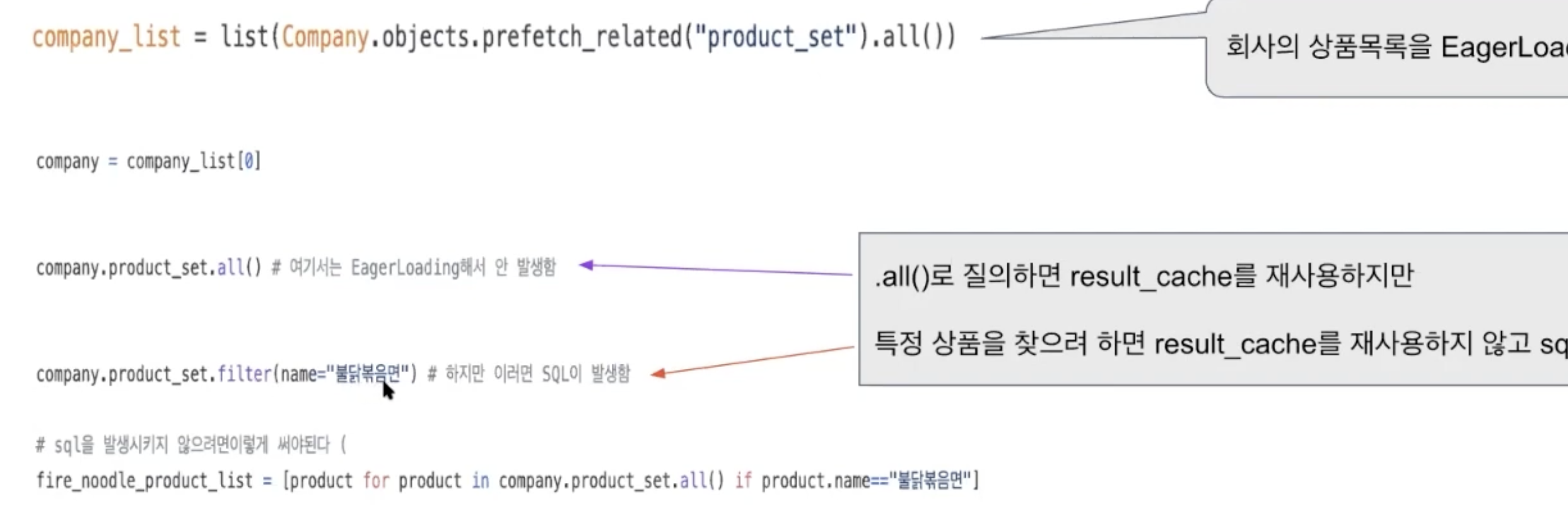
raw queryset은 native SQL이 아니다.
서브쿼리의 발생조건
values()
values_list() 사용시 eager loading (select, prefetch)옵션을 무시한다


