[SQLD 특강]
35~40개
[https://gd-edu.gitbook.io/sqld-2/]
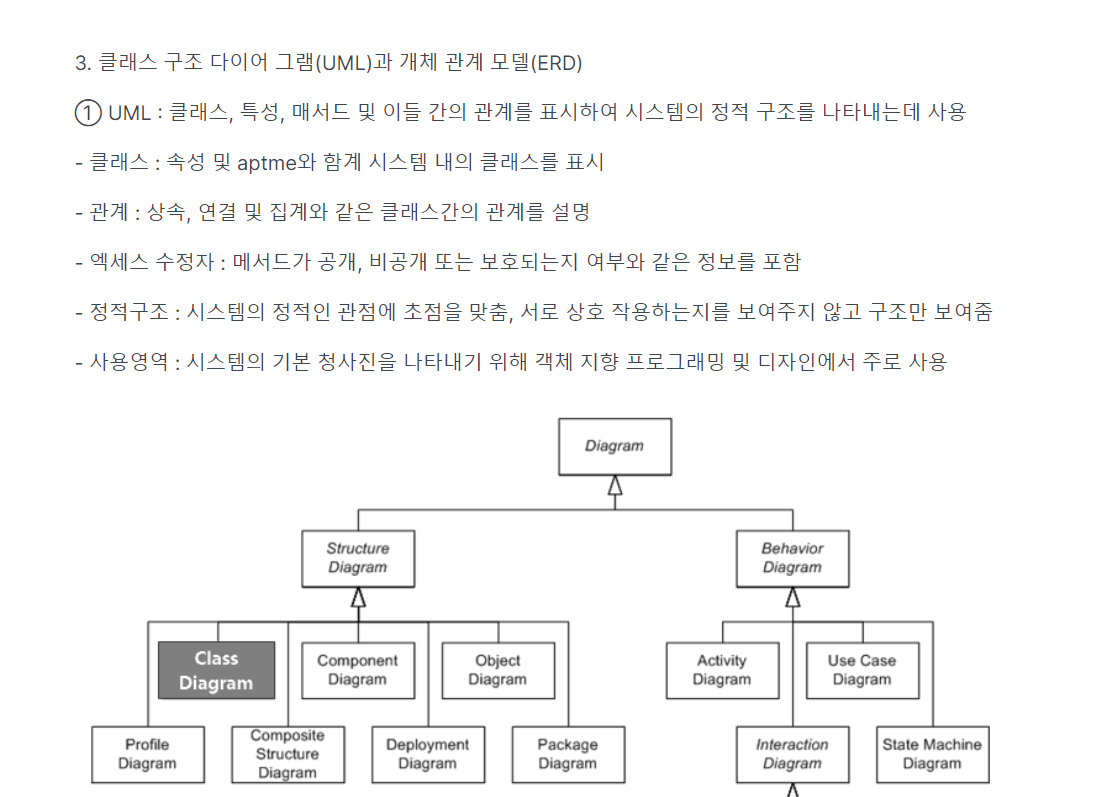
1. 데이터 모델링
- 1시간 30분
- 5분(OMR 마킹시간)
-> 80분안에 50문제 풀어야함(1분 20~30초)
-> 데이터 모델링의 특징 : 1. 추상화 2.단순화 3. 명확화
(X) 이상화

-> 개념적 모델링 : 추상화, 논리적 모델링 : 재사용성 높음, 물리적 모델링 : 모델링

-> 객체지향언어는 유연성이 떨어짐(하나 고치면 다른애도 고쳐야함)
-> 비유연성 - 분리, 비일관성 - 명확한 정의

-> DB 정의서
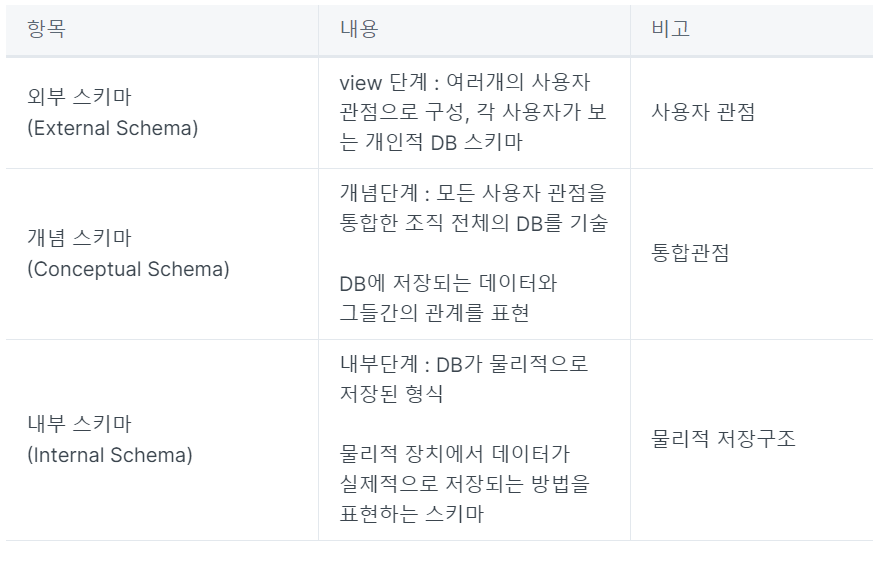
-> DB의 입장에서 한단계 위 : 통합관점, 그 위: 사용자 관점
-> 사용자가 한명한명 보는 것 : 외부스키마, 모아서 보는것 : 개념, DB에 넣는것 : 내부 스키마(DB 물리적 저장구조)
★ 긴문제는 넘기고, 10초컷 할 수 있는 문제 먼저 풀기!
★20문제 풀어도 됌

-> 2 ( 모델링의 특징 : 추상화, 단순화, 정확화)

-> 3 ( 2 : 컴퓨터에 넣어야 함 )
★ 헷갈리면 넘기고 다음것 읽기 (제거해나가면서 정답확률 높이기)


-> 3 (1.데이터 중복최소화 2.분리 (유연성) 4. 일관성)
-> 상충되는 것) 2. 데이터의 사용 프로세스 분리 <-> 3. 프로세스나 장표 등에 따라 매핑이 될 수 있도록 연계성을 높임
-> 2(프로세스 분리 - 비유연성)

-> 2(추상화수준 높음 -개념적, 물리 - 물리적)
-> 논리적 : 재사용성이 높다
-> 2 (3단계 구조 : 스키마) ,** 통합 -> 개념스키마
-내부(DB), 외부(사용자) , 이걸 모은게 - 개념(통합) **
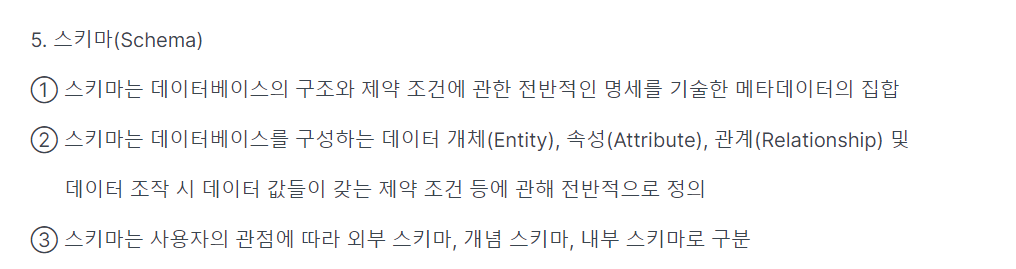
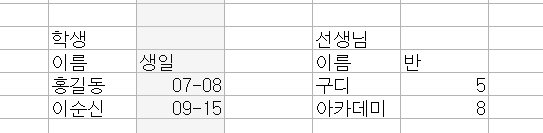
2.엔터티(Entity)


-> 속성 : 컬럼
-> 학생 테이블 : 학생이름 , 학생 생일
-> 속성이 2개 이상이어야 함(속성값 1개)
-> 인스턴스 : 행
테이블 : 물리적, 엔터티 : 논리적
-> 독립적 생성(학생,선생님) : 역할을 받아서 하는게 중심엔터티
-> 결과로 나온게 행위 엔터티

-> 학생들 (x) : 학생
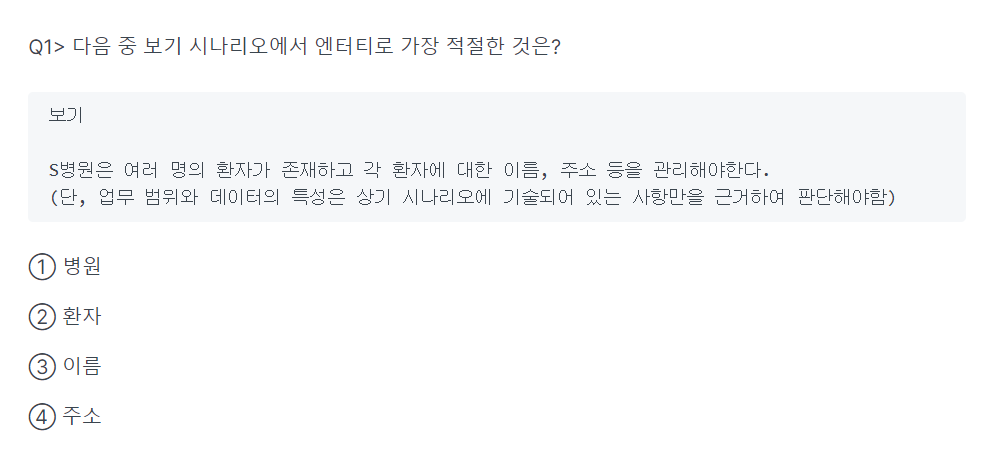
-> 2 (병원 : DB, 환자 : 엔터티(테이블), 이름, 주소 : 속성)

-> 3(한개의 인스턴스를 가지는 것만으로도 충분한 의미를 부여X)
-> 지식 추가) 통계성 엔터티나 코드성 엔터티의 경우 관계를 생략할 수 있다.
★ 기출문제 : 많이 풀기

-> 1(관계를 가진다)

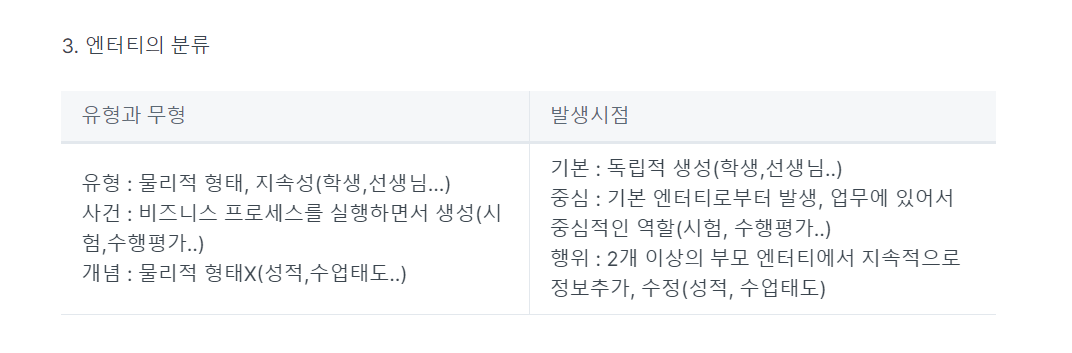
-> 1(기본 : 학생, 선생님, 중심 : 시험, 수행 , 행위: 성적, 개념 : 유형/무형)

-> 1
3.속성(Attribute)

-> 파생 : 학생 이름 순대로 번호를 매김
-> 파생 : 계산

-> 1개의 속성값을 가진다


-> 속성

-> 3(속성값은 한개만 가질 수 있음)
★ 시험칠때 : 시험문제 내용도 많이 활용하기(보기로 나올 수도있음)

-> 원금,예치기간, 이자율(셋이 관리: 기본속성)
-> 계산된 이자(파생)
-> 일반예금, 특별예금에 대해서 코드를 부여(설계)
1.01 코드값만 넣으면 됨
3. 이자율(x) 이자만 파생임
-> 3번

-> 1(파생 - 계산)

-> 3(동일한 속성명을 가지면 연관되어있는것처럼 보임: 좋지않음)
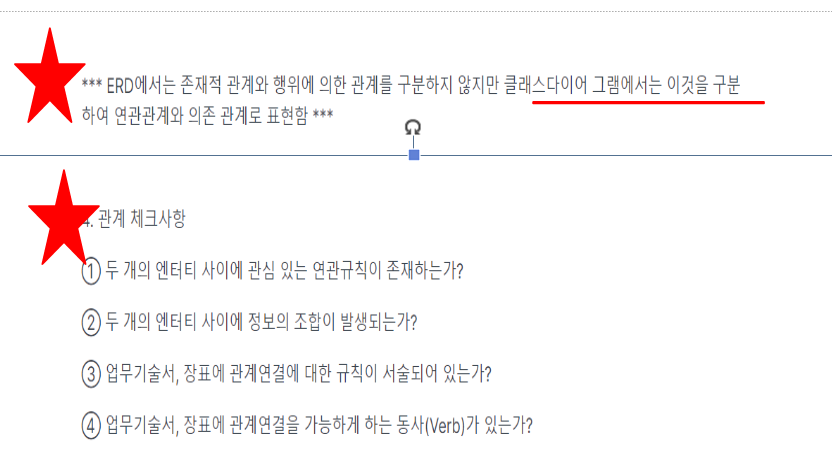
4.관계
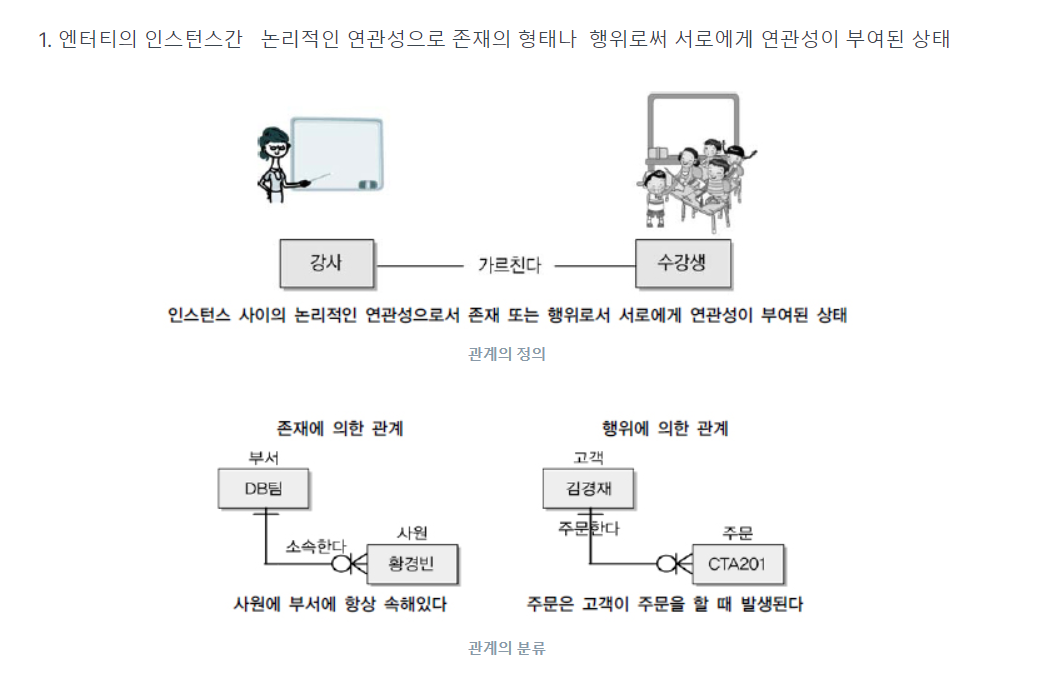
★★★IE표기법 외우기
-> OR로 생각하기
1-----O1 : 1대 0대이거나1
1-----O< : 1대 0개 이거나 다수
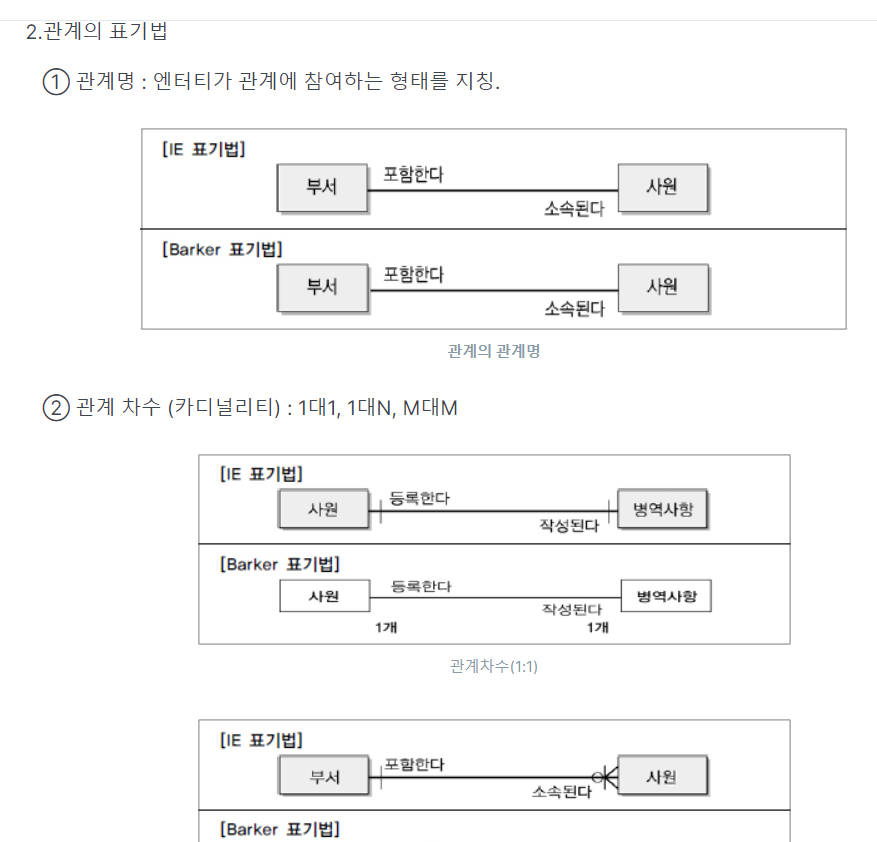
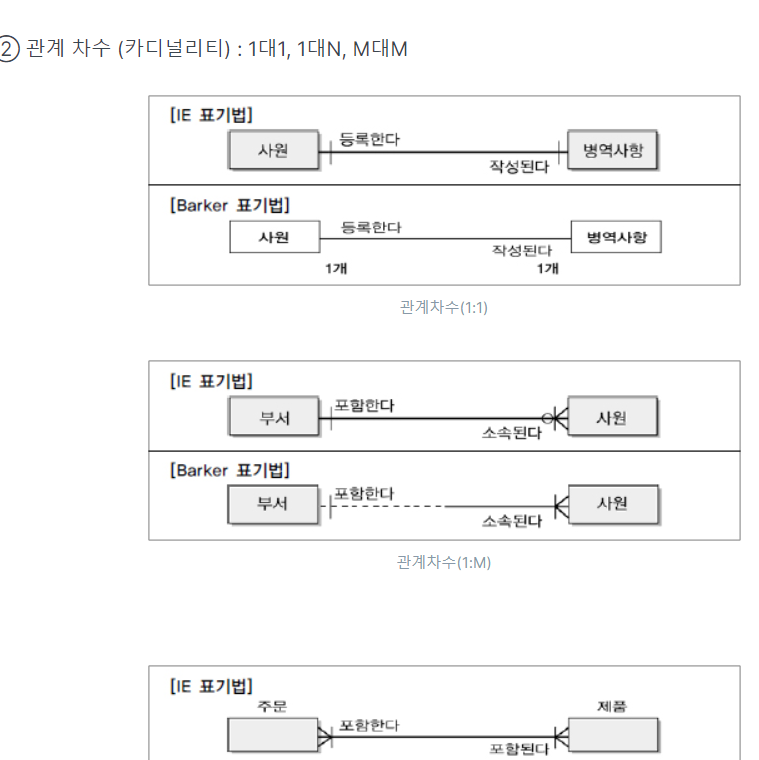
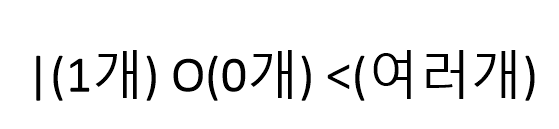
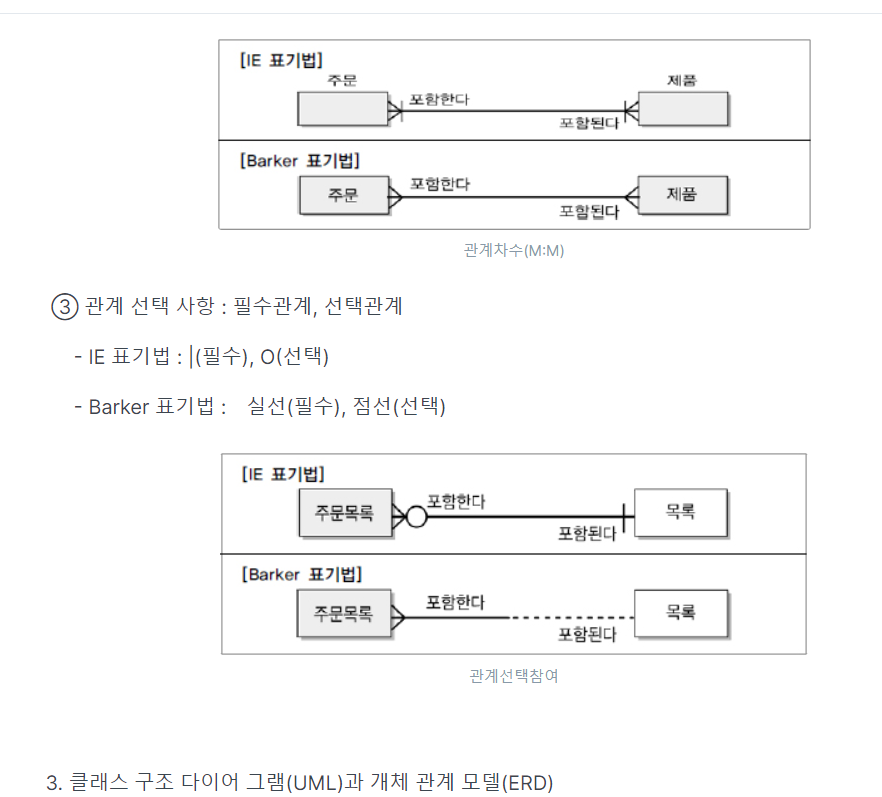
★★(관계명, 관계차수, 관계 선택사항)
★★표기법

-> 표기법이 다른것만 알면됨(안에 세세히X)

-> 1,2 묶어서 외우기, 3,4 묶어서 외우기

-> 속성값 : 도메인

-> 3,4
->★ 묶어서 보기(하나 맞으면 하나 무조건 틀림)
-> 다음중 부정적인 것 2개를 고르세요 (14 중 한개 23중 한개)
(있고, 있으나)

-> ★★★2(관계명, 관계차수, 관계 선택사항)

-> 2, 3(동사)
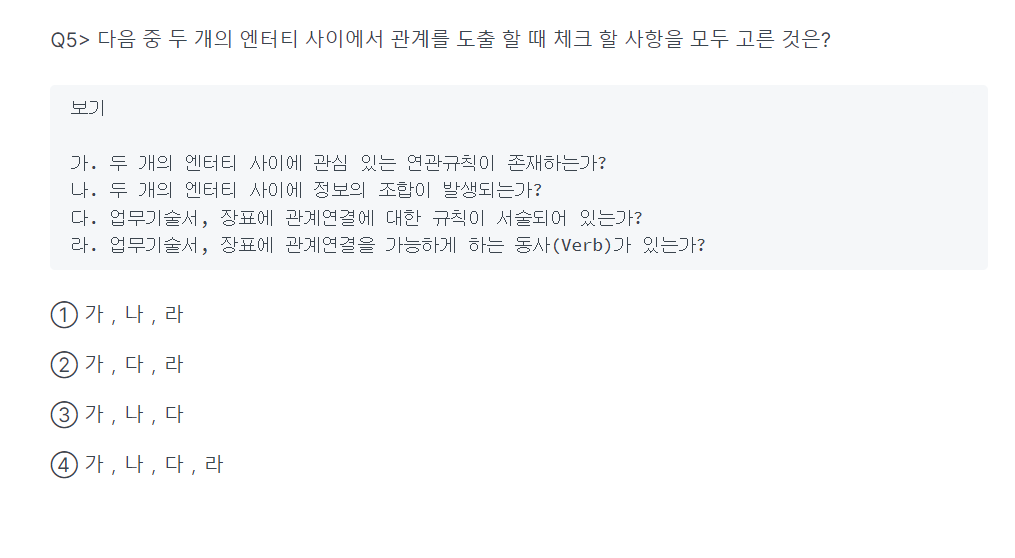
-> 4번(연관규칙, 조합, 규칙 서술, 동사)
5. 식별자

-> 한개로 끝낼 수 있는데 굳이 2개로 만들지 않음
->사번으로 primary key하겠다

-> 부모의 주식별자가 자식의 주식별자로 위임되는것
: PK -> PK(FK) : 강한관계
: PK -> PK(다른 속성값으로) : 약한 관계
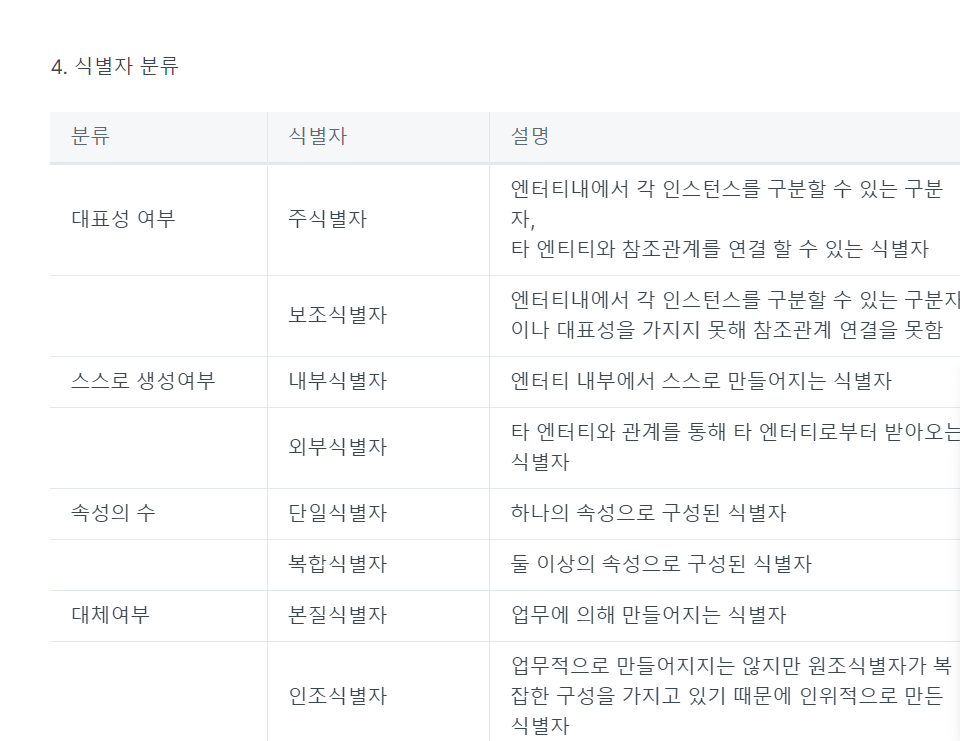
-> 주민번호 : 내가 살고있는 거주지 뽑기가 힘듦
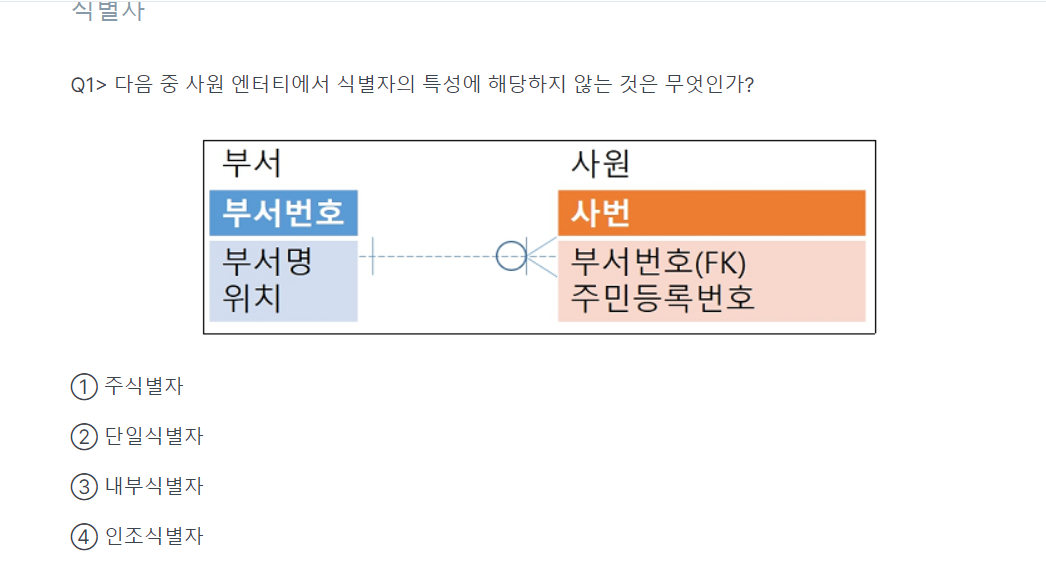
-> 4(인조식별자:주민등록번호에서 거주지만 뽑아낼때)
주식별자(사번), 단일식별자(사번오렌지), 내부식별자(주민등록번호)
-> 점선: 약한관계, 실선 : 강한관계
-> 1개 없을수도있고 한명있을수도 여러명 있을수도

-> 2 (나머지 : 웬만해서 겹치지 X 위에 것 : 자주 변하거나 중복되는값 피하기)
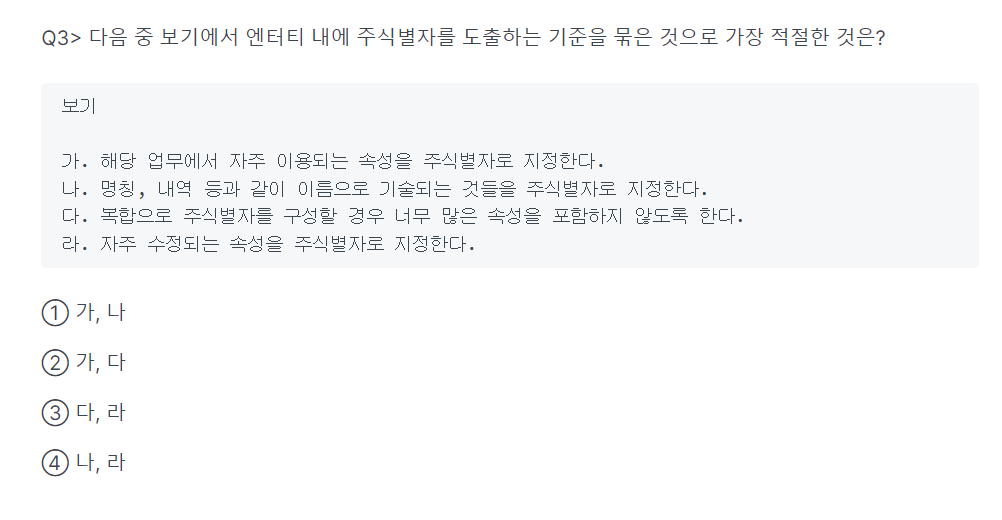
-> 가 나.(X) 다 라(X)
-> 2(가,다)

-> 4 (식별관계 :강한관계 포용, 비식별자관계: 약한관계 손만잡고)

-> 3번
1. 부모없이도 나 혼자 살수 있음
2. 식별관계
3,4 여러개의 주식별자를 하나로 뭉치지 않음(따로 주식별자를 만들던가 함)
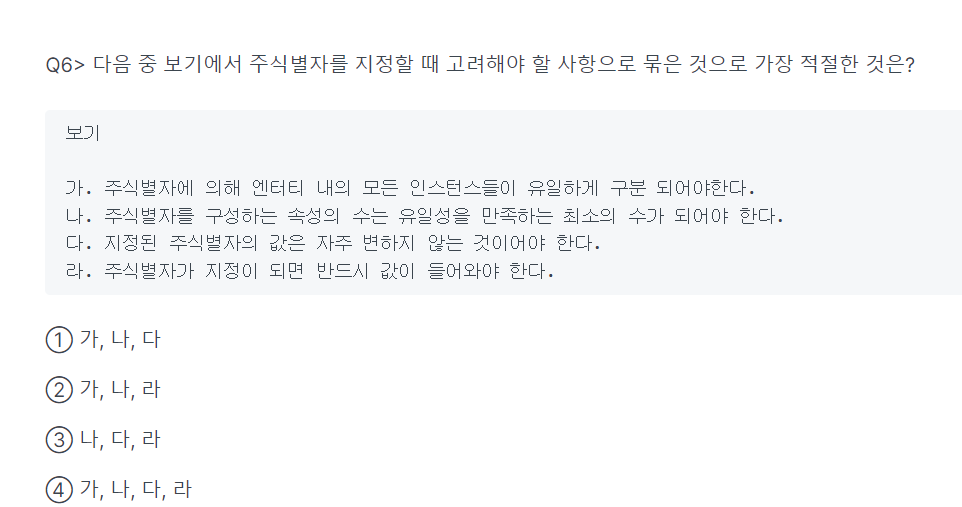
-> not null(값이 들어와야함)
-> 4번
6.ERD
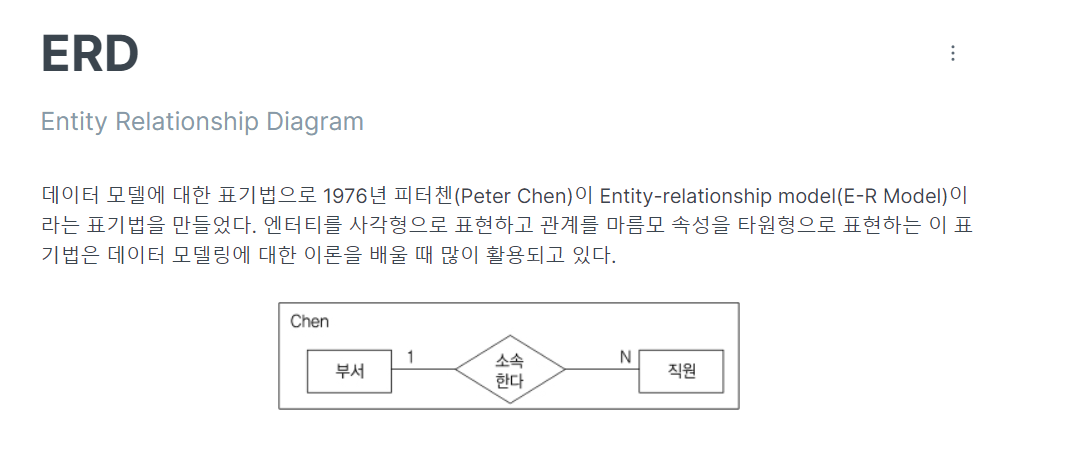
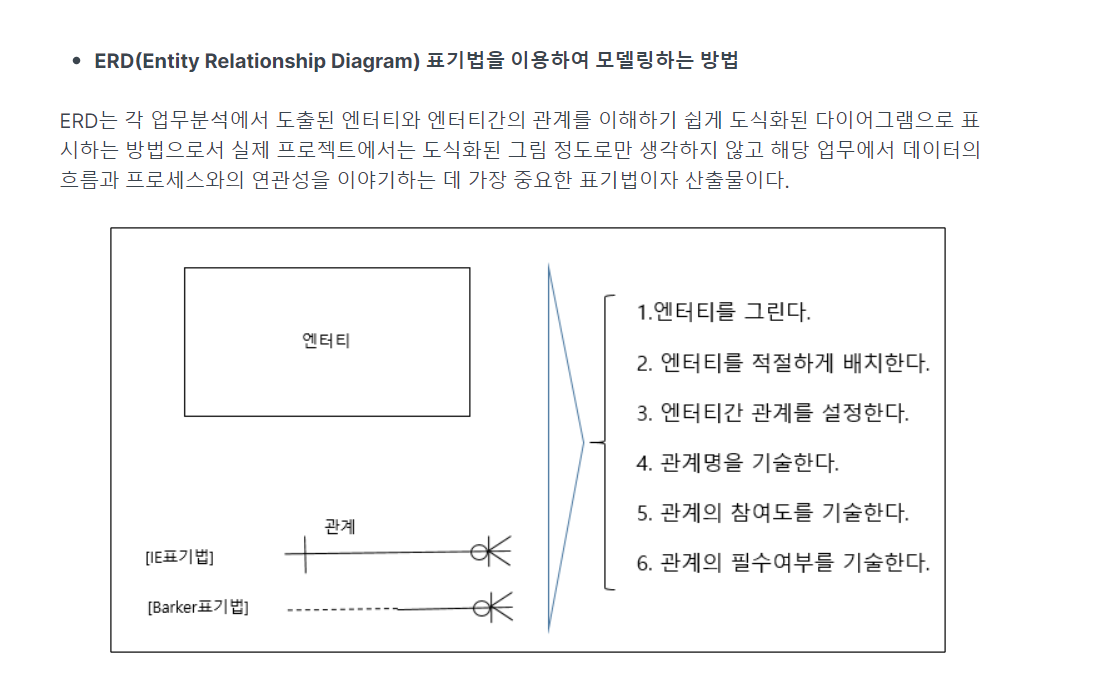
-> ★ 순서 : 3개씩 묶어서 외움(123/456)
-> 엔터티/필수여부 나눠서 외우기 (3번째 관계, 4번째 관계)
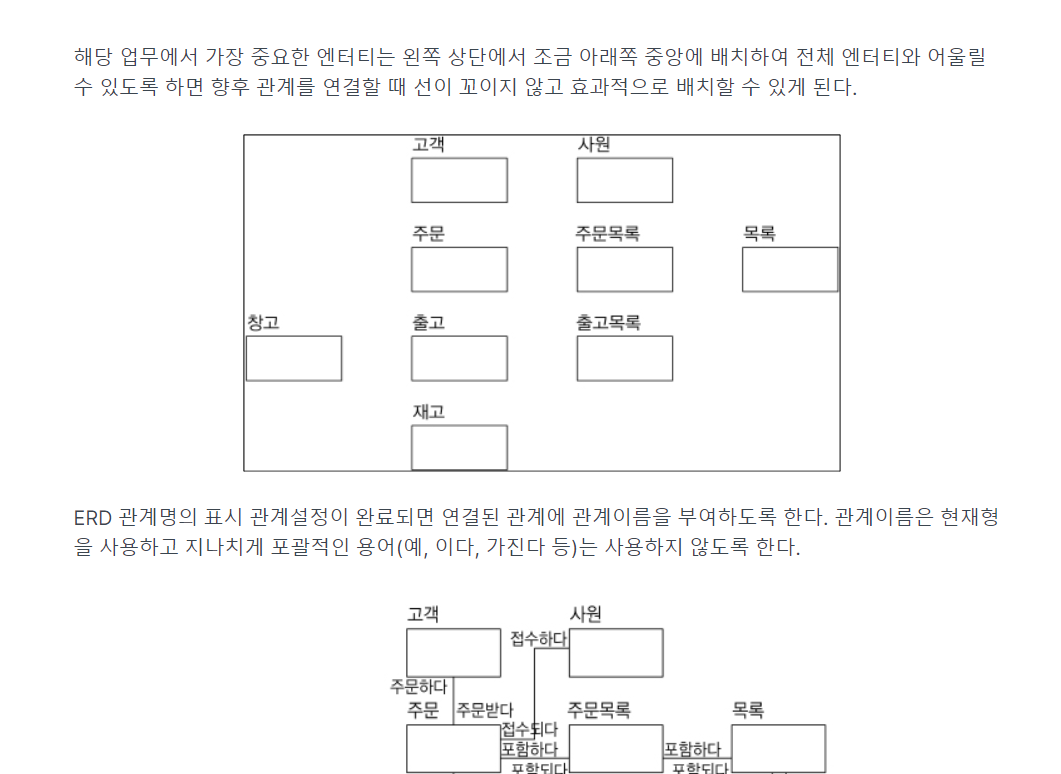

-> 4번(O 주문없어도 됌)

-> 4번(가장 중요한 엔터티 : 왼쪽 상단)
데이터모델과 성능

-> 4. 논리적인 테이블(주형식) -> 물리적인 테이블(물리적)
-> 분석 /설계 단계에서 해야함( 건물지을때 설계도에서 건물을 테스트 해봐야함)
-> 건물 다 짓고나서 평가 X(설계 단계에서 해야 비용이 최적화됨)

-> ★★(외우기) 정규화 1, 4번 먼저 외우고, 6번 성능관점,
-> 정규화, 반정규화 사이에는 2,3번 DB가 들어감

-> 1(성능단계에서 끝내야함)
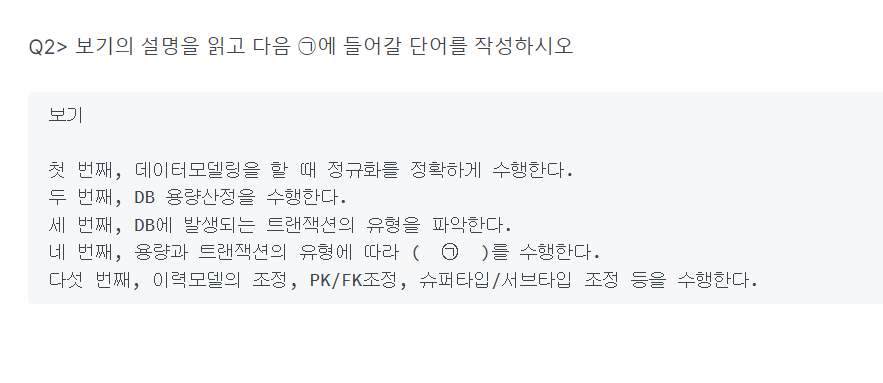
-> 반정규화

-> 4
(1 정규화 4 반정규화 마지막 성능관점)

-> 1(항상 키워드 : 80% 틀린것으로 보기), 4(입출력 내역을 계속 지키면 사라지지 X , 테이블로 계속 만들면 칼럼이 계속 커짐)
-> 정규화 : 성능향상을 위해서 하는데 성능저하가 되는 경우가 있음
8.정규화

★ (정처기단골) 삭제이상 :연관된 애들 삭제, 삽입이상, 수정이상

-> 주민번호만 알면 이름, 출생지를 알수 있다(어떤값을 알면 다른값을 알 수 있음)
(주민번호) -> (이름, 출생지)
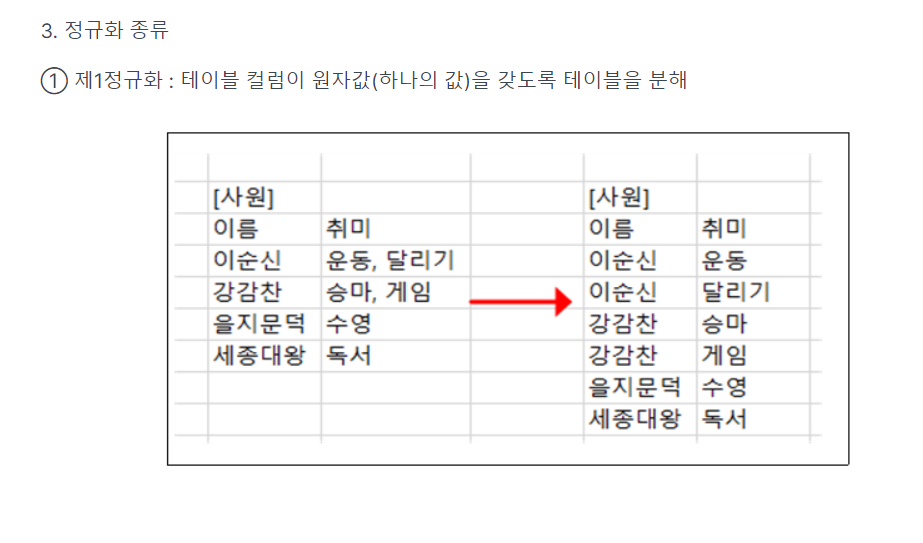
-> 1정규화 : 원자값(하나의 값)을 갖도록 테이블을 분해
(cf) 정규형 : 원본테이블을 1차정규화를 거쳐서 1차 정규형이 되는것!
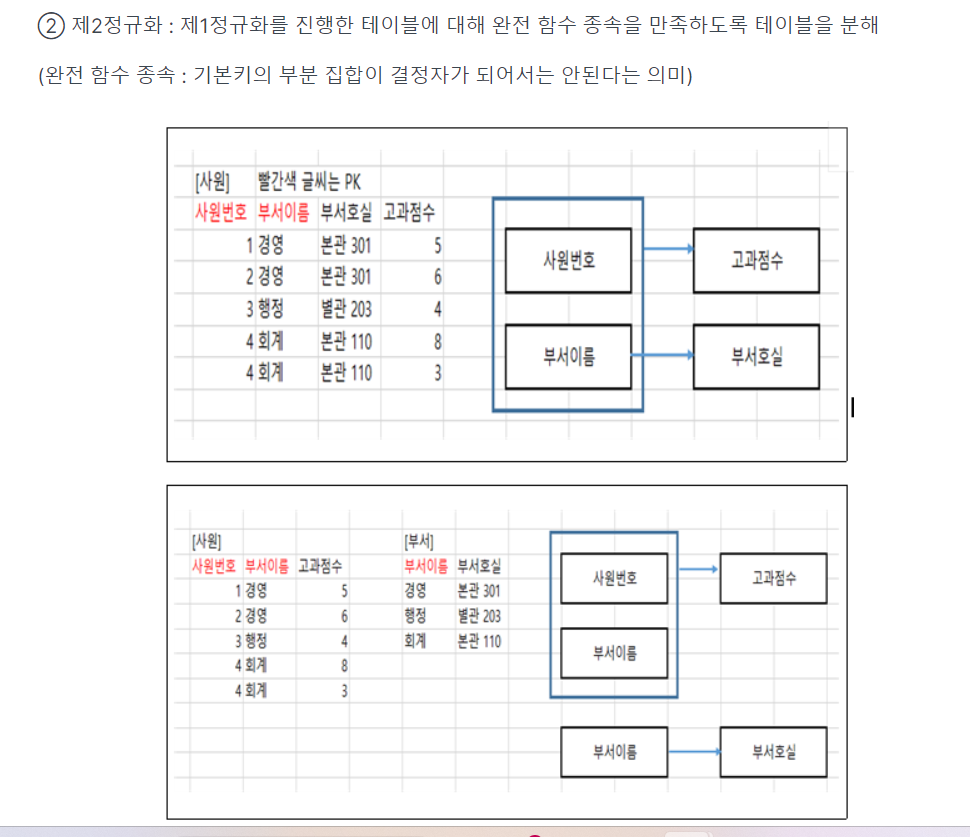
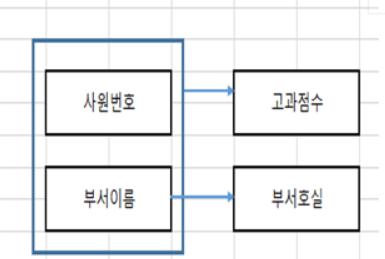
-> 2차 정규화 : 1차 정규형(테이블)에 대해 완전 함수 종속을 만족하도록
★★★(외우기) 부서이름->부서호실을 또 만듦
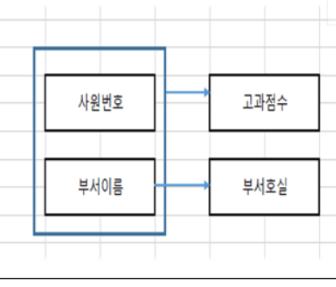
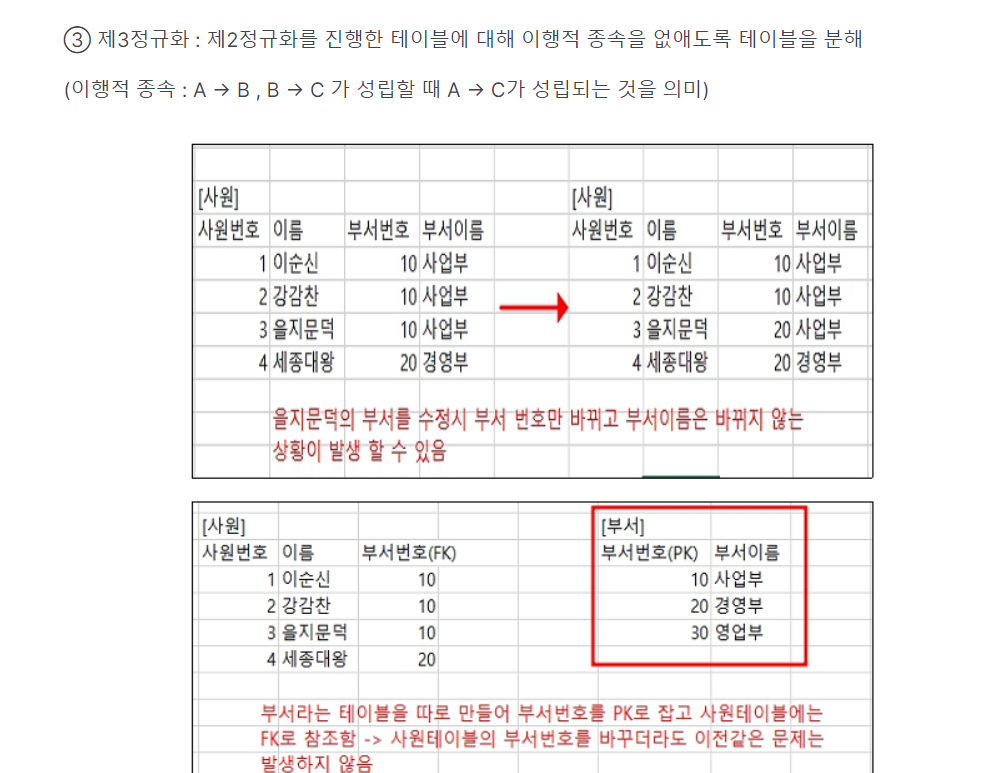
-> 3정규화: 3단논법

-> 함수종속성(FD) : 2차정규화 필요한것
(작은 네모를 그대로 빼서 -> 세모 테이블을 만듦)

-> 3번(이걸빼서 만듦)
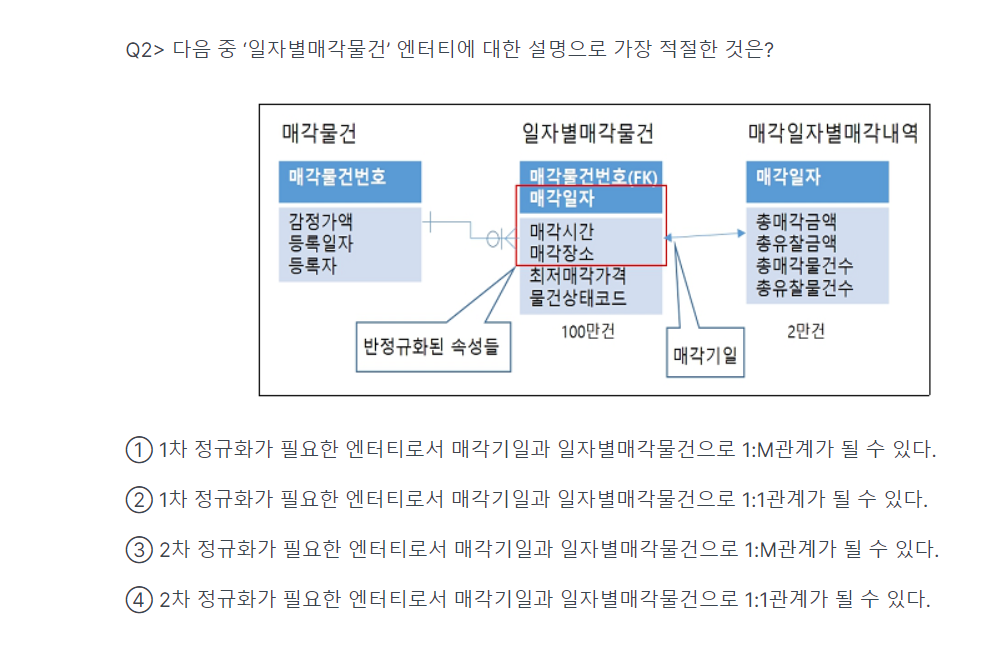


-> 3번


(각각 필터링 할 수 있음)
-> 4번(정규화하고 안정화되었을때 인덱스 생성하는것이 좋음)

-> 1번
-> 1차정규화해서 1차 정규형을 만드는 것
-> 컬럼도 1차 정규화의 대상임
-> 1대1이 될수가 없음

-> 1번
반정규화와 성능




-> 1.1번 빌링의 잔액(계좌에 남은 잔고)(잔돈은 입출금이 계속 있음), 4번(주소테이블 -> 자기가 원하는 정보를 가져다가 붙이면 됨)
-> ★ 키워드 잡고 틀린거(2,3,4) 외우기(문제자체가 나올수도 있음)
(2 성능저하를 피할 수 있는 경우가 있음)
-> 2.4번

-> 3번 컬럼에 FK(부모테이블로부터 받은것) 나오면 틀린것!
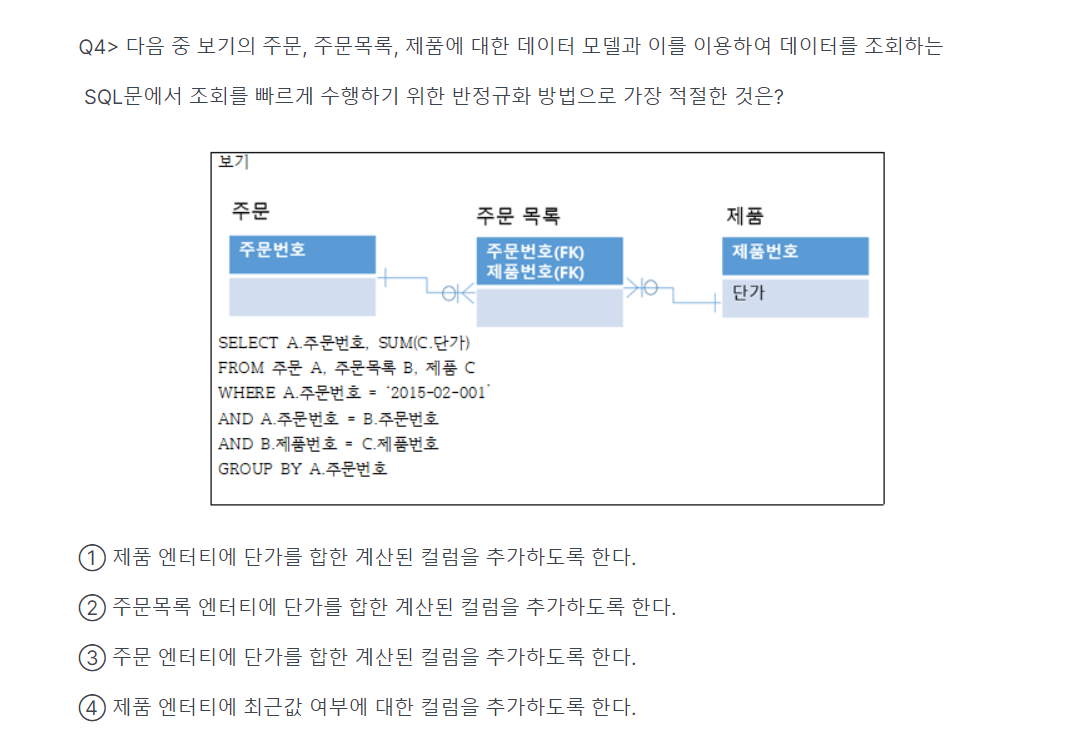
-> 쿼리문 볼때 : FROM먼저 봄(조인 2번)
-> 3번
★외워두기!
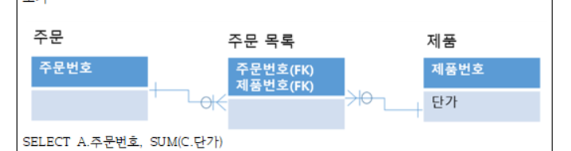

-> 파생 => 계산
(SUM(C,단가)) -> 계산
SUM 단가 (SELECT A 주문번호, SUM(단가) FROM 주문 A)
