웹 브라우저의 이해
1. 브라우저의 이해
1.1 Web Browser란?
- WWW(World Wide Web)에서 정보를 검색, 표현하고 탐색하기 위한 소프트웨어 이다.
- 대표적으로 Chrome, Explorer Edge 등이 있다.
- 일종의 애플리케이션으로 인터넷에서 특정 정보로 이동하는 주소 입력창을 받고, 서버와 HTTP로 정보를 주고 받는 네트워크 모듈을 탑재하고 있다.
- 서버에서 응답받은 값을 해석하고 표현해주어 클라이언트가 보기 좋은 형태로 변환해준다.
1.2 브라우저의 역할
- Client가 입력한 내용에 대해 서버에 Request를 보낸다.
- Server에서 제공한 Response 값을 해석하고 브라우저 화면에 출력한다.
1.3 브라우저의 구성 요소
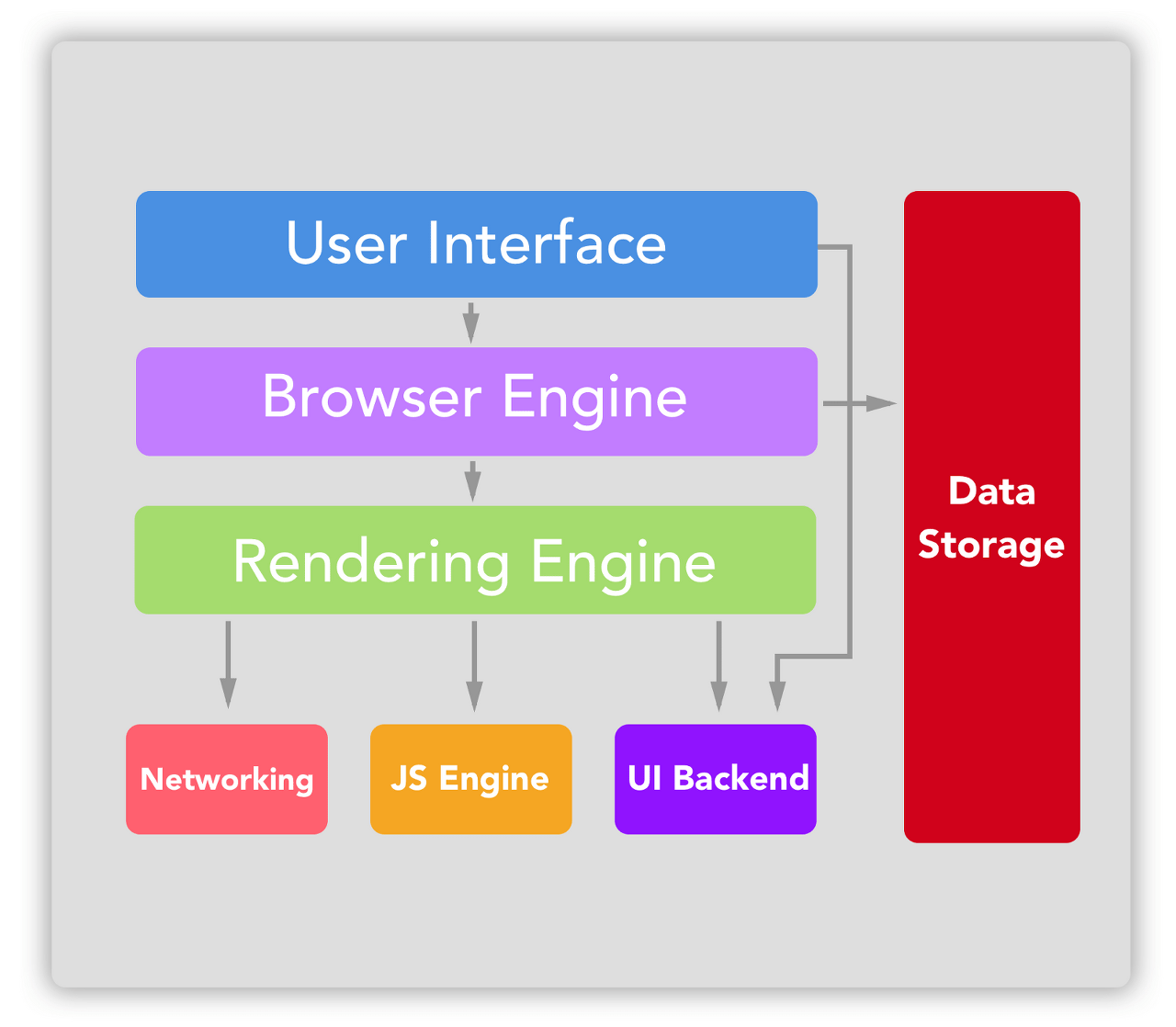
User Interface: 사용자가 사용하는 인터페이스 모형Browser Engine: User Interface와 Rendering Engine 사이의 동작을 제어해주는 엔진이다. Data Storage를 참조하며 로컬에 데이터를 쓰고 읽으면서 다양한 작업을 한다.Data Storage: Local Storage, Indexed DB, 쿠키 등 브라우저 메모리를 활용하여 저장하는 영역이다.Rendering Engine: 요청한 콘텐츠를 화면에 출력하는 역할이다. HTML, CSS 등을 파싱하여 최종적으로 화면에 그린다.Networking: http 요청을 할 수 있으며 네티워크를 호출할 수 있다.JS Engine: javascript 코드를 해석하고 실행한다.UI Backend: 기본적인 위젯을 그리는 인터페이스이다.
1.4 렌더링 엔진의 동작 원리

1. 브라우저는 서버로 부터 HTML 문서를 모두 전달 받는다.
2. 렌더링 엔진이 이 문서를 파싱해 DOM 트리를 구축한다.
3. 외부 CSS 파일 등의 스타일 요소를 파싱한다.
4. DOM 트리와 3의 결과물을 합쳐 렌더 트리를 만든다.
5. 렌더 트리의 각 노드에 대해 화면 상 배치 구조를 잡는다.
6. UI백엔드에서 렌더 트리를 그리게 되고, 화면에 사용자가 보도록 출력한다.
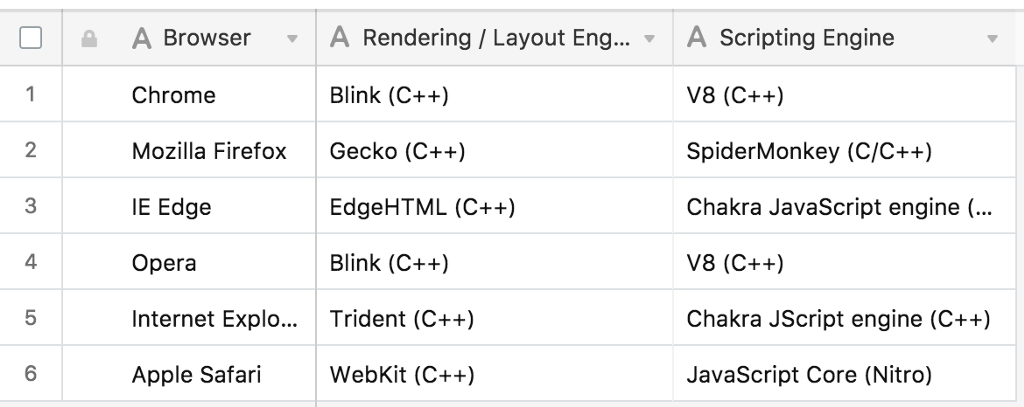
1.5 Engine
- rendering/layout Engine과 Scripting Engine이 대표적이다.
- 해당 역할을 하는 인터프리터 역할을 한다.
Rendering/Layout Engine: display를 시키기 위해 해석하고 표현하는 엔진이다.Script Engine: javascript와 같은 스크립트 언어를 해석해 표현하는 엔진이다.
- 각 브라우저들은 각기 다른 엔진을 가지고 있는데, 이것을 잘 개발하는게 핵심이다. 최근 웹 페이지는 대부분 자바스크립트를 포함하고 있기 때문에 속도와 안정성을 높이는 자바스크립트 엔진 개발에 많은 힘을 쏟고 있다.

2. DTD
2.1 문서 형식 선언
-
DTD(Document Type Declaration) 또는 DOCTYPE이라고한다.
-
어떤 SGML이나 XML(SGML에서 파생된 언어) 기반 문서 내에 그 문서가 특정 문서 형식 정의(DTD)를 따름을 지정하는 것이다. 본래 DTD에 기반한 SGML 도구를 이용해 문서 해석 가능성과 유효성을 검사하기 위한 목적으로 문서 내에 삽입되었다.
-
우리가 bash shell에서 스크립트를 구성할 때 #!bin/bash 를 입력하는 것은 bash 쉘로 해당 스크립트를 실행시키겠다는 의미와 비슷하다고 생각하면 되겠다(당연히 완전히 같은 개념은 아니다)
#! 은 스크립트의 제일 앞에서 이 파일이 어떤 명령어 해석기의 명령어
집합인지를 시스템에게 알려주는 역할을 합니다. #! 은 두 바이트 [1] 의 "매직넘버"(magic number)로서, 실행 가능한 쉘 스크립트라는 것을 나타내는 특별한표시자입니다(man magic을 하면 재미있는 주제의 이야기들을 볼 수 있습니다). #!바로 뒤에 나오는 것은 경로명으로, 스크립트에 들어있는 명령어들을 해석할프로그램의 위치를 나타내는데 그 프로그램이 쉘인지, 프로그램 언어인지,유틸리티인지를 나타냅니다. 이 명령어 해석기가 주석은 무시하면서 스크립트의첫 번째 줄부터 명령어들을 실행시킵니다.
#!/bin/sh
#!/bin/bash
#!/usr/bin/perl
#!/usr/bin/tcl
#!/bin/sed -f
#!/usr/awk -f
HTML 문서의 규격 판 번호를 명시하는 데서 흔히 볼 수 있다. 웹 브라우저는 문서 형식 선언이 없는 HTML 문서를 쿼크 모드로 렌더링하지만 문서 형식 선언이 있는 HTML 문서를 표준 모드로 렌더링하기 때문에, 문서 형식 선언을 이용해서 어떤 웹 페이지가 모든 웹 브라우저에서 같은 레이아웃으로 제공되도록 할 수 있다. 한편 HTML5은 구조적으로 SGML과 호환될 수 없다. 따라서 HTML5로 구성된 문서에서 문서 형식 선언은 불필요하지만, 웹 브라우저들의 표준 모드를 활성화하기 위해 최소한의 형태로 유지되었다.
3. SEO
3.1 SEO 란?
- SEO(Search Engine Optimization)은 검색 엔진에 맞게 자신의 콘텐츠를 검색 사이트 상단에 위치시키는 작업을 말합니다.
- 상단으로 끌어올리기 위해서는 광고노출과 검색엔진 노출이 있는데, 최근에는 검색엔진에 광고를 끼워넣어 결국 광고가 제일 위로 올라오긴 합니다.
- 포탈 사이트에서 대부분 검색 엔진을 가지고 있는데, 검색 엔진은 크롤링(Crawling, 관련 데이터를 가져오는 과정)과 인덱싱(Indexing, 크롤링을 통해 얻은 정보를 검색 색인에 저장함)한 정보를 카테고리화하여 저장 및 표현합니다. 각 검색 엔진은 사용자가 '검색'을 누르면, 카테고리화 한 수 많은 정보를 알고리즘에 따라 분류하여 정보를 표출합니다.
3.2 작업 대상에 따른 분류
3.2.1 Technical SEO
- 검색엔진이 자사의 홈페이지를 쉽게 찾을 수 있도록 개발자와 협업하여 홈페이지를 만듭니다.
도메인 관리: 하나의 도메인을 여러 웹 사이트 주소로 나눠 노출하는 횟수를 늘리는 방식입니다. '서브도메인'방식과 '서브폴더' 방식이 있으며, 서브 도메인은 웹 페이지들을 하위 도메인으로 확장 관리합니다.
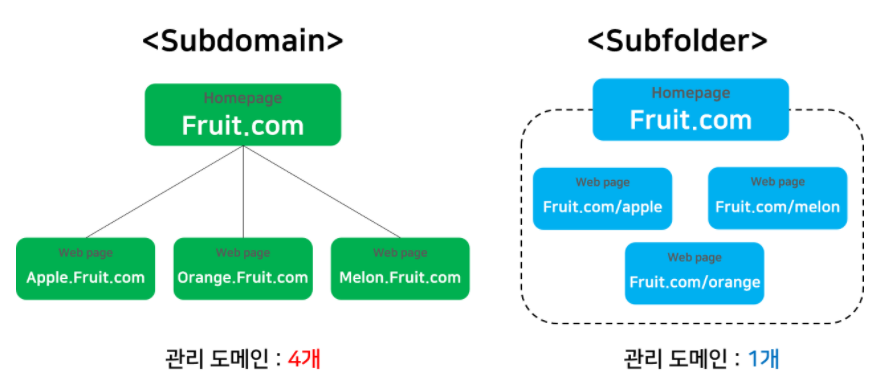
구글의 경우 도메인 별로 점수를 부여해 순위를 두는데, 서브 도메인 방식의 경우 관리 도메인이 4개가 되므로, 각 도메인 별로 점수를 관리해야하기 때문에 관리방식은 서브 폴더 방식이 유리합니다.
-
사이트 맵: 웹 사이트의 모든 페이지들을 목차처럼 보여주는 'xml' 형식의 파일이다. 일반적인 크롤링 과정에서 발견하지 못한 페이지도 크롤링과 인덱싱이 되기 때문에 노출 확률이 더 올라간다. -
robot.txt:
검색 엔진의 웹 크롤러(검색 로봇)에게 사이트맵의 위치를 안내하고, 특정 웹 크롤러가 웹페이지의 정보를 수집하는 것을 차단합니다. 크롤러가 중복된 콘텐츠의 웹페에지를 제한 없이 수집할 경우 검색 엔진의 평가에 부정적인 영향을 미칠 수 있기 때문이다. 일반적으로 텍스트파일로 작성하여, 사이트의 루트 디렉토리에 위치 시켜 설정한다.
3.2.2 Contents SEO
-
키워드 관리: 콘텐츠 내 포함된 특정 키워드의 위치와 갯수 등을 검색 엔진이 평가한다. 키워드는 데이터에 기반한 것이 좋다. (롱테일 키워드 : 검색 의도가 구체적으로 표현된 3개 단어 이상의 조합 키워드 방식) -
컨텐츠의 질 높이기: 너무도 당연하지만 콘텐츠의 질 자체가 높은 것도 사용자가 콘텐츠를 소비할 때 유리합니다.
