1. python 웹 크롤링 퀴즈
- 네이버 영화 페이지 에서 순위, 제목, 그리고 평점 가져오기

(1) 해당 페이지에서 반복되는 부분 분석을 통한 전체 값 가져오기
movies = soup.select('#old_content > table > tbody > tr')
print(movies)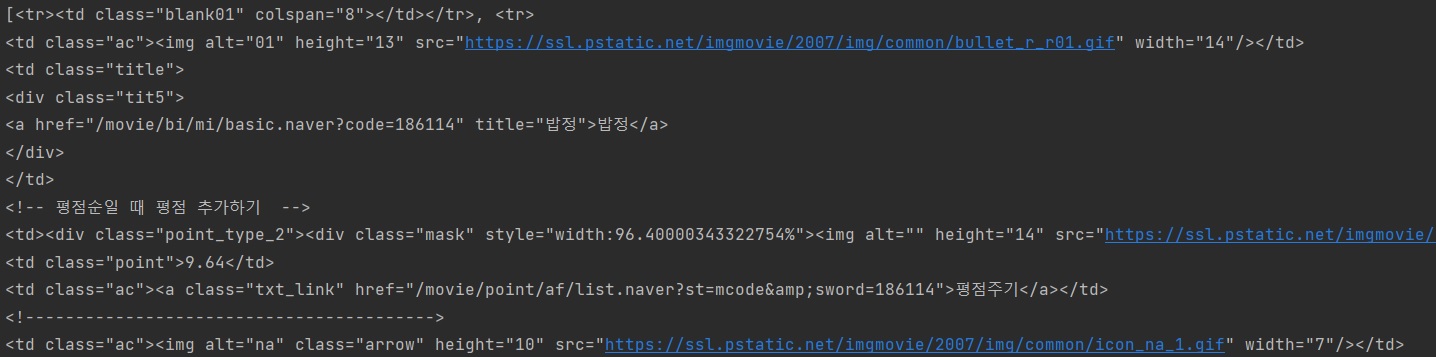
(자세히 보면 list임을 알 수 있다.)
(2) 영화 제목 가져오기
- 지난번 포스팅에서 가져온 방법에서 select_one('selector')를 통해 한 줄씩 가져오면 된다. (a tag의 text 값가져오기)
for movie in movies:
a = movie.select_one('td.title > div > a')
if a != None:
print(a.text) 
(3) 평점 값 가져오기
- 위 URL 에서 평점의 마우스 우클릭 > 검사를 눌러보면 해당 값은 id가 point인 td tag의 text 값 임을 알 수 있다.

- select_one('selector') 를 이용해서 id가 point인 td tag의 text 값을 가져온다.
for movie in movies:
a = movie.select_one('td.title > div > a')
point = movie.select_one('td.point')
if a != None:
print(a.text, point.text)
(4) 순위값 가져오기
- 위 URL에서 순위의 마우스 우클릭 > 검사를 눌러보면 해당 값은 img tag에 있는 alt 값임을 알 수 있다.

- select_one('selector')를 통해 아래와 같이 한 줄씩 img tag의 값을 가져온다.
for movie in movies:
num = movie.select_one('img')
a = movie.select_one('td.title > div > a')
point = movie.select_one('td.point')
if a != None:
print(num, a.text, point.text)
- 우리가 가져와야 하는 값은 위 그림에서 alt값 이기 때문에 print문을 아래와 같이 수정
for movie in movies:
num = movie.select_one('img')
a = movie.select_one('td.title > div > a')
point = movie.select_one('td.point')
if a != None:
print(num['alt'], a.text, point.text)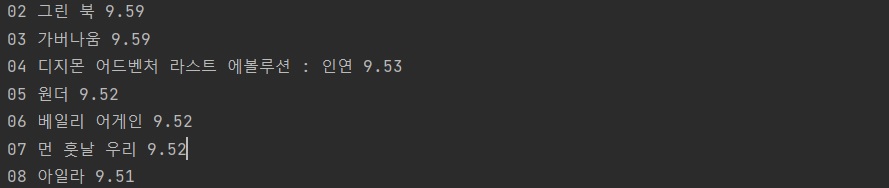
2. DB 개괄
RDMS (Relational database management system) : DB 간의 관계(Relation)을 통해 DB를 관리. 보다 정형화 되어있음.
NoSQL (Not Only SQL): RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술
- mongoDB의 atlas DB 사용 할 예정 (Mongo DB를 위해 사용할 수 있는 컴퓨터 한 대 라고 생각하면 편하다)
3. python에서 altas DB 접속 하기
-
pymongo 와 dnspython package의 설치 필요.
-
pycharm에서 설치 하기 위해선 이전에 설치 했던 방법 참고
(file > setting > python interpreter > +버튼 > 원하는 library 검색 후 install package 버튼 클릭) -
기본 코드부분(아래)에 본인이 설정한 admin 계정 정보 및 DB 정보 입력
from pymongo import MongoClient
client = MongoClient('mongodb+srv://계정:비밀번호@DB명.ptois.mongodb.net/DB명?retryWrites=true&w=majority')
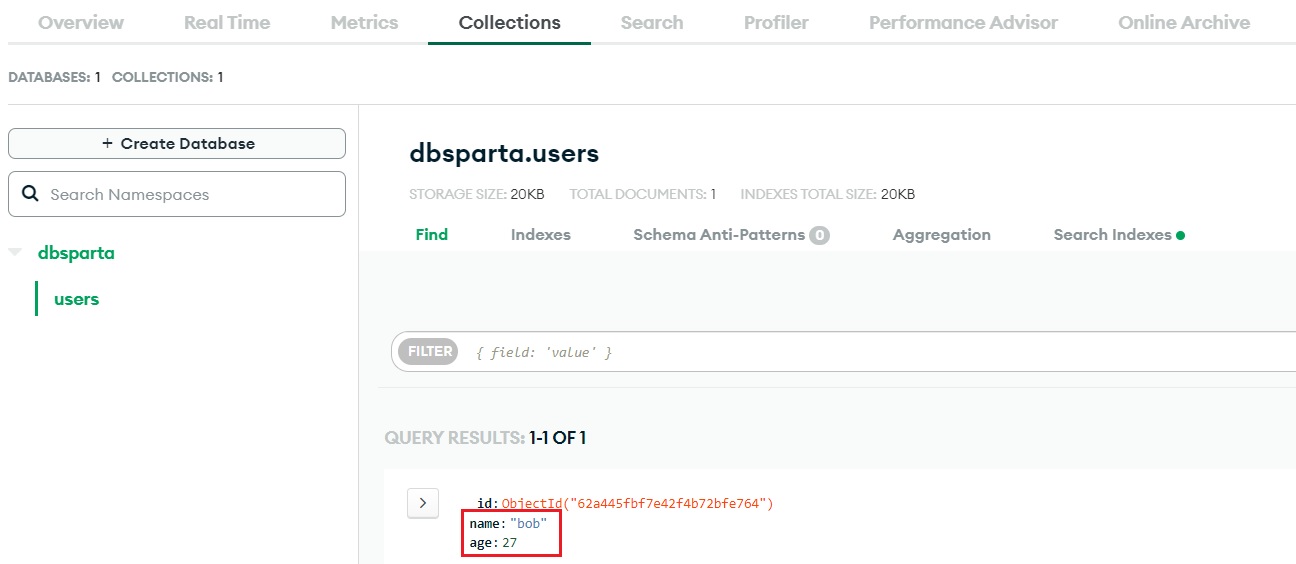
db = client.dbsparta- test data 생성
doc = {
'name': 'bob',
'age':27
}- 해당 data를 db에 insert 및 실행
db.users.insert_one(doc)- insert 확인
4. pymongo로 DB 조작하기
-
DB에 있는 값 확인하기
-
조건 없이 모두 확인할 땐 아래와 같이 입력
all_users = list(db.users.find({}))
for user in all_users:
print(user)(조건이 있는 경우 {}에 조건을 넣으면 된다)

(또는 all_users는 list이기 때문에 user에 조건을 줘도 된다
ex. user['name'] )
- 기본적인 CRUD
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})5. 웹 크롤링 결과 MongoDB에 저장하기
- 아까 웹 크롤링 결과 파일은 각각 변수에 저장했다.
- MongoDB에 값을 저장하기 위해선 dictionary 형태로 값을 저장했다
-> 2개를 이용해서 크롤링 결과를 MongoDB에 저장할 수 있다.
for movie in movies:
a = movie.select_one('td.title > div > a')
if a != None:
title = a.text
rank = movie.select_one('img')['alt']
star = movie.select_one('td.point').text
doc = {
'title':title,
'rank':rank,
'star':star
}
db.movies.insert_one(doc)실행하면 아래 그림과 같이 movies가 새로 생기고 값이 들어옴


티끌모아 태산을 아는 사람