오늘은 여러 모델을 한번에 학습하여 비교해주는 라이브러리인 pycaret에 대해 알아보도록 하겠습니다.
pycaret을 활용하면 여러 모델의 성능 비교 뿐만아니라 하이퍼파라미터 tunning, 여러 모델을 blending한 모델을 만들 수 있습니다.
pycaret Binary Classification tutorial을 참고하였습니다.
pycaret 설치
우선은 pycaret을 설치합니다.
!pip install pycaret모델 비교시 catboost가 없다면 다음과 같이 설치를 해줘야합니다.
!pip install pycaret[full]데이터 로드
데이터는 pycaret에서 제공하는 'credit' 데이터를 사용하였습니다.
해당 데이터를 불러와줍니다.
from pycaret.datasets import get_data
dataset = get_data('credit')train/test 데이터로 데이터를 분리해줍니다.
train = dataset.sample(frac=0.95, random_state=786)
test = dataset.drop(train.index)
train.reset_index(inplace=True, drop=True)
test.reset_index(inplace=True, drop=True)데이터 설정
pycaret을 사용하기 전에 pycaret에 맞게 데이터를 설정해줘야합니다.
set_up() 함수를 사용하며, 기본적으로 data와 target을 입력해줍니다.
입력 후 column에 대한 자료형이 출력되며 enter를 치면 data가 설정됩니다.
from pycaret.classification import *
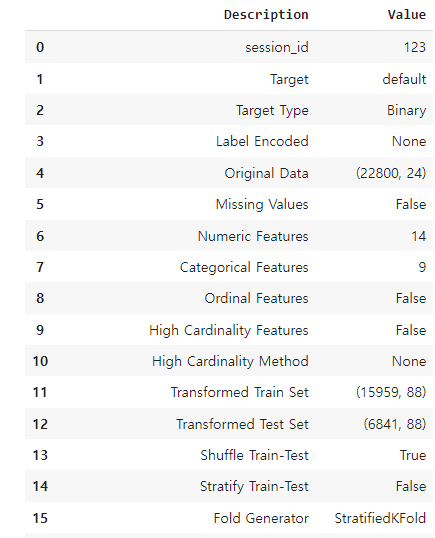
exp_clf = setup(data = train, target = 'default', session_id=123)set_up(): pycaret을 사용하기 위한 data setting
- session_id: random_state와 같은 개념으로 같은 결과가 나올 수 있게 seed를 고정합니다.
- data: train 데이터를 입력합니다.
- target = target 변수 이름을 입력합니다.
data 설정값이 다음과 같이 출력됩니다.
모델 비교
여러 모델을 적합하여 성능을 비교하는 단계입니다.
best_model = compare_models()총 14개 모델의 적합 결과가 다음과 같이 출력됩니다.
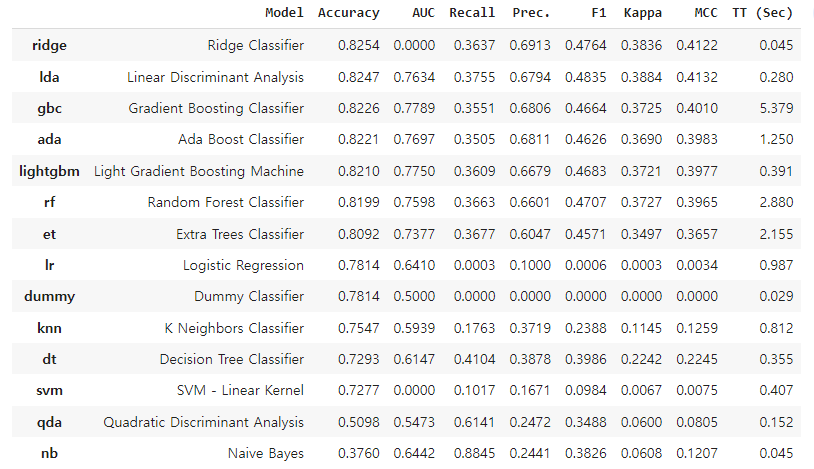
compare_models(): 다양한 모델 적합 후 성능 비교
- fold: cross_validation의 fold를 지정 (default = 10)
- sort: 정렬기준 지표 설정
- n_select: 상위 n개의 모델 결과만 출력
모델 적합
앞에서는 다양한 모델의 적합 결과를 확인하였는데, 이번에는 하나의 모델의 적합 결과를 보는 방법입니다.
rf = create_model('rf')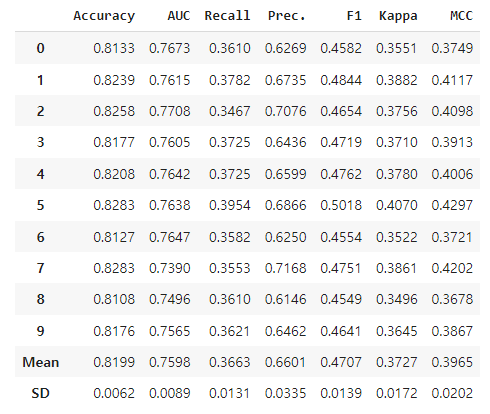
create_model(): 하나의 모델 적합
- fold: cross_validation의 fold 지정 (default = 10)
Tunning
tune_model() 함수를 사용해서 모델의 하이퍼파라미터 튜닝을 진행합니다.
tuned_rf = tune_model(rf)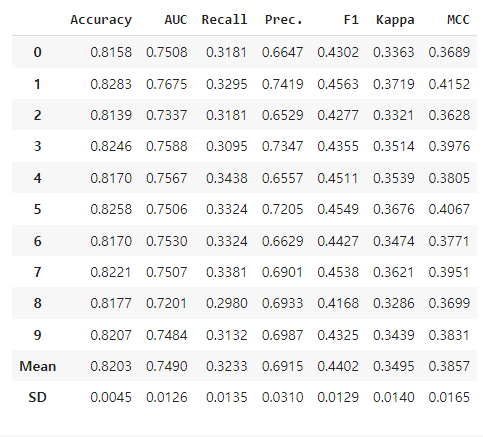
tuned_rf를 호출하면 튜닝 결과를 확인할 수 있습니다.

tune_model(model): 모델의 하이퍼파라미터 튜닝
- optimize: 평가 metric 지정
Blending
blend_models() 함수를 사용하면 여러 모델들을 혼합하여 새로운 모델을 생성합니다.
모델을 하나씩 생성해서 blend해도 되고 compare_model을 사용하여 생성한 모델을 사용해서 blend할 수 있습니다.
# 방법 1
dt = create_model('dt')
rf = create_model('rf')
blender_2 = blend_models(estimator_list = [dt, rf])
# 방법 2
best_model_5 = compare_models(n_select=5)
blender_5 = blend_models(best_model_5)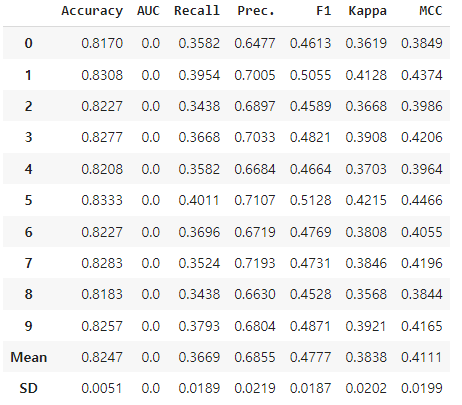
blend_models(models): 여러 모델들을 혼합한 새로운 모델을 생성
예측
finalize_model() 함수로 모델을 설정하면, cross_validation을 사용하여 적합한 모델을 전체 데이터로 마지막으로 학습을 합니다. 마지막 모델을 설정한 후에 predict_model()을 통해 예측을 합니다.
final_model = finalize_model(blender_5)
prediction = predict_model(final_model, data = test)예측 결과는 'Label'변수에 다음과 같이 저장됩니다.

finalize_model(): 최종 모델로 설정 후 마지막 학습 진행
predict_model(): 예측 결과를 'Label' 변수에 저장

setup을 colab에서 돌리는데 속도가 너무 느립니다.