자료구조
- 자료구조(Data Structure) : 여러 데이터들의 묶음을 저장하고, 사용하는 방법을 정의한 것
자료구조는 자료(데이터)를 다루는 구조 그 자체를 뜻하며, 구현하는 방식에는 제약이 없습니다.
자료구조는 자료의 집합을 구조화하고, 이를 표현하는 데에 초점이 맞춰져 있습니다. 사람이 사용하기에 편리하려고, 사용하기 좋으려고 만들어진 것이 자료구조입니다.
- 데이터(data) : 문자, 숫자, 소리, 그림, 영상 등 실생활을 구성하고 있는 모든 값. 우리의 이름, 나이, 키, 집 주소, 목소리 혹은 유전자 DNA까지 데이터로 분류할 수 있습니다. 그러나 데이터는 그 자체만으로 어떤 정보를 가지기 힘듭니다. 예를 들어 나이라는 데이터만 알고 있다면, 사람의 나이인지, 강아지의 나이인지, 나무의 나이인지 알 수 없습니다.
- 데이터는 분석하고 정리하여 활용해야만 의미를 가질 수 있습니다.
- 필요(목적)에 따라 데이터의 특징을 잘 파악(분석)하여 정리하고, 활용해야 합니다.데이터를 정해진 규칙없이 저장하거나, 하나의 구조로만 정리하고 활용하는 것보다 데이터를 체계적으로 정리하여 저장해두는 게, 데이터를 활용하는 데 있어 훨씬 유리합니다.
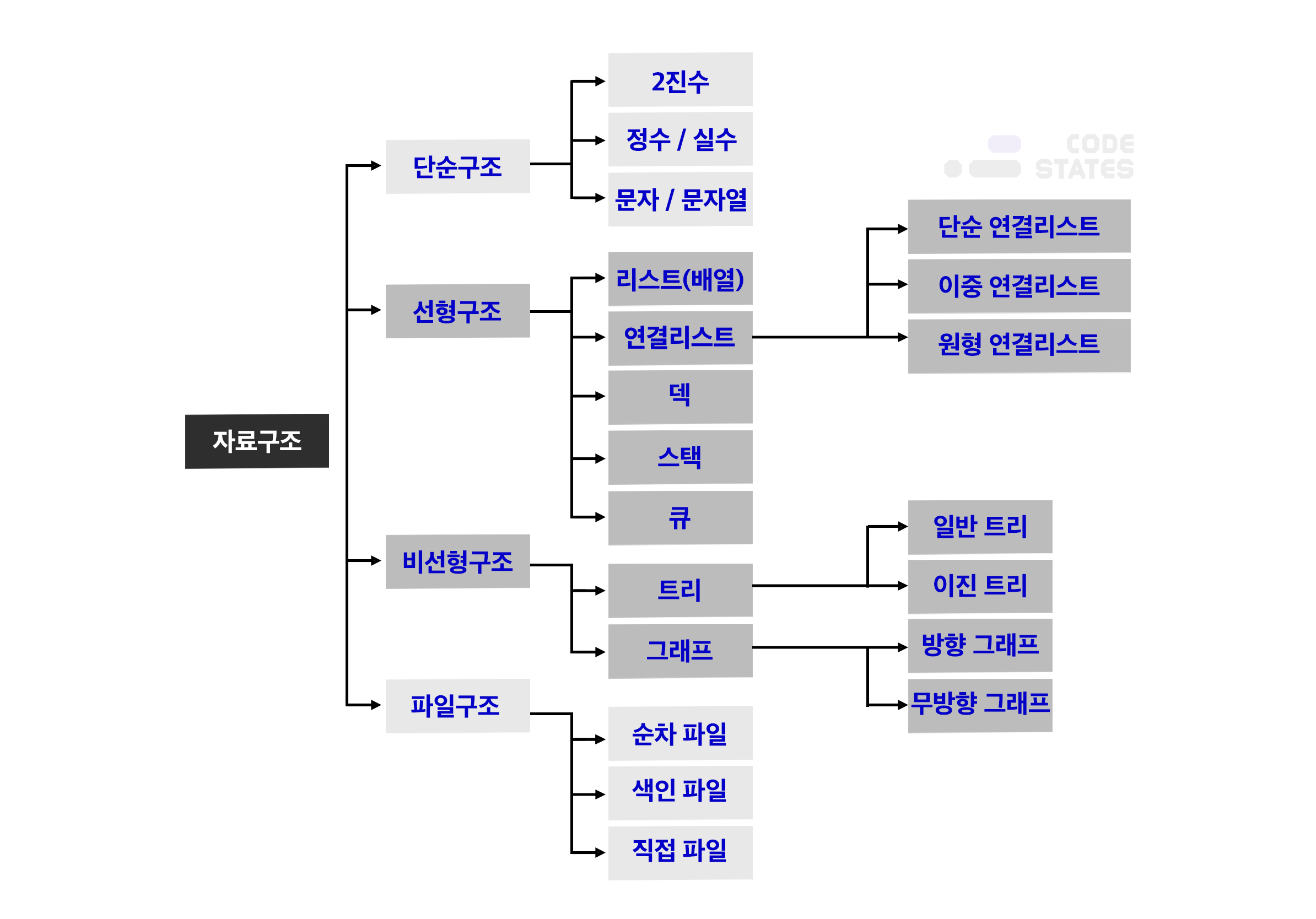
[그림] 자료구조의 종류와 구분
- 자료구조 : 무수한 상황에서 데이터를 효율적으로 다룰 수 있는 방법을 모두 모아 이름 붙인것. 우리는 이 많은 방법 중에서, 가장 많이 쓰이고 알고리즘 테스트(코딩 테스트)에 자주 등장하는 네 가지의 자료구조 (Stack, Queue, Tree, Graph)
- 대부분의 자료구조는 특정한 상황에 놓인 문제를 해결하는 데에 특화됨.
: 많은 자료구조를 알아두면, 어떠한 상황이 닥쳤을 때 적합한 자료구조를 빠르고 정확하게 적용하여 문제를 해결할 수 있습니다. 이것은 문제 해결력을 필요로하는 알고리즘 테스트(코딩 테스트)와 굉장히 밀접한 연관성이 있습니다. 특정 문제를 해결하는 데에 적합한 자료 구조를 찾아 데이터를 정리하고 활용할 줄 알면, 상황에 가장 적합하고 정확한 코드를 작성할 수 있습니다.
- 대부분의 자료구조는 특정한 상황에 놓인 문제를 해결하는 데에 특화됨.
Stack / Queue - 배열이용
Sprint Roadmap - 스택(Stack), 큐(Queue)
: 자료구조는 배열(Array)입니다. 데이터를 순서대로 쭉 나열하여 저장한 배열이라는 자료구조의 특징과 활용 방안과 비슷.
이 유닛의 핵심은 다음과 같습니다.
- 각 자료구조가 가진 특징을 학습한다.
- 각 자료구조를 사용하기 적합한 상황을 이해한다.
- 다른 자료구조와의 차이점을 이해하기 위해 자료구조 내부를 직접 구현한다.
- 자료구조를 구현하며, 자료구조의 동작원리를 이해한다.
- class 키워드를 사용하여 자료구조의 데이터 타입을 직접 정의.
이 과정에서 필요한 속성과 메서드를 학습.
// class 키워드의 예시 Person 클래스
class Person {
consturctor(name, hand, foot) {
this.name = name
this.hand = hand;
this.foot = foot;
}
speak() {
return `저는 ${this.name}입니다.`
}
}
const kimcoding = new Person('김코딩', 2, 2);
console.log(kimcoding.speak()); // '저는 김코딩입니다.'- 자료구조를 활용해 알고리즘 문제를 풉니다.
: 알고리즘 문제를 마주했을 때 문제를 풀기에 적합한 자료구조를 파악하고, 그에 알맞게 자료구조를 사용해야 합니다.
- 테스트에 걸리는 시간을 단축하고 알고리즘 문제 풀이에 집중하기 위해, JavaScript에서 제공하는 배열(Array)과 같은 데이터 타입을 이용해 자료구조의 형태와 유사하게 구현하여 문제를 해결합니다.
Stack

가장 먼저 들어간 자동차는 가장 나중에 나올 수 있습니다. 다시 말해, 가장 나중에 들어간 자동차가 가장 먼저 나올 수 있습니다.
- 자료구조 Stack의 특징은 입력과 출력이 하나의 방향으로 이루어지는 제한적 접근에 있습니다. 이런 Stack 자료구조의 정책을 LIFO(Last In First Out) 혹은 FILO(First In Last Out)이라고 부르기도 합니다.
Stack의 실사용 예제
: 브라우저의 뒤로 가기, 앞으로 가기 기능을 구현할 때 자료구조 Stack이 활용
- 브라우저에서 자료구조 Stack이 사용될 때에는 다음과 같은 순서를 거칩니다.
- 새로운 페이지로 접속할 때, 현재 페이지를 Prev Stack에 보관합니다.
- 뒤로 가기 버튼을 눌러 이전 페이지로 돌아갈 때에는, 현재 페이지를 Next Stack에 보관하고 Prev Stack에 가장 나중에 보관된 페이지를 현재 페이지로 가져옵니다.
- 앞으로 가기 버튼을 눌러 앞서 방문한 페이지로 이동을 원할 때에는, Next Stack의 가장 마지막으로 보관된 페이지를 가져옵니다.
- 마지막으로 현재 페이지를 Prev Stack에 보관합니다.
Queue

큐(Queue)는 줄을 서서 기다리다, 대기 행렬 이라는 뜻을 가지고 있습니다. 톨게이트를 Queue 자료구조, 자동차는 데이터(data)로 비유할 수 있습니다. 가장 먼저 진입한 자동차가 가장 먼저 톨게이트를 통과합니다. 다시 말해, 가장 나중에 진입한 자동차는 먼저 도착한 자동차가 모두 빠져나가기 전까지는 톨게이트를 빠져나갈 수 없다는 말.
- 자료구조 Queue는 Stack과 반대되는 개념으로, 먼저 들어간 데이터(data)가 먼저 나오는 FIFO(First In First Out) 혹은 LILO(Last In Last Out) 을 특징으로 가지고 있습니다.
- 자료구조 Queue는 데이터(data)가 입력된 순서대로 처리할 때 주로 사용
Queue의 실사용 예제
자료구조 Queue는 컴퓨터에서도 광범위하게 활용됩니다. 컴퓨터와 연결된 프린터에서 여러 문서를 순서대로 인쇄하려면 어떻게 해야 할까요?
컴퓨터(출력 버튼) - (임시 기억 장치의) Queue에 하나씩 들어옴 - Queue에 들어온 문서를 순서대로 인쇄
1. 우리가 문서를 작성하고 출력 버튼을 누르면 해당 문서는 인쇄 작업 (임시 기억 장치의) Queue에 들어갑니다.
2. 프린터는 인쇄 작업 Queue에 들어온 문서를 순서대로 인쇄합니다.
위 예시처럼 컴퓨터 장치들 사이에서 데이터(data)를 주고 받을 때, 각 장치 사이에 존재하는 속도의 차이나 시간 차이를 극복하기 위해 임시 기억 장치의 자료구조로 Queue를 사용합니다. 이것을 통틀어 버퍼(buffer) 라고 합니다. 대부분의 컴퓨터 장치에서 발생하는 이벤트는 불규칙적으로 발생합니다. 이에 비해 CPU와 같이 발생한 이벤트를 처리하는 장치는 일정한 처리 속도를 갖습니다. 불규칙적으로 발생한 이벤트를 규칙적으로 처리하기 위해 버퍼(buffer)를 사용합니다.
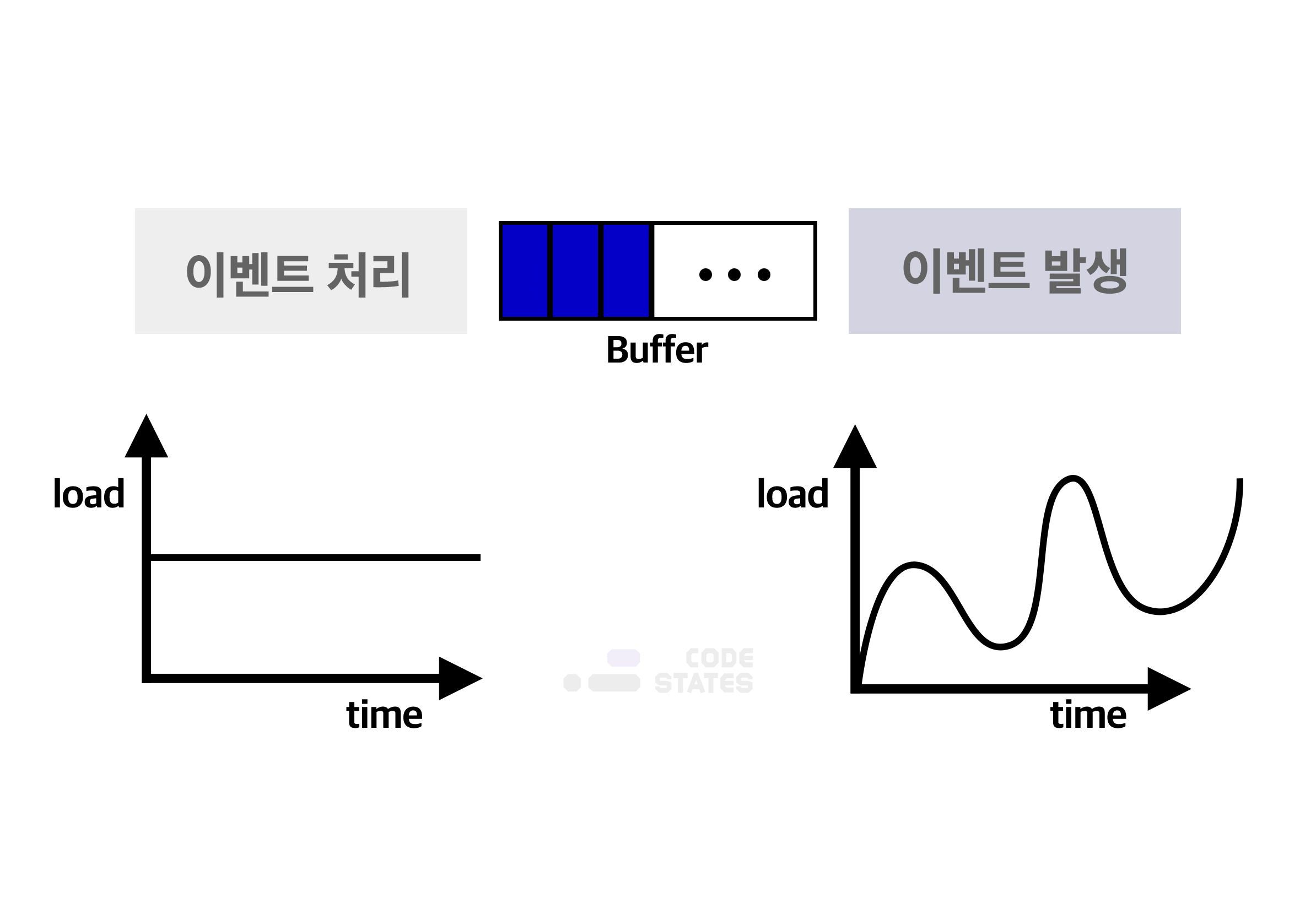
그림 CPU에서는 이벤트를 규칙적으로 처리합니다. (오른쪽) 대부분의 컴퓨터 장치에서는 이벤트가 불규칙하게 발생합니다.
컴퓨터와 프린터 사이의 데이터(data) 통신을 정리하면 다음과 같습니다.
- 일반적으로 프린터는 속도가 느립니다.
- CPU는 프린터와 비교하여, 데이터를 처리하는 속도가 빠릅니다.
- 따라서, CPU는 빠른 속도로 인쇄에 필요한 데이터(data)를 만든 다음, 인쇄 작업 Queue에 저장하고 다른 작업을 수행합니다.
- 프린터는 인쇄 작업 Queue에서 데이터(data)를 받아 일정한 속도로 인쇄합니다.
- 유튜브와 같은 동영상 스트리밍 앱을 통해 동영상을 시청할 때, 다운로드 된 데이터(data)가 영상을 재생하기에 충분하지 않은 경우가 있습니다. 이때 동영상을 정상적으로 재생하기 위해 Queue에 모아 두었다가 동영상을 재생하기에 충분한 양의 데이터가 모였을 때 동영상을 재생합니다.
배열로 자료구조 Stack 구현하기
: 직접 사용자 정의 데이터 타입을 구현해서 Stack과 Queue를 사용해도 좋습니다. 그러나 JavaScript에는 Array라는 훌륭한 자료형이 이미 있습니다. Array를 사용하면 사용자 정의 데이터 타입을 구현하는 시간을 절약할 수 있고, 몇 가지의 메서드로 Stack과 Queue처럼 동작하도록 사용할 수 있습니다. 자료구조로써 Stack과 Queue의 특성만 이해한다면, Array를 활용하여 Stack과 Queue로 사용할 수 있습니다. 자료구조는 자료(데이터)를 다루는 구조 그 자체를 뜻하며, 구현하는 방식에는 제약이 없습니다.
// const array = new Array() 미리 정의된 Array 객체를 사용합니다.
const stack = [];
stack.push(1); // [1]
stack.push(2); // [1, 2]
stack.push(3); // [1, 2, 3]
stack.push(4); // [1, 2, 3, 4]
stack.push(5); // [1, 2, 3, 4, 5]
console.log(stack); // [1, 2, 3, 4, 5]
stack.pop(); // [1, 2, 3, 4]
stack.pop(); // [1, 2, 3]
console.log(stack); // [1, 2, 3]
배열로 자료구조 Queue 구현하기
// const array = new Array() 미리 정의된 Array 객체를 사용합니다.
const queue = [];
queue.push(1); // [1]
queue.push(2); // [1, 2]
queue.push(3); // [1, 2, 3]
queue.push(4); // [1, 2, 3, 4]
queue.push(5); // [1, 2, 3, 4, 5]
console.log(queue); // [1, 2, 3, 4, 5]
queue.shift(); // [2, 3, 4, 5]
queue.shift(); // [3, 4, 5]
console.log(queue); // [3, 4, 5]- Array.prototype에는 Stack, Queue 사용을 위해 어떤 메서드가 존재하나요?
- 배열로 Stack, Queue를 사용할 때 주의해야 할 사항은 어떤것들이 있나요?
- 배열로 Stack을 사용할 때 push, pop 이외에 필요한 메서드를 어떻게 구현할 수 있나요?
- 배열로 Queue를 사용할 때 push, shift 이외에 필요한 메서드를 어떻게 구현할 수 있나요?
- JavaScript의 배열과 Stack, Queue는 어떤 차이가 있나요?
Graph / Tree / BST
Graph
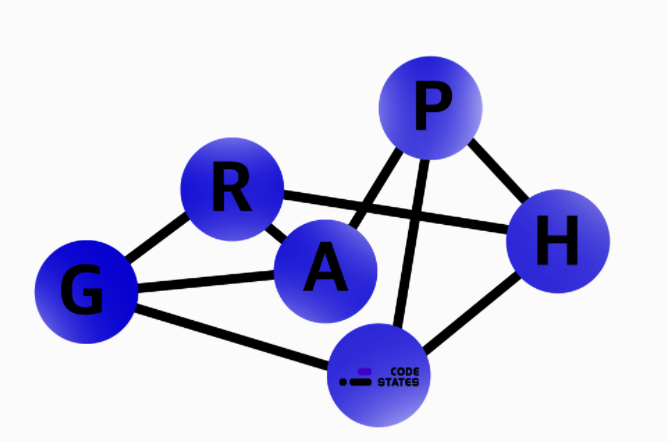
여러개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료구조. 직접적인 관계가 있는 경우 두 점 사이를 이어주는 선이 있습니다. 간접적인 관계라면 몇 개의 점과 선에 걸쳐 이어집니다. 하나의 점을 그래프에서는 정점(vertex)이라고 표현하고, 하나의 선은 간선(edge)

그래프의 실사용 예제
: 포털 사이트의 검색 엔진, SNS에서 사람들과의 관계, 네비게이션 (길찾기) 등에서 사용하는 자료구조가 바로 그래프 활용. 세 가지 모두 수많은 정점(Vertex)을 가지고 있고, 서로 관계가 있는 정점은 간선으로 이어져 있습니다.
- 예제 ) A는 부산에 사는 B와 오랜 친구 사이입니다. 이번 주말에 부산에서 열리는 B의 결혼식에 참석하기 위해 A는 차를 몰고 부산으로 가려고 합니다. 대전에 살고 있는 친구 C도 B의 결혼식에 참석을 한다고 하여, A는 서울에서 출발하여 대전에서 C를 태워 부산으로 이동을 하려고 합니다.
- 3개의 정점이 존재합니다: A, B, C가 사는 각각의 도시(서울, 부산, 대전)를 그래프의 정점으로 삼을 수 있습니다. 그리고 이 3개의 정점은 서로 이어지는 간선(관계) 을 가지고 있습니다. 서울, 대전, 부산 사이에 간선이 존재하는데, 이 간선은 내비게이션에서 이동할 수 있음을 나타냅니다. 정점에 캐나다의 토론토를 추가한다면 어떻게 될까요? 자동차로는 토론토에서 한국으로 이동할 수 없기 때문에 어떠한 간선도 추가할 수 없습니다. 그래프에선 이런 경우를 관계가 없다 라고 표현합니다.
- 비가중치 그래프 : 추가적인 정보를 파악할 수 없는 그래프, 가중치(연결의 강도가 얼마나 되는지)가 적혀 있지 않은 이런 그래프.
- 정점: 서울, 대전, 부산
- 간선: 서울—대전, 대전—부산, 부산—서울
- 간선으로 알 수 있는 정보 : 서울, 대전, 부산이 서로 관계가 있다
- 간선으로 알 수 없는 정보 : 각 도시가 얼마나 떨어져 있는지는 알 수 없다.
// 비가중치 그래프 객체로 표현하기
let isConnected = {
seoul: {
busan: true,
daejeon: true
},
daejeon: {
seoul: true,
busan: true
},
busan: {
seoul: true,
daejeon: true
}
}
console.log(isConnected.seoul.daejeon) // true
console.log(isConnected.daejeon.busan) // true내비게이션이라면, 적어도 각 도시간의 거리가 얼마나 되는지는 표시해야 하지 않을까요?
네비게이션은 간선에 거리를 표기한 가중치 그래프가 확장되어, 수백만개의 정점(주소)과 간선이 추가 되어야 비로소 내비게이션에서 쓰는 자료구조와 유사해 집니다.
- 가중치 그래프 : 간선에 연결정도(거리 등)를 표현한 그래프. ( 비가중치 그래프는 각 정점간의 연결 유무만을 판단하는 반면, 가중치 그래프는 더 자세한 정보를 담을 수 있습니다. )
- 정점: 서울, 대전, 부산
- 간선: 서울—140km—대전, 대전—200km—부산, 부산—325km—서울
알아둬야 할 그래프 용어들
- 무(방)향그래프(undirected graph): 앞서 보았던 내비게이션 예제는 무(방)향 그래프 입니다. 서울에서 부산으로 갈 수 있듯, 반대로 부산에서 서울로 가는것도 가능합니다. 하지만 단방향(directed) 그래프로 구현 된다면 서울에서 부산을 갈 수 있지만, 부산에서 서울로 가는 것은 불가능합니다(혹은 그 반대). 만약 두 지점이 일방통행 도로로 이어져 있다면 단방향인 간선으로 표현할 수 있습니다.
- 진입차수(in-degree) / 진출차수(out-degree): 한 정점에 진입(들어오는 간선)하고 진출(나가는 간선)하는 간선이 몇 개인지를 나타냅니다.
- 인접(adjacency): 두 정점간에 간선이 직접 이어져 있다면 이 두 정점은 인접한 정점입니다.
- 자기 루프(self loop): 정점에서 진출하는 간선이 곧바로 자기 자신에게 진입하는 경우 자기 루프를 가졌다 라고 표현합니다. 다른 정점을 거치지 않는다는 것이 특징입니다.
- 사이클(cycle): 한 정점에서 출발하여 다시 해당 정점으로 돌아갈 수 있다면 사이클이 있다고 표현합니다. 내비게이션 그래프는 서울 —> 대전 —> 부산 —> 서울 로 이동이 가능하므로, 사이클이 존재하는 그래프 입니다.
다음의 질문에 대한 답변을 고민해보세요.
- 위 네비게이션 예제에서 서울은 몇개의 진입차수와 몇개의 진출차수를 가지고 있나요?
- 네비게이션 대신 SNS에서 자료구조로 그래프를 이용한다면, 정점과 간선은 무엇이 될까요?
- SNS에서 어떤 관계일 경우 단방향 그래프가 생성될까요?
- 자기 루프와 사이클은 어떻게 다를까요?
그래프의 표현 방식: 인접 행렬 & 인접 리스트
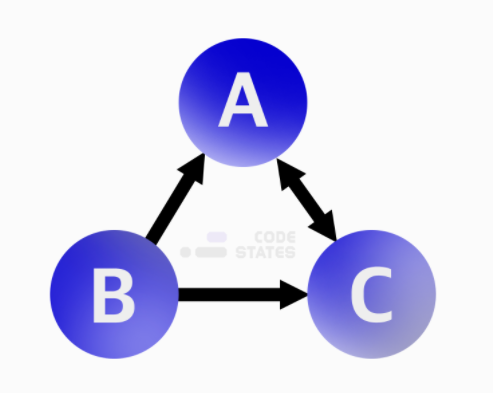
[그림] 그래프 예시
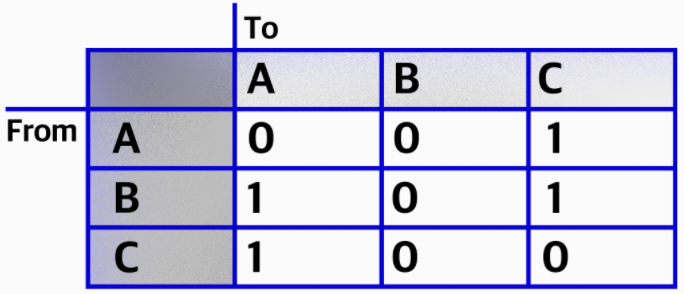
인접 행렬
: 2차원 배열의 형태. 인접 행렬은 서로 다른 정점들이 인접한 상태인지를 표시한 행렬.
- 1(true) : A라는 정점과 B라는 정점이 이어져 있다. 가중치 그래프라면 1 대신 관계에서 의미 있는 값을 저장. 내비게이션 예제라면, 거리를 입력.
- 0(false) : 이어져 있지 않다.
- A의 진출차수는 1개: A —> C
[0][2] === 1
B의 진출차수는 2개: B —> A[1][0] === 1, B —> C[1][2] === 1
C의 진출차수는 1개: C —> A[2][0] === 1
인접 행렬은 언제 사용할까?
: 한 개의 큰 표와 같은 모습을 한 인접 행렬은 두 정점 사이에 관계가 있는지, 없는지 확인하기에 용이. 가장 빠른 경로(shortest path)를 찾고자 할 때 주로 사용.

인접 리스트
: 인접 리스트는 각 정점이 어떤 정점과 인접한지를 리스트의 형태로 표현. 각 정점마다 하나의 리스트를 가지고 있으며, 이 리스트는 자신과 인접한 다른 정점을 담고 있습니다.
- B는 A와 C로 이어지는 간선이 두개가 있는데, 왜 A가 C보다 먼저죠? 이 순서는 중요한가요?
- 보통은 중요하지 않습니다. 그래프, 트리, 스택, 큐 등 모든 자료 구조는 구현하는 사람의 편의와 목적에 따라 기능을 추가/삭제할 수 있습니다. 그래프를 인접 리스트로 구현할 때, 정점별로 살펴봐야 할 우선 순위를 고려해 구현할 수 있습니다. 이때, 리스트에 담겨진 정점들을 우선 순위별로 정렬할 수 있습니다. 우선 순위가 없다면, 연결된 정점들을 단순하게 나열한 리스트가 됩니다.
- 우선 순위를 다뤄야 한다면 더 적합한 자료구조(ex. queue, heap)를 사용하는 것이 합리적 입니다. 따라서 보통은 중요하지 않습니다. (언제나 예외는 있습니다.)
인접 리스트는 언제 사용할까?
: 메모리를 효율적으로 사용하고 싶을 때 인접 리스트를 사용합니다.
인접 행렬은 연결 가능한 모든 경우의 수를 저장하기 때문에 상대적으로 메모리를 많이 차지합니다.
Tree

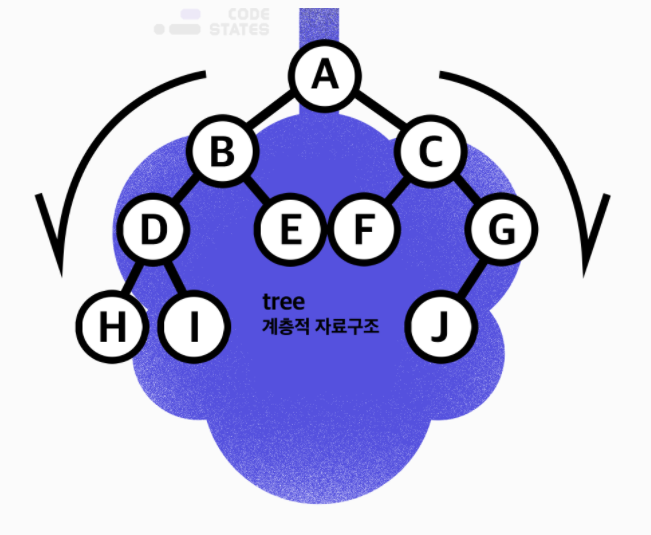
그래프의 여러 구조 중 단방향 그래프의 한 구조로, 하나의 뿌리로부터 가지가 사방으로 뻗은 형태가 나무와 닮아 있다고 해서 트리 구조. 가계도와 흡사.
- 데이터가 바로 아래에 있는 하나 이상의 데이터에 단방향으로 연결된 계층적 자료구조.
- 하나의 데이터 뒤에 여러 개의 데이터가 존재할 수 있는 비선형 구조 (데이터를 순차적으로 나열시킨 선형 구조가 아님)
- 트리 구조는 계층적으로 표현이 되고, 아래로만 뻗어나가기 때문에 사이클이 없습니다.
- 깊이와 높이, 레벨 등을 측정할 수 있습니다.
- 루트(Root) 라는 하나의 꼭짓점 데이터를 시작으로 여러 개의 데이터를 간선(edge) 으로 연결합니다. 각 데이터를 노드(Node) 라고 하며, 두 개의 노드가 상하계층으로 연결되면 부모/자식 관계를 가집니다. 위 그림에서 A는 B와 C의 부모 노드(Parent Node)이고, B와 C는 A의 자식 노드(Child Node)입니다. 자식이 없는 노드는 나무의 잎과 같다고 하여 리프 노드(leaf Node)라고 부릅니다.
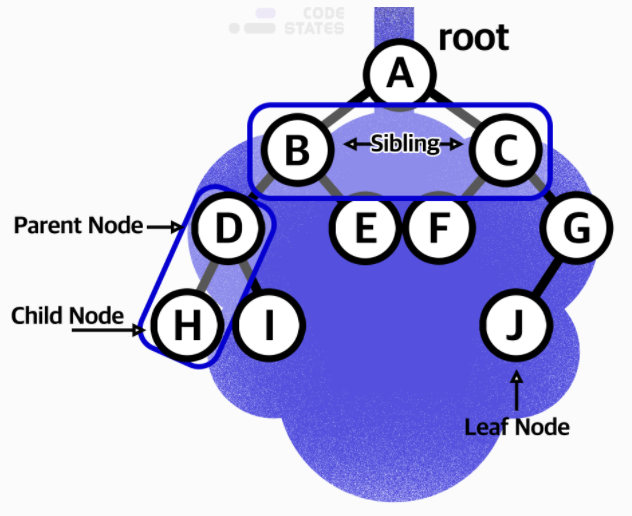
트리그래프 구조의 용어정리
- 노드(Node) : 트리 구조를 이루는 모든 개별 데이터
- 루트(Root) : 트리 구조의 시작점이 되는 노드
- 부모 노드(Parent node) : 두 노드가 상하관계로 연결되어 있을 때 상대적으로 루트에서 가까운 노드
- 자식 노드(Child node) : 두 노드가 상하관계로 연결되어 있을 때 상대적으로 루트에서 먼 노드
- 리프(Leaf) : 트리 구조의 끝지점이고, 자식 노드가 없는 노드
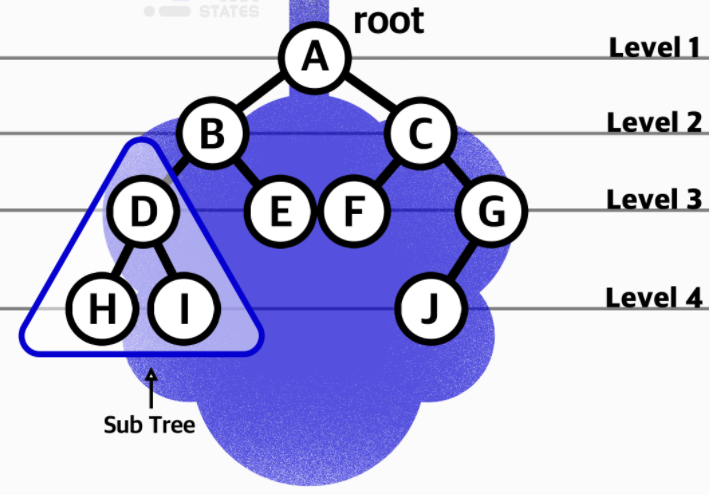
- 깊이 (depth) : 트리 구조에서는 루트(0)로부터 하위 계층의 특정 노드까지의 깊이(depth)를 표현.
- 루트 노드는 지면에 있는 것처럼 깊이가 0입니다. 위 그림에서 루트 A의 depth는 0이고, B와 C의 깊이는 1입니다. D, E, F, G의 깊이는 2입니다.
- 레벨(Level) : 트리 구조에서 같은 깊이를 가지고 있는 노드를 묶어서 레벨(level)로 표현. 루트(level 1).
- depth가 0인 루트 A의 level은 1입니다. depth가 1인 B와 C의 level은 2입니다. D, E, F, G의 레벨은 3입니다. 같은 레벨에 나란히 있는 노드를 형제 노드(sibling Node) 라고 합니다.
- 높이(Height) : 트리 구조에서 리프 노드를 기준으로 루트까지의 높이(height)를 표현
- 리프 노드와 직간접적으로 연결된 노드의 높이를 표현, 부모 노드는 자식 노드의 가장 높은 height 값에 +1한 값을 높이로 가집니다. 트리 구조의 높이를 표현할 때에는 각 리프 노드의 높이를 0으로 놓습니다.위 그림에서 H, I, E, F, J의 높이는 0입니다. D와 G의 높이는 1입니다. B와 C의 높이는 2입니다. 이때 B는 D의 height + 1 을, C는 G의 height + 1 을 높이로 가집니다. 따라서, 루트 A의 높이는 3입니다.
- 서브 트리(Sub tree) : 트리 구조에서 root에서 뻗어나오는 큰 트리의 내부에, 트리 구조를 갖춘 작은 트리.
- (D, H, I)로 이루어진 작은 트리도 서브 트리이고, (B, D, E)나 (C, F, G, J)도 서브 트리입니다.
트리의 실사용 예제
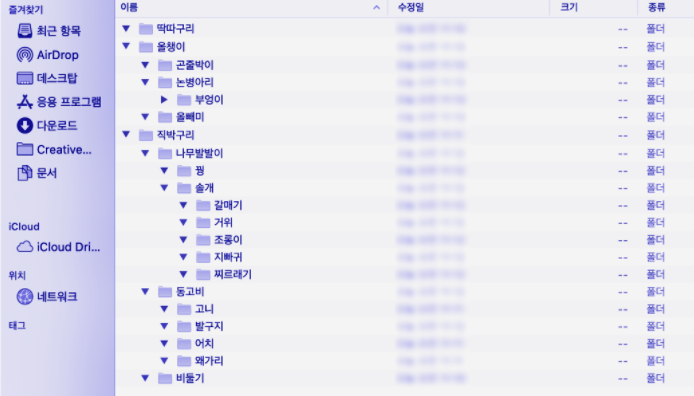
: 가장 대표적인 예제는 컴퓨터의 디렉토리 구조입니다. 어떤 프로그램이나 파일을 찾을 때, 바탕화면 폴더나 다운로드 폴더 등에서 다른 폴더에 진입하고, 또 그 안에서 다른 폴더에 진입하면서 원하는 프로그램이나 파일을 찾습니다. 모든 폴더는 하나의 폴더(루트 폴더, /)에서 시작되어, 가지를 뻗어나가는 모양새. 사용자들이 사용하기 편하게 사용하기 위한 파일 시스템 등에서는 트리 구조를 이용해 만들어져 있습니다. 다른 예 : 월드컵 토너먼트 대진표, 가계도(족보), 조직도 등.
BST(Binary Search Tree) - 트리구조의 특징에 따른 분류

: 트리 구조는 편리한 구조를 전시하는 것 외에 효율적인 탐색을 위해 사용하기도 합니다.
- 트리 구조가 가지는 특징에 따라 여러 가지 이름이 있다.
- 이진 트리(binary tree) : 가장 간단하고 많이 사용하는 트리의 모습.
자식 노드가 최대 두 개인 노드들로 구성된 트리. 이 두 개의 자식 노드는 왼쪽 자식 노드와 오른쪽 자식 노드로 나눌 수 있다.- 자료의 삽입, 삭제 방법에 따라 정 이진 트리(Full binary tree), 완전 이진 트리(Complete binary tree), 포화 이진 트리(Perfect binary tree)로 나뉩니다.
| 이진 트리 종류 | 설명 |
|---|---|
| 정 이진 트리 (Full binary tree) | 각 노드가 0 개 혹은 2 개의 자식 노드를 갖습니다. |
| 포화 이진 트리 (Perfect binary tree) | 정 이진 트리이면서 완전 이진 트리인 경우입니다. 모든 리프 노드의 레벨이 동일하고, 모든 레벨이 가득 채워져 있는 트리입니다. |
| 완전 이진 트리 (Complete binary tree) | 마지막 레벨을 제외한 모든 노드가 가득 차 있어야 하고, 마지막 레벨의 노드는 전부 차 있지 않아도 되지만 왼쪽이 채워져야 합니다. |
-
이진 탐색 트리(Binary Search Tree)
: 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징이 있습니다. -
이진 탐색 트리는 균형 잡힌 트리가 아닐 때, 입력되는 값의 순서에 따라 한쪽으로 노드들이 몰리게 될 수 있습니다. 균형이 잡히지 않은 트리는 탐색하는 데 시간이 더 걸리는 경우도 있기 때문에 해결해야할 문제입니다. 이 문제를 해결하기 위해 삽입과 삭제마다 트리의 구조를 재조정하는 과정을 거치는 알고리즘을 추가할 수 있습니다.
