python - web crawling
1.[python] #0. 간단하게 웹 크롤링 기능 개발 시작
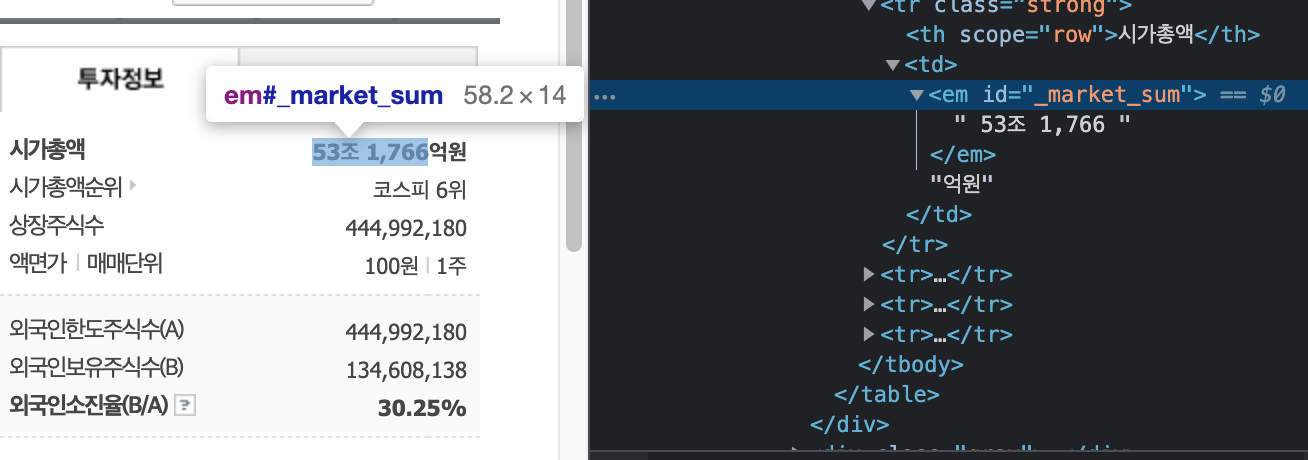
BeautifulSoup 설치requests 설치먼저 뭘 선택할지 개발자도구로 확인셀렉터를 작성 (이게 매우 중요하다.)import requestsfrom bs4 import BeautifulSoupreq = requests.get("https://financ
2.[python] #1. BeautifulSoup - 설치와 태그 기본 읽기

본격적인 크롤링 기본을 디립따 파보는 시간을 가져 볼 것이다. "뷰티풀수프 문서" https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/ 를 정독하며 정리한 글인데 전부다 볼 예정이다. 엄청나게 많아 보이지만 그
3.[python] #2. BeautifulSoup - 컨텐츠 읽기 기본

.contents 는 선택된 soup 의 하위 엘리먼트(내용)을 전부 가져온다. 소스를 한번 쳐 보자.html 태그를 전부 제거한 문자열만 리턴해준다. 생각외로 쓰임새가 많을 것 같다.선택된 soup 의 하위 엘리먼트(내용)을 iteratable object 로 리턴한
4.[python] #3. 네이버 검색 결과 목록을 뽑자
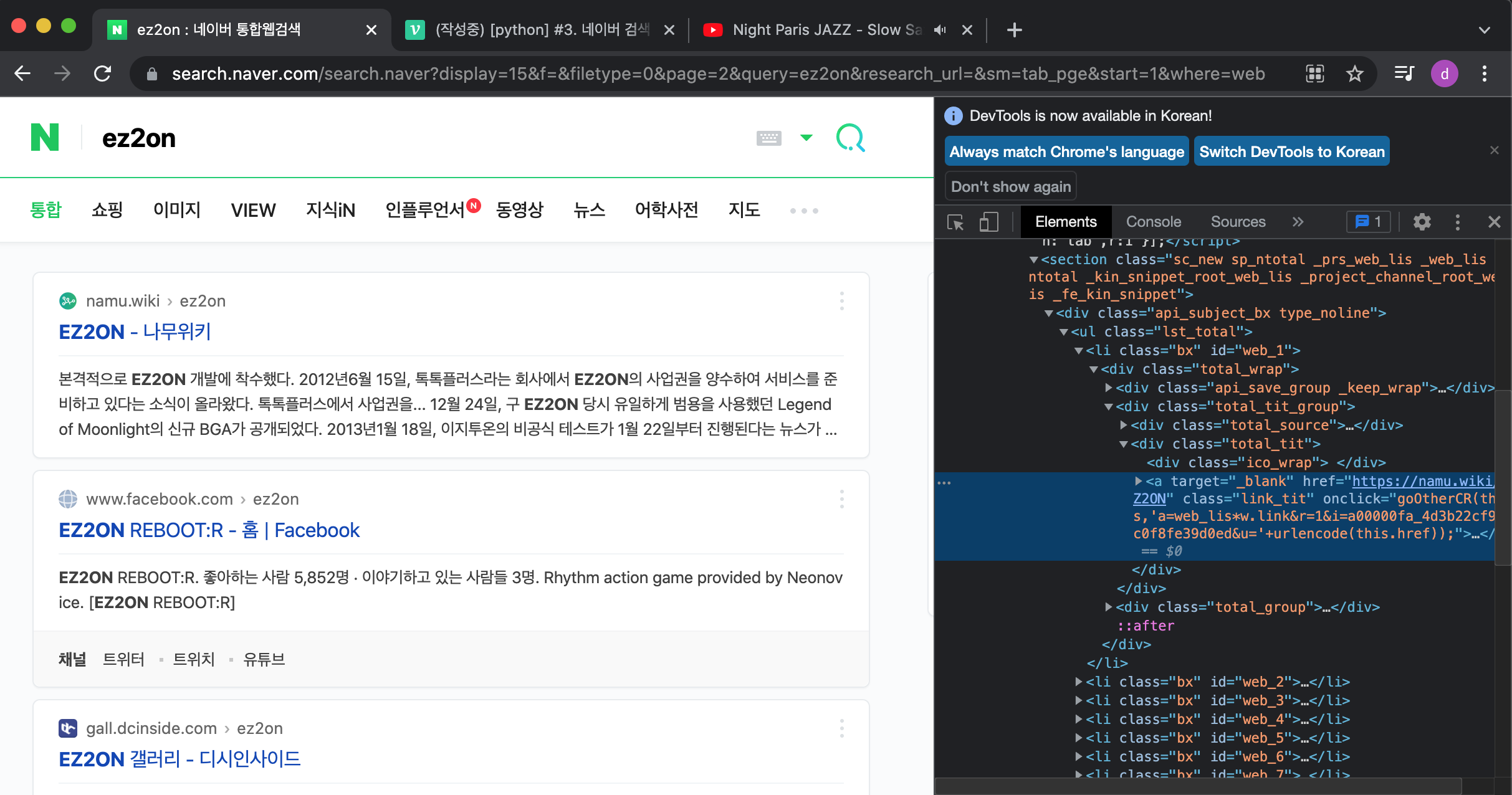
첫 목표는 네이버 검색화면 난 리듬게임을 좋아하니 검색어에 이지투온을 검색해 보겠다. 여기서 뭘 뽑아낼지를 고민한다. 난 어디까지나 텍스트 자료수집과 웹사이트 정보를 목적으로 하니 제목과 접속 URL을 취득하도록 하겠다. 개발자 도구를 연다(맥OS의 경우 Optio
5.[python] #4. BeautifulSoup - 인접 엘리먼트 구하기

선택된 soup 의 상위 엘리먼트를 취득한다.왼쪽, 오른쪽에 있는 엘리먼트를 취득한다. 일단 소스부터 보면서 ㄱㄱㄱ근데 문제가 생겼다.그래서... 확인해 보았다.그 말은 곧 sibling 은 엘리먼트만 횡단하는게 아닌 특정 문자열에도 적용이 되는 것 같다.단순히 봐선
6.[python] #5. BeautifulSoup - find_all (1)

실질적인 크롤링 보다 BeautifulSoup 에 할애하는 시간이 훠\~~얼씬 많다. 대충 보니 문서의 3분의 1정도 읽은것 같아 보이는데 최대한 빨리 빡집중 해서 정리해 보도록 하겠다. 얼마나 시간이 걸릴지는 나도 모른다...다시 한번 볼 기회가 생겨 영광(?)이다.
7.[python] #6. BeautifulSoup - find_all (2)

태그 내의 텍스트만 가지고 컨트롤해 볼 예정이다.text 값에 해당하는 엘리먼트를 리턴한다.최상단에 re(정규표현식... 인가?) 를 import 하자.텍스트의 일부가 되는 문자열을 입력흠.....................limit 인자를 이용하도록 하자.정리가 안
8.[python] #7. BeautifulSoup - find (1)

먼저 find_all 을 다시 보도록 하자.그럼 find 는?find_all 과 find 의 결과가 다르다...find 를 이용하여 class 속성값이 title 인 p 태그 구하기find 를 이용하여 body 태그 밑의 b 태그 중 vel 이라는 속성값을 가지는 태그
9.[python] #8. BeautifulSoup - find (2)

.parents는 선택된 soup 의 부모 엘리먼트를 쭉~찾아 가는 기능이다. 기존에 다뤘던 기능들과 사실상 차이가 없다.이전 BeautifulSoup 포스팅을 참조해 볼 수 있다.https://velog.io/@exoluse/series/python-web-
10.[python] #9. 네이버 KBO 순위표 크롤링 하기
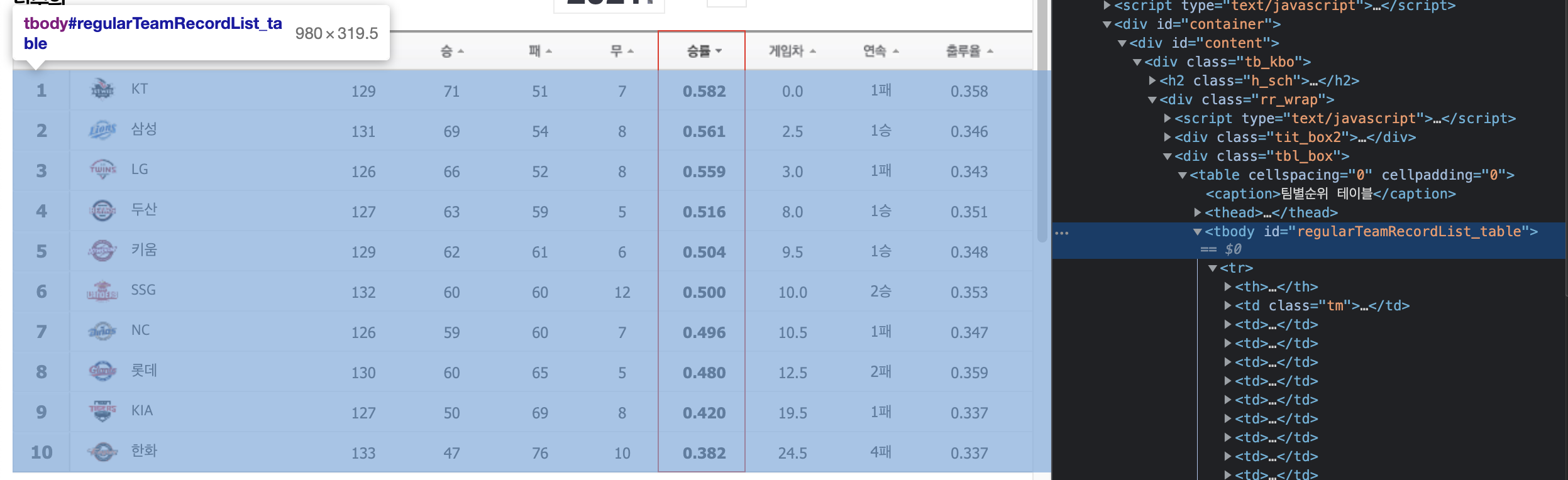
일단 순위 페이지로 이동 원하는 데이터가 있는 곳을 찍자 
네이버 스포츠 야구 메인페이지의 "야구 경기 일정결과" 부분을 크롤링 하고싶다.아... SSG 졌네 ㅠㅠ
12.[python] #11. 평화로운 중고나라 키워드 검색 목록 뽑아내자
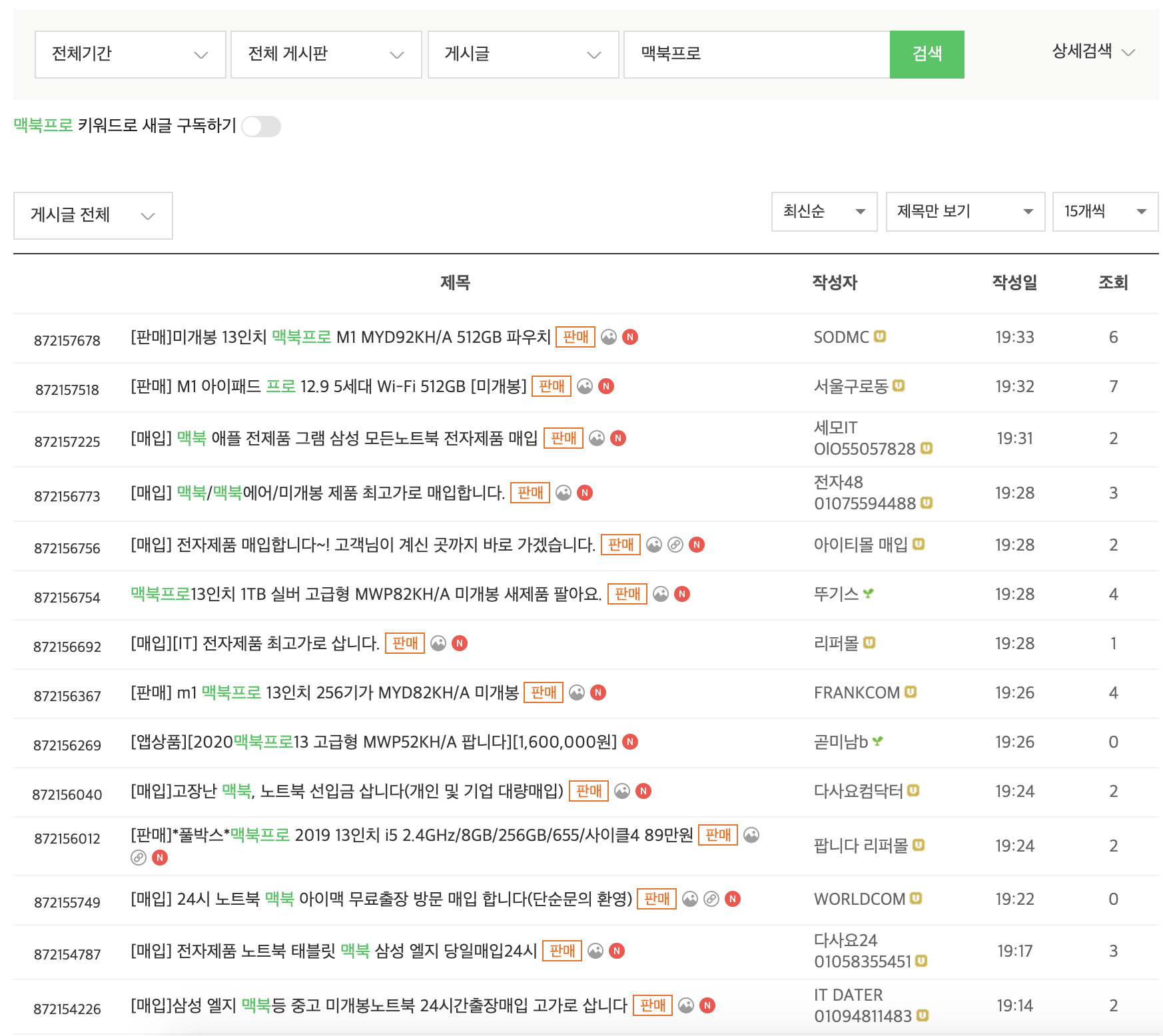
"맥북프로" 로 검색한 목록을 뷰티풀수프로 꺼내 보겠다.글목록을 가져올때 현재 페이지와 글 갯수를 지정할 수 있더라... 물론 50개 이상은 불가능하다.글 갯수를 50개로 하고 텍스트에 2020을 포함하는 목록만 취득하였다. 이렇게 하면 맥북프로 2020 판매글을 찾을
13.[python] #13. 셀레늄을 찍먹해보자
셀레늄(selenium) 이란게 눈에 보이기 시작했다. 한번 설치도 해보고 찍먹도 해보자.일단 크롬 버전 확인부터 하자크롬드라이버 공식 홈페이지 접근https://chromedriver.chromium.org/downloads본인의 버전에 맞는 드라이버 선택O
14.[python] #14. Selenium - 브라우저 조작
셀레늄을 설치하고 대충 돌려 봤으니 이번에는 기본적인 기능부터 조져볼 것이다.현재 로드된 URL을 리턴한다.F5를 눌러 새로고침 한것과 똑같은 효과를 낸다.title 태그의 텍스트를 리턴한다.현재 띄우고 있는 창의 핸들러를 리턴한다.새로운 탭 또는 창을 띄울 수 있다.
15.[python] #15. 셀레늄으로 아이프레임 요소 조작하기
html 파일 2개를 생성하자.driver.switch_to.frame(iframe)driver.find_element(By.TAG_NAME, 'button').click()driver.switch_to.default_content()
16.[python] #16. 셀레늄으로 창 크기 컨트롤하기
driver.getwindowsize() 창의 너비/높이 구하기 driver.setwindowsize() 창 크기 조절 쌉가능 driver.getwindowposition() 스크린 상에서의 창 좌표 driver.maximize_window() 창 크기 최대화
17.[python] #17. 스크린샷 저장 및 스크립트 실행
셀레늄 import, 드라이버 세팅 driver.save_screenshot 전체 스크린샷 element.screenshot 선택된 요소 스크린샷 이건 좀 신박했다. driver.execute_script 스크립트 실행
18.[python] #18. 포털사이트 뉴스 헤드라인 캡쳐하기
네이버 뉴스와 다음 뉴스를 부분 캡쳐해서 이미지로 저장해 보겠다.소스 먼저...스크린샷은 이렇게 저장된다저장된 이미지
19.[python] #19. 포털사이트 자동로그인 해보자
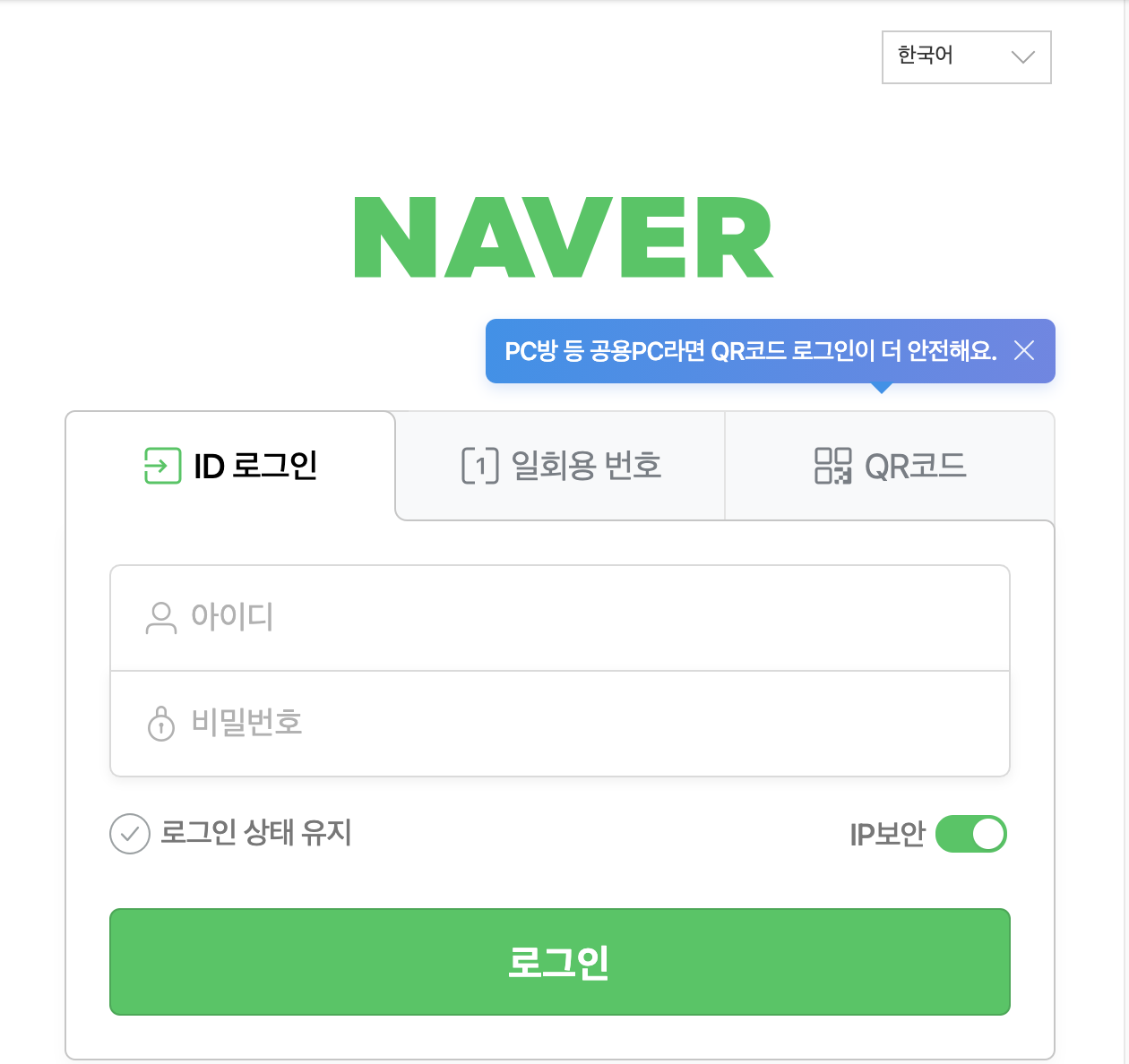
이게 크롤러라는게 들통이 난 모양이다.다른 로그인 폼도 시도해 봐야겠다.
20.[python] #20. 클립보드 이용과 키 조합 보내기

붙여넣기(MAC 의 경우)대충 이런식으로 하면 로그인시 캡챠는 피할 수 있다고 한다. 키 조합은 얼마든지 가능하니... 응용해 보면 되겠다.