▶ 한줄평 : 인덱스와 뷰에 대해서 정확하게 알 수 있었고 국비지원으로 IT와 관련하여 지식들을 쌓을 수 있어서 도움이 많이 된다.
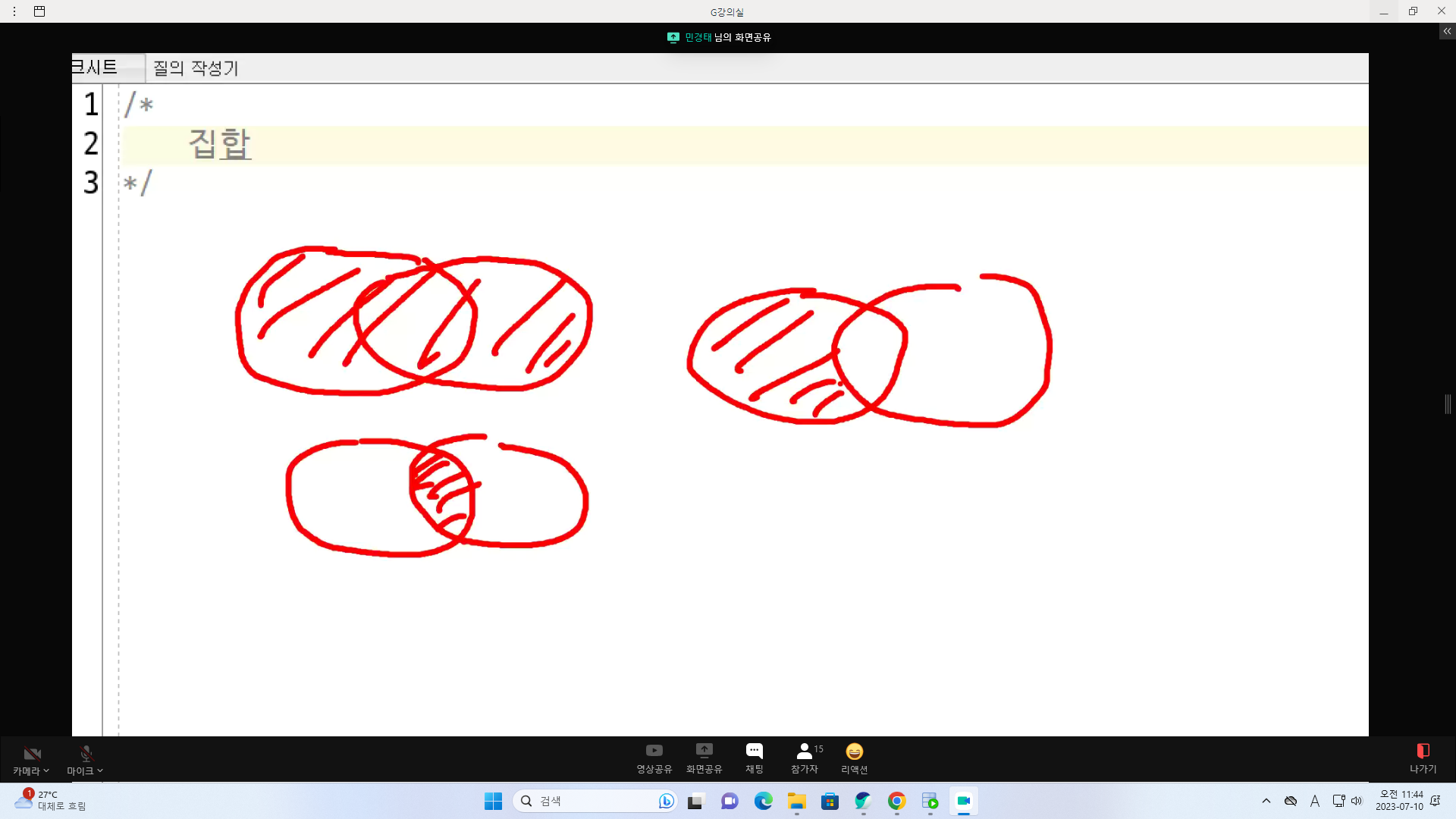
집합
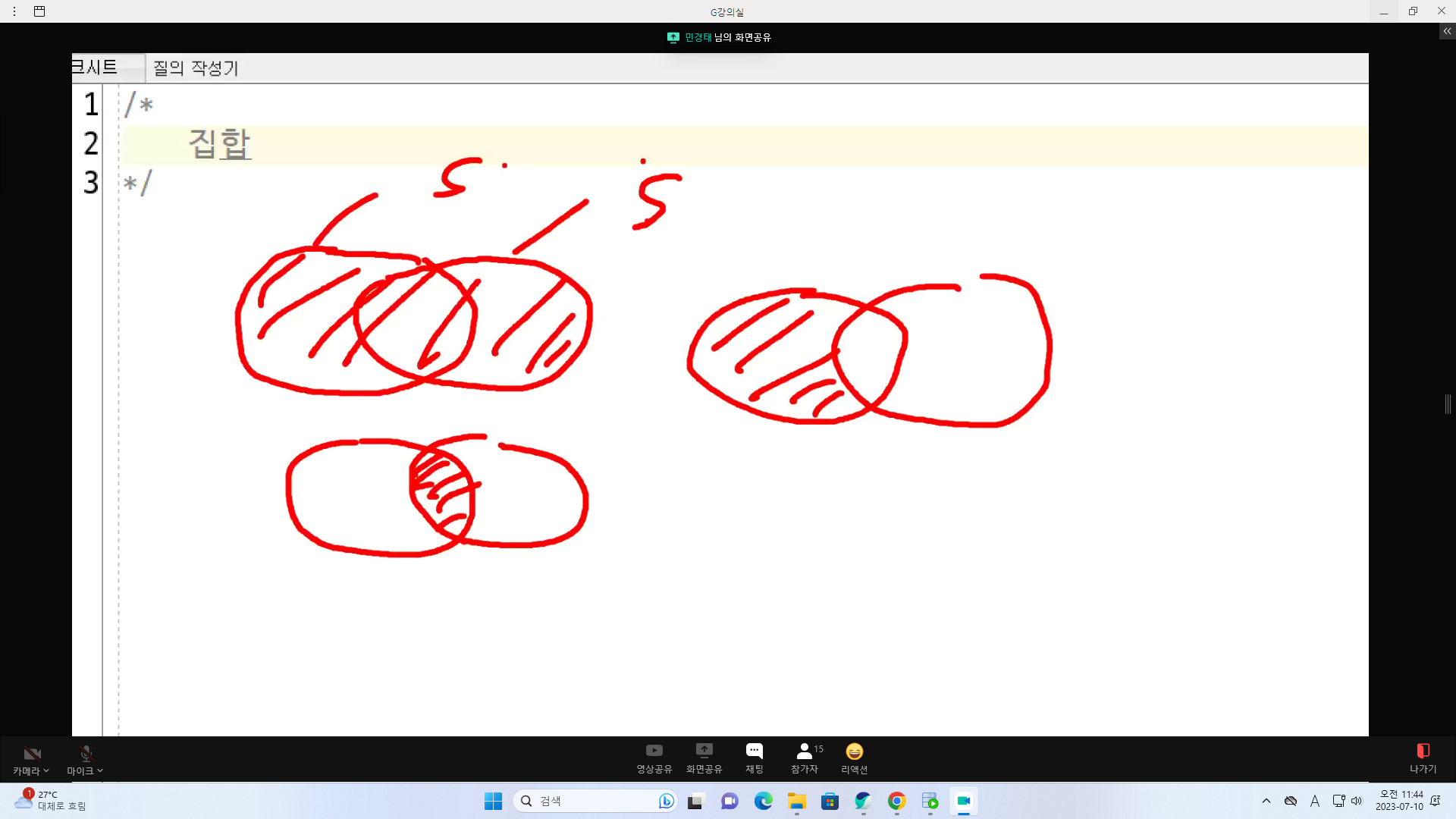
S:SELECT
UNION 합집합
INTERSET 교집합
MINUS 차집합

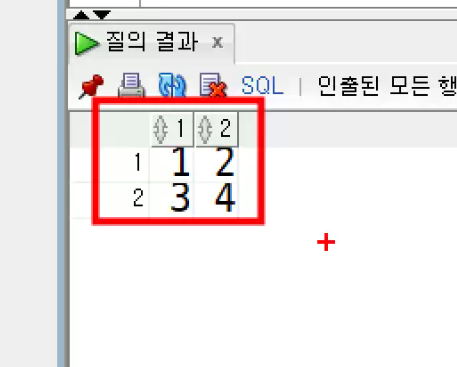
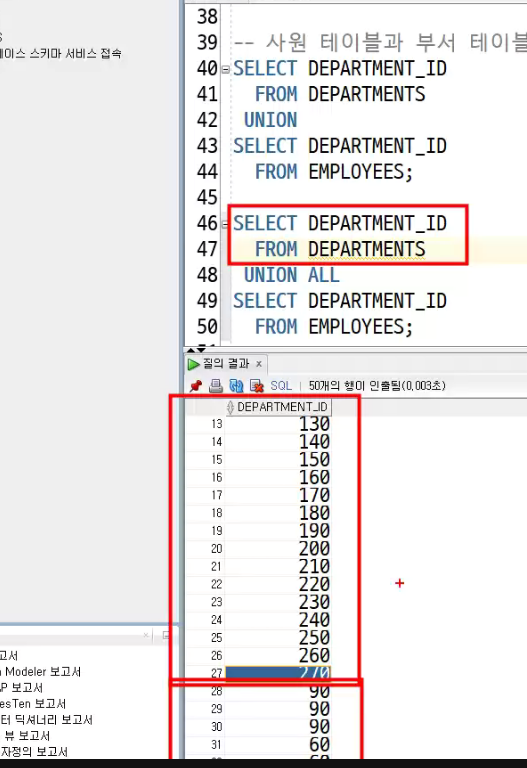
UNION(중복을 제거한 합집합)
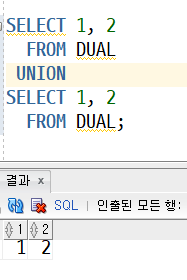
UNION ALL(중복을 그대로 조회하는 합집합)
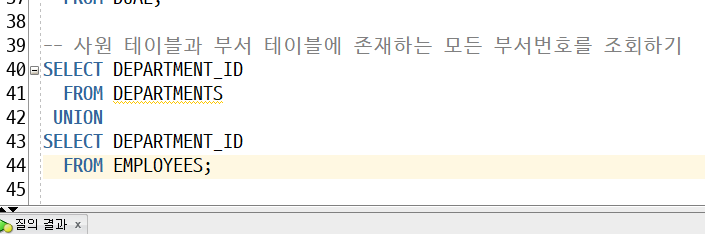
-> 합쳐지지 않고 중복 상관없이 데이터가 가져와짐

-> 조인으로 풀면) 내부 조인(INNER JOIN)
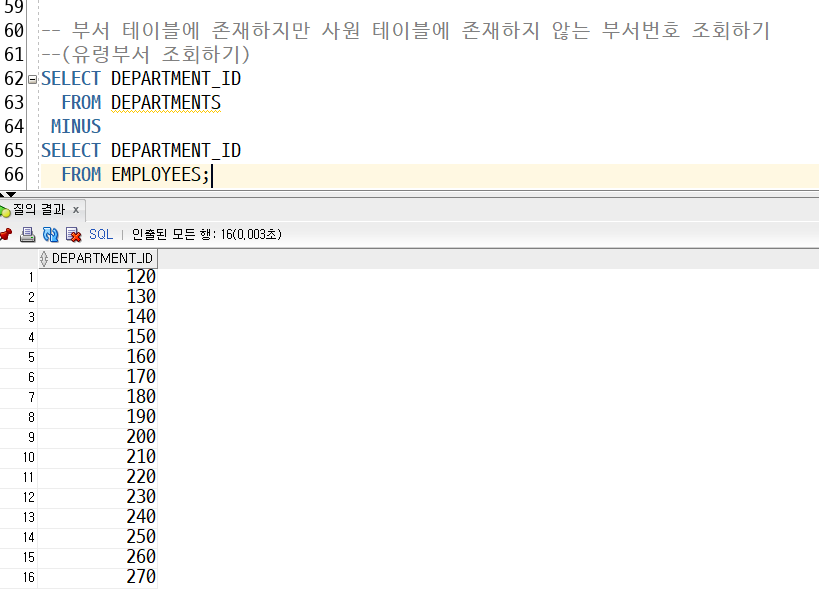
-> 사원에 없는것만 조회됨
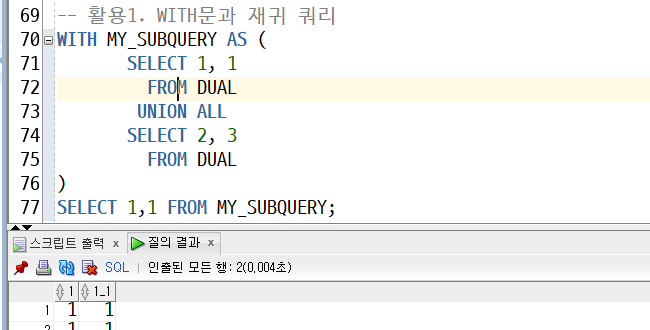
WITH : 특정쿼리(CODE BLOCK)를 저장시켜 놓고 바로 사용하는 방식

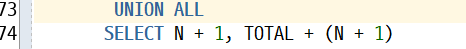
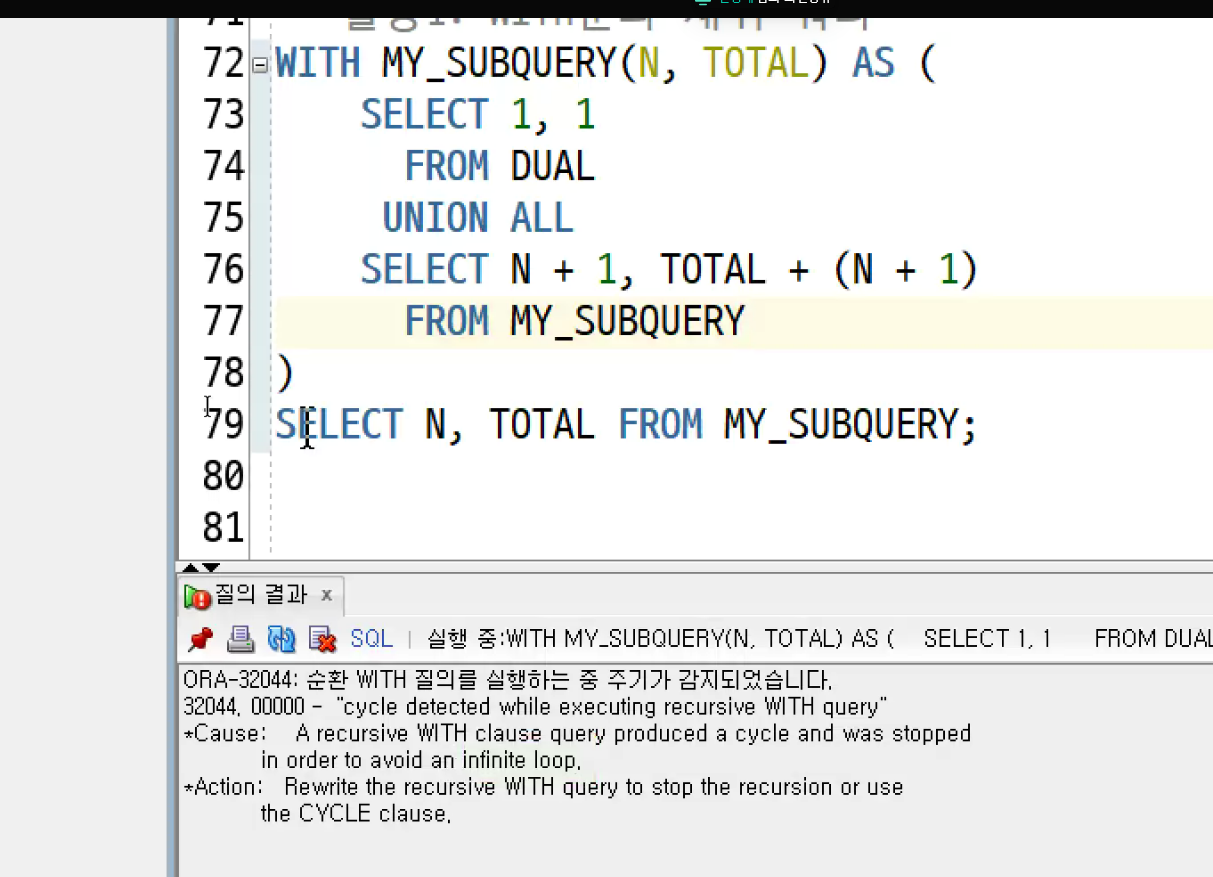
-> 무한루프 빠짐

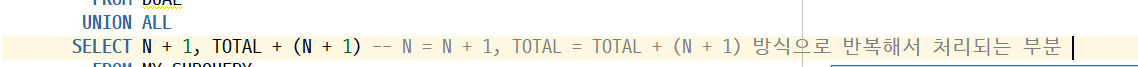
-> 여러번 처리되는 부분
MY_SUBQUERY안에 MY_SUBQUERY가 들어가 있다
★재귀호출(recursive call)(실무에서 볼 수 있는 부분)
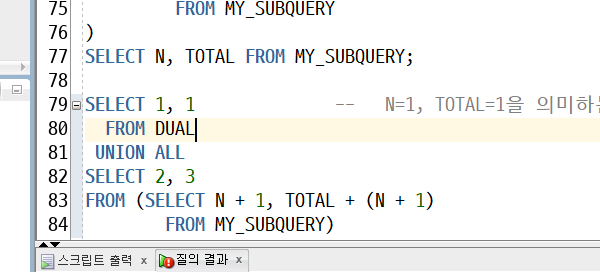
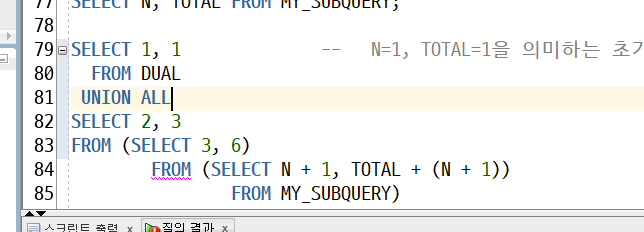
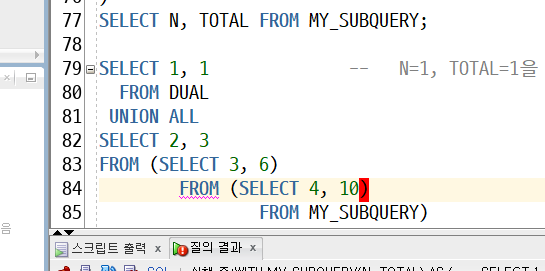
-> 끝없이 계속 출력됨





-> MANAGER없는 사람은 더 올릴 필요 X
UNION 이나 UNION ALL 상관없음(똑같은 사람 많이 나오지 않을 것)
MY_SUBQUERY가 EMPLOYEES가 가지고 있음
LEVELDMS MY_SUBQUERY에서 가지고 오는것
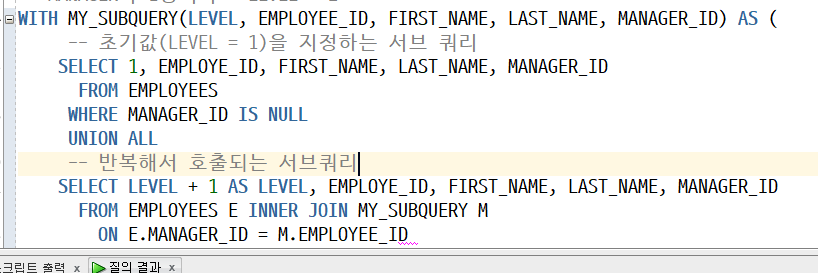

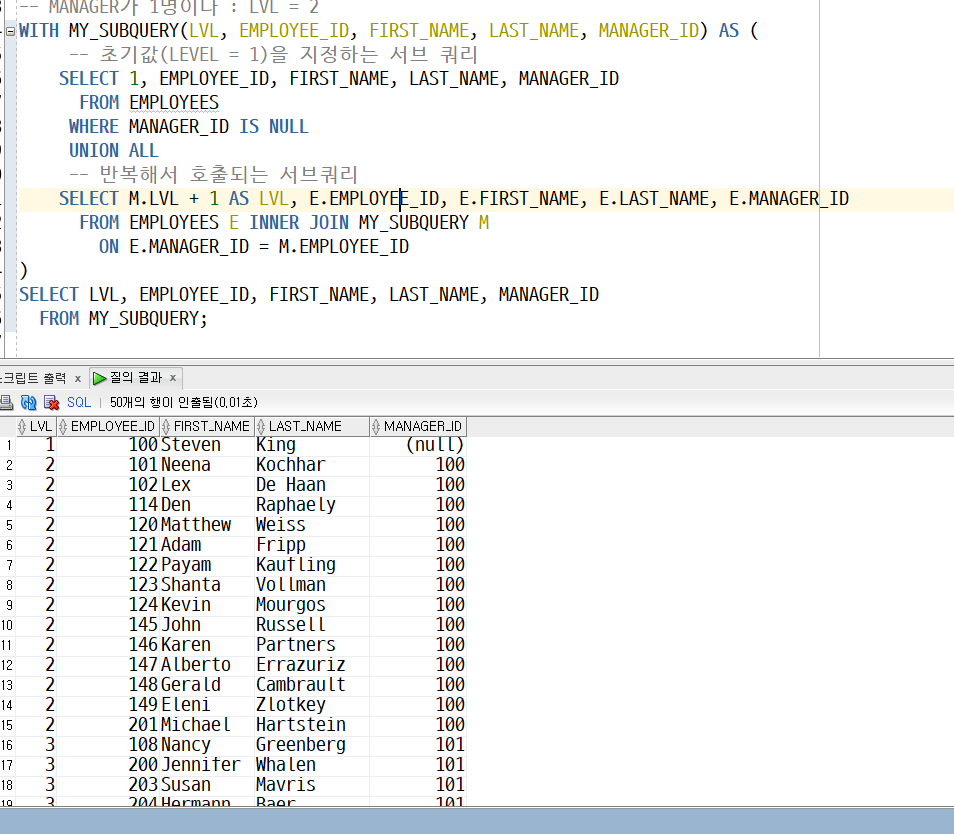
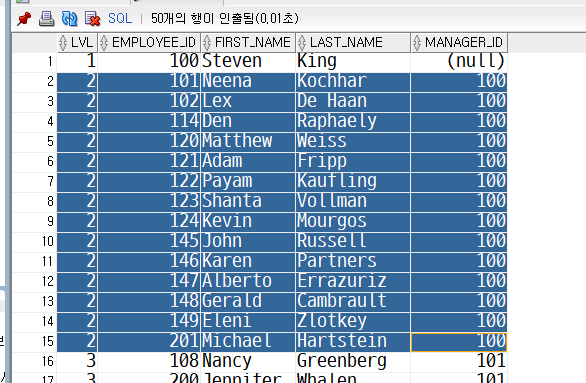
-> LEVEL 2 상사 모두 Steven King
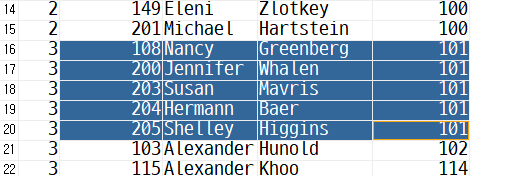
-> LEVEL 3
인덱스(INDEX)
-> 어떤 데이터에 정확한 위치 정보를 가지고 있다는 걸 정리해둔 것
- DB 버퍼캐시 : MEMORY DISC : 반도체 칩 안에서 찾아오는 것 - 굉장히 빠름
-> 캐시 (사용했었던 정보를 저장해두는 영역, 한번 읽었던 데이터:하드디스크에 가서 조회를 했던 정보는 캐시에 넣어놓는다.두번째 조회때는 빠르게 조회할 수 있게끔) - 디스크 파일 : HARD DISC : 하드디스크 - 느림

-access arm 이라는 판이 왔다갔다 하면서 데이터 읽는 방식
-데이터 베이스 : 하드디스크를 기반으로 저장(찾는데 시간이 오래 걸림)
*조회하는 방식(순서)
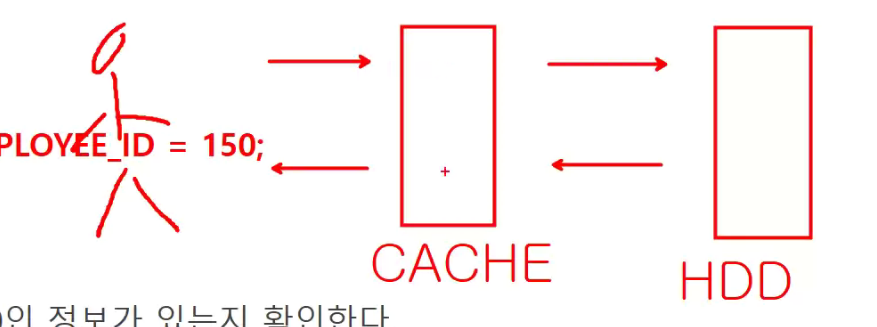

인덱스가 있는 경우 : 150 데이터가 어디에 저장되어있는지 안다.
인덱스가 없는 경우 : 어디에 데이터가 있는지 모른다.
ROWID
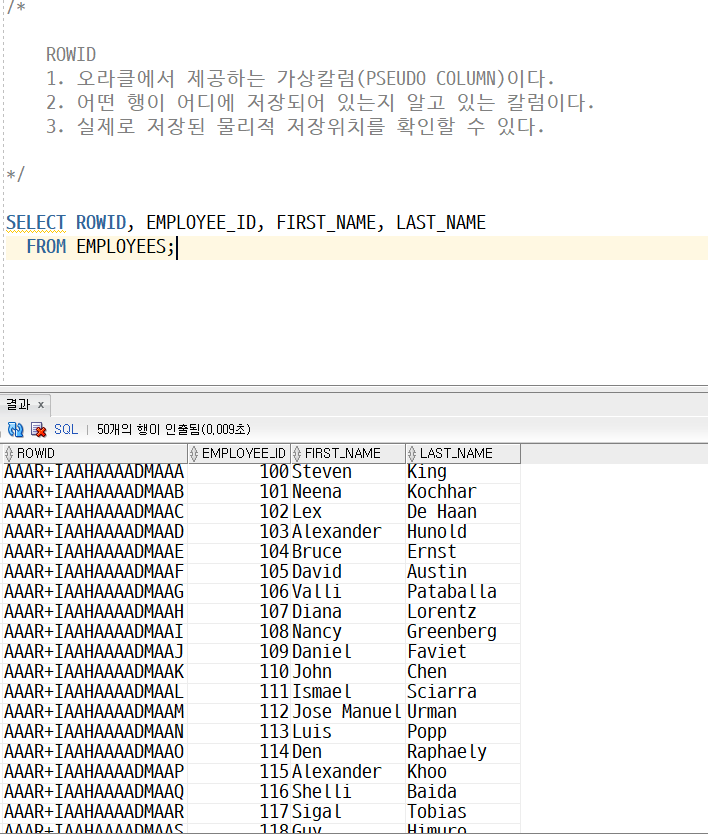
-> 값이 다르다(번짓수 : 해당 지역의 개념을 나타냄)
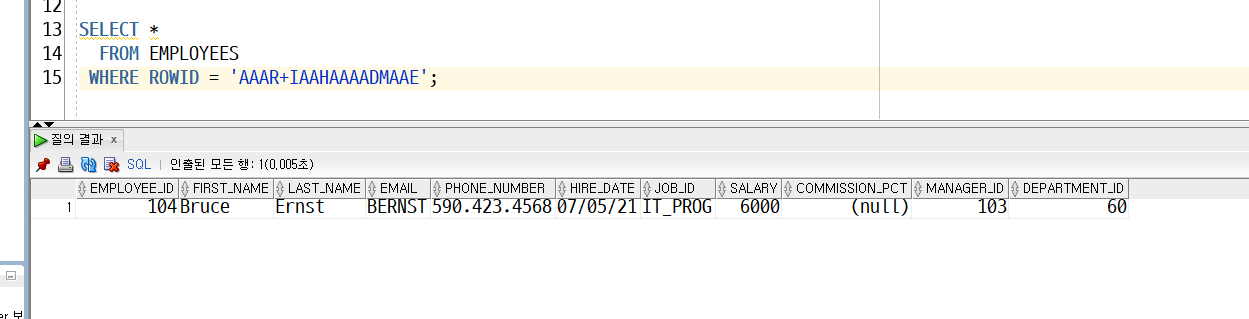

-> ROWID 직접 사용이 불가능해서 INDEX만들어 둠
-> 어떤 데이터는 어떤 정보를 가지고 있다 정리해두고 찾는것 : INDEX

INDEX 사용하면 ROWID를 사용한 것과 거의 같은 효과를 가져온다.
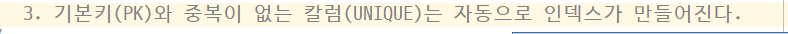
(EX) EMPLOYEE_ID 100, 101은 어디가면 있다는 것이 만들어져 있음
-> 기본키 값으로 SEARCH하면 기본키 ROWID 가지고 그 자리로 바로 감
-> ★ 기본키로 조회할 수 있으면 기본키로 조회를 하기(훨씬 빠름)
★ 조회시) 기본키, UNIQUE로 만들면 좋음

-> 인덱스 많이 만들면 삽입,수정,삭제도 같이 만들어야 해서 전체적인 성능이 떨어질 수 있음

데이터 사전(★ 시험문제)
-메타 데이터 = 카탈로그(정보에 정보를 담고 있는 데이터)
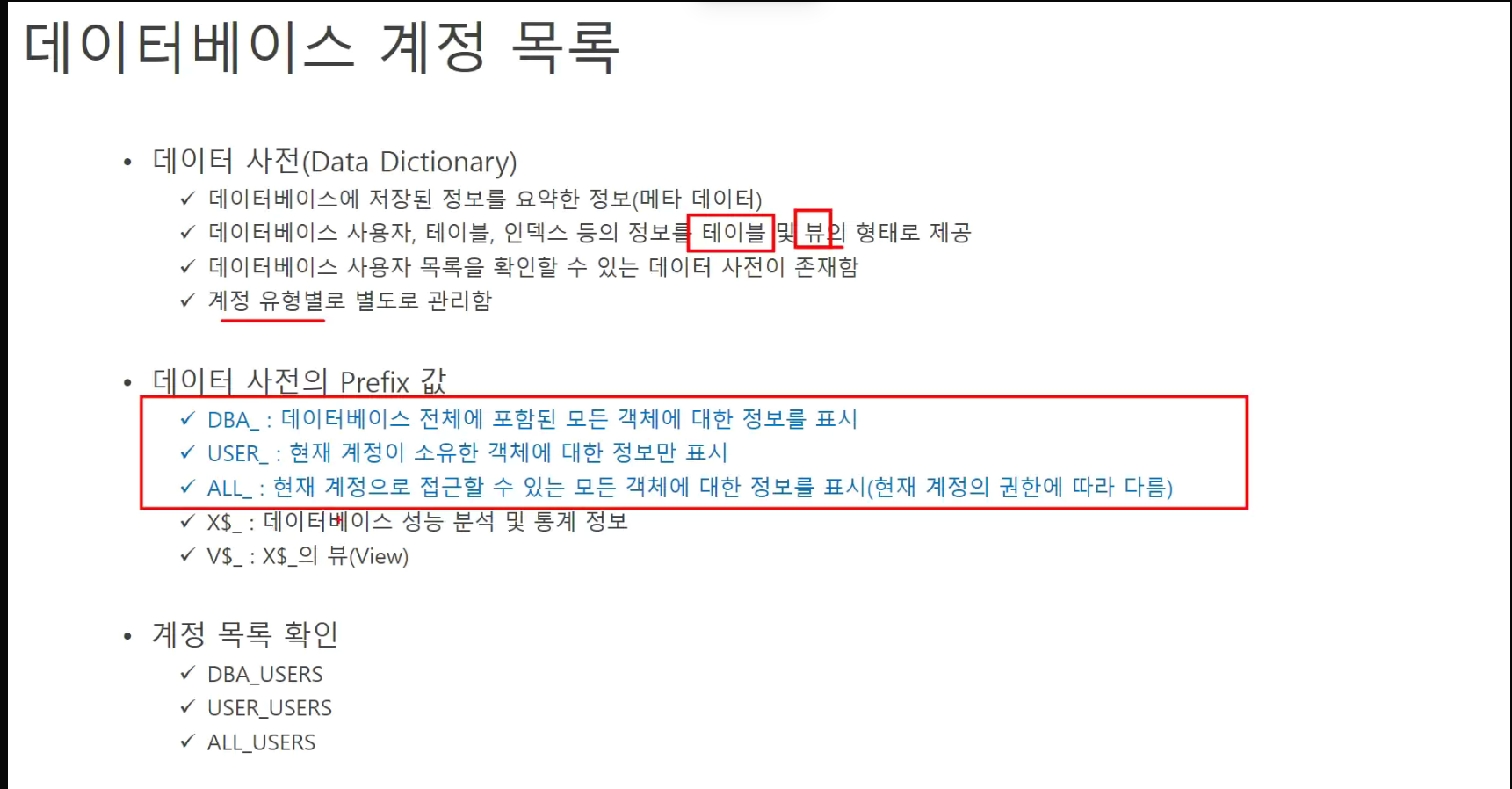
-> Prefix : 앞에다 고정함
-> 데이터 사전의 이름은 3개중 하나로 시작한다(DBA, USER, ALL_)

가장 많은 정보 가지고 있는건 : DBA
가지고 있는 것 : USER
내꺼는 아니지만 볼 수 있는 것 : ALL

-> DBA 나오지 않음 (HR계정이 접근할 수 없어서)
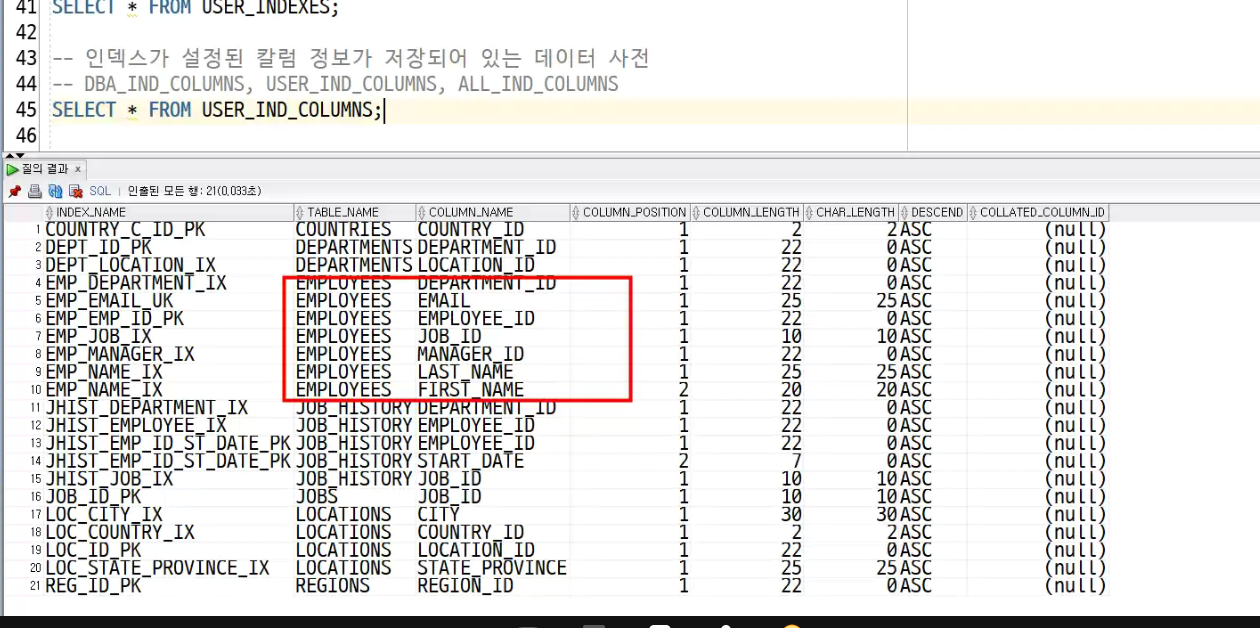
-> 어느 COLUMN에 있는지 명확히 알 수 있음
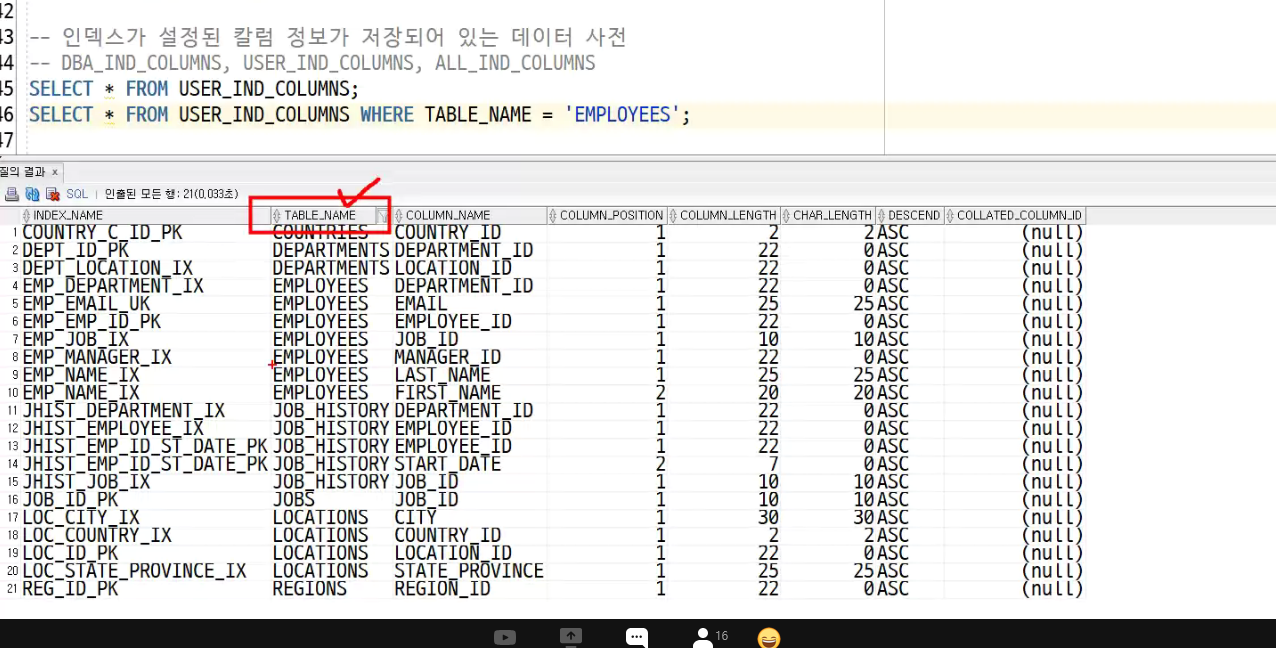
-> 칼럼 이름 확인하기
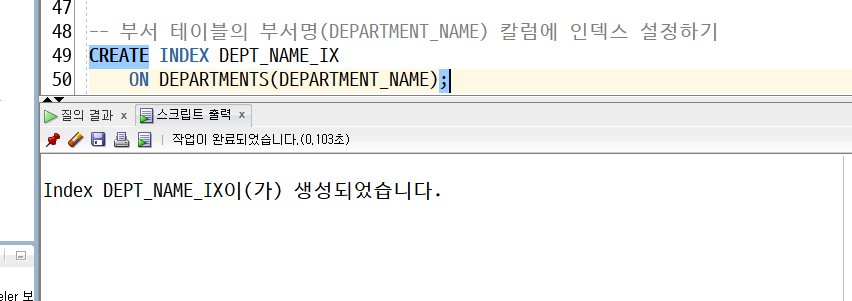
만들어두기만 하면 조회 자체가 빨라짐
(자주 있는 삽입, 수정, 삭제는 INSERT, DELETE, UPDATE) - 되려 느려질 수 있음


->빠른 조회가능

-> 칼럼에 함수를 쓰면 인텍스를 타지 않음
-> 가능하면) 칼럼은 건드리지 말고 맨 뒤로 빼라(= 왼쪽은 건드리지 말고 오늘쪽 가서 하기)
-> 성능때문에
뷰

WITH로 만들어놓은 SELECT그룹을 바로 사용해야 함
-> VIEW는 따로 저장해두었다가 나중에 불러쓸 수 있음

V_ (뷰 이름) -> V_EMP


사원, 부서가 자주 사용되므로 사원, 부서 미리 조인하는 것
-> 사원, 부서는 앞으로 조인할 필요가 없는것 (V_EMP 가져가 쓰면 됨)

-> 사실은 3개짜리 조인
-> 가독성이 높아짐

복잡한 쿼리일수록 뷰로 만들어놓으면 편함

<보충> - 고급 응용 파트 텍스트(7/12수 ,7/13목)
PLSQL
-> 오라클에서 IF문 쓰거나 FOR문을 쓰거나 할때) : PROCESSER(프로시져), 상용자 함수, TIRGER(트리거)
자바
-> 자바문법
-> JDBC - JAVA DB CONNECTION(연결하는 과정)
-> 공공데이터API(자바만 가지고도 확인가능)
8/11/금 종료 목표
WEB
FRONT 1개월
(2달 후)
BACK DB, JAVA, WEB FRONT (모두 섞어서 들어감)
JAVA 11 버전
JAVA 1.8 이상이면 문제 없음(서버에 깔린 자바가 무엇인가?)
