✔ Basic Info
📌 Attention Is All You Need (2017)
🔗 https://arxiv.org/pdf/1706.03762워낙 현대 딥러닝 근간이 되는 모델이기 때문에 실험 하나하나 보다는 모델 구조에 초점맞춘 논문 리뷰.
☑️Transformer 모델 구조 설명
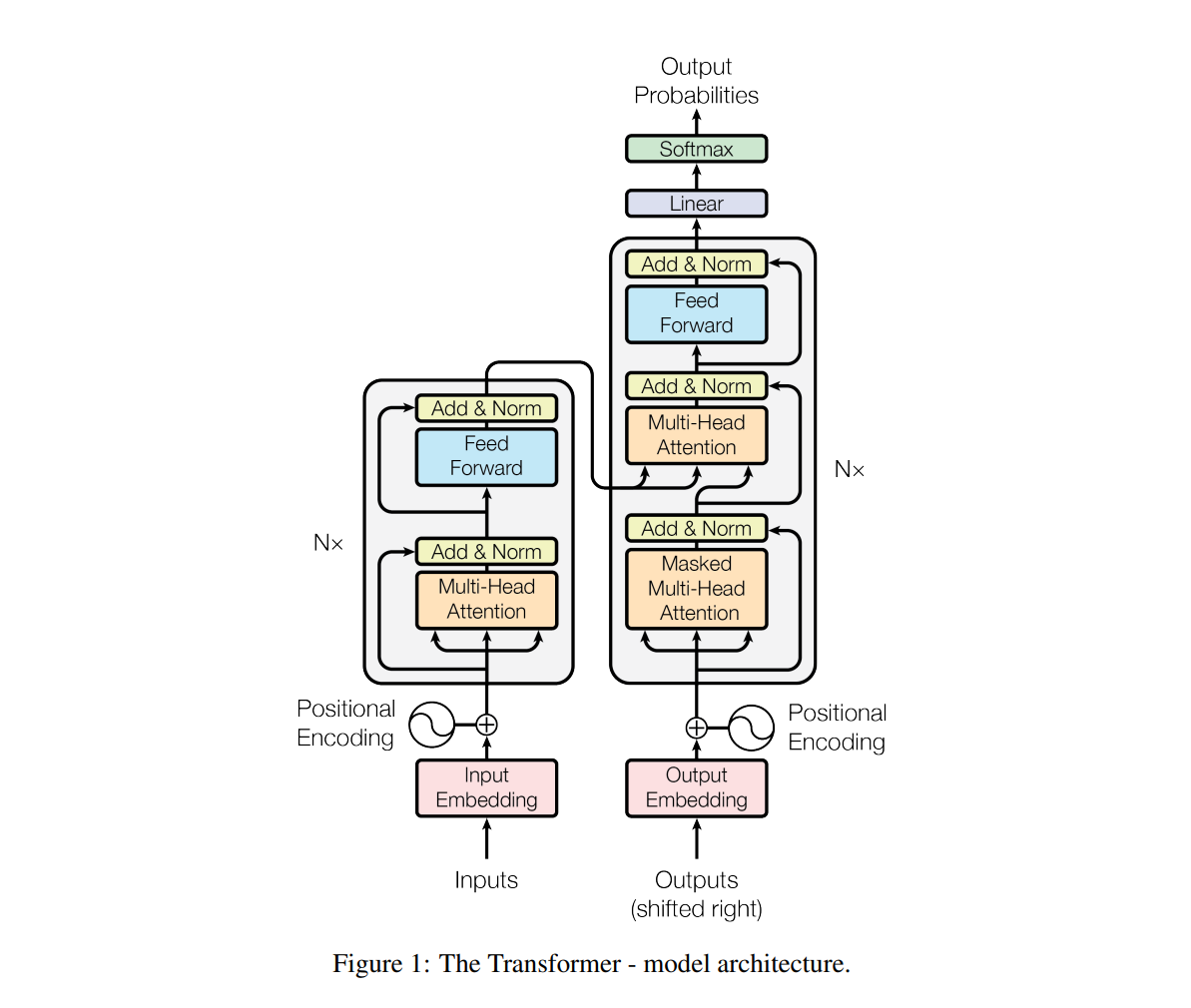
- Transformer 는 Encoder, Decoder 를 각각 6개씩 동일 레이어를 쌓은 구조로 구성된 모델
☑️Positional Encoding (PE)
입력시 트렌스포머 구조는 단어 순서 정보가 없기 때문에 sin, cos 기반 포지셔널 인코딩한 벡터를 input, output 인코딩 벡터와 더해 위치 정보를 추가해준다.
- Positional Encoding은 embedding 차원(d_model)을 기준으로 짝수 인덱스에는 sin, 홀수 인덱스에는 cos 값을 넣는다.
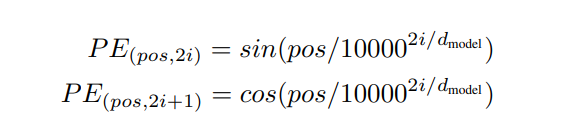
- pos: 단어의 문장 내 위치 (0, 1, 2, 3, …)
- i: embedding 벡터의 위치 - 길이가 너무 길면 위치 벡터가 0 이 될 수 있음.
이를 방지하기 위해 임베딩 벡터 길이인 d_model 로 나누는 작업을 해주는 것 - sin, cos 번갈아가며 해주는 이유 = 긴 문장도 겹치지 않게 하기 위해서
- d_model: 모델의 embedding 크기
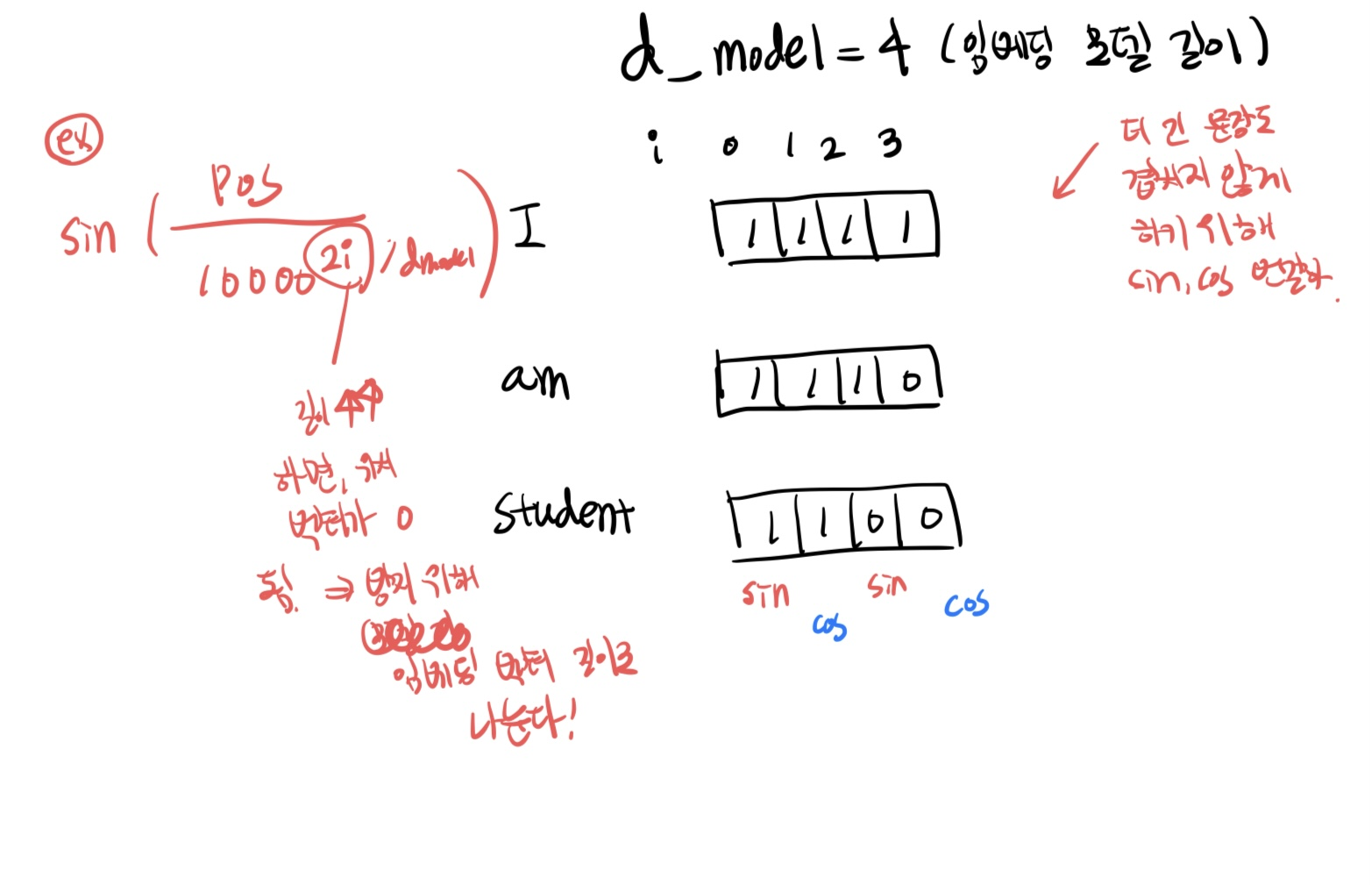
예시 : i 와 pos 차이 보여주는 필기본
☑️Multi-Head Attention
한개의 Head 가 아니라 여러 head 를 두어 Q,K,V Attention 수행한다 -> 문장의 다양한 표현 다양한 관점에서 학습
| 종류 | 어디서 쓰는가 | Self-Attention? | Q/K/V의 출처 |
|---|---|---|---|
| ① Encoder Self-Attention | Encoder | ✅ | Q=K=V=Encoder 입력 |
| ② Decoder Self-Attention (Masked) | Decoder | ✅ | Q=K=V=Decoder 입력 |
| ③ Encoder–Decoder Cross-Attention | Decoder | ❌ Self 아님 | Q=Decoder, K=V=Encoder |
Q,K,V
- Q(쿼리) : 무엇이 알고 싶은지
- K(키): 각 단어가 “나의 특징은 이거야!” 하고 들고 있는 설명서 (실제 값인 V 의 힌트를 주는 값)
- V(값) : 내용 정보 벡터 (실제 내용)
Q = XW_Q
K = XW_K
V = XW_V
이때 Q,K,V 의 Weight 은 한 토큰에서도 해당 기능을 하도록 같은 임베딩에서 출발해서 -> 서로 다른 가중치 행렬로 변환되어 다른 의미를 가지게 됨
Self-Attention
단어 간 상관관계를 말함. 이때 Q,K,V 는 같은 인풋 X 에서 나온다
Cross-Attention
Q: 디코더 쪽 정보 (생성 중 문장)
K,V: 인코더 쪽 (입력 문장)
내가 생성중인 단어 (Q) 에 대해 입력 문장 (K,V) 어디를 참고할지 상관 판단
Attention
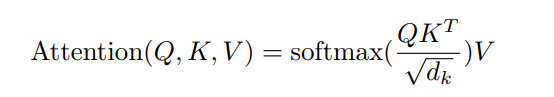
Q,K 가 내적으로 얼마나 비슷한지 측정
이를 softmax 씌워서 가중치로 변환해 실제 정보인 V 를 얼마나 가져올지 판단
ex.
output(love) = 0.1V(I) + 0.6V(love) + 0.3V(cats) 이런 결론을 내기 위해 가중치를 q,k 유사도 실제 정보 V 곱한다는 뜻
- dk 로 나누는 이유 : 임베딩 사이즈로 나누는데 그 이유는 임베딩 길이가 무한정 커지면 attention score 너무 커짐 -> 길이 길다고 반영 너무 많이 하면 의미 판단 제대로 안되니까 길이로 나누는 걸로 정규화 해주는 것.
Multi-Head Attention
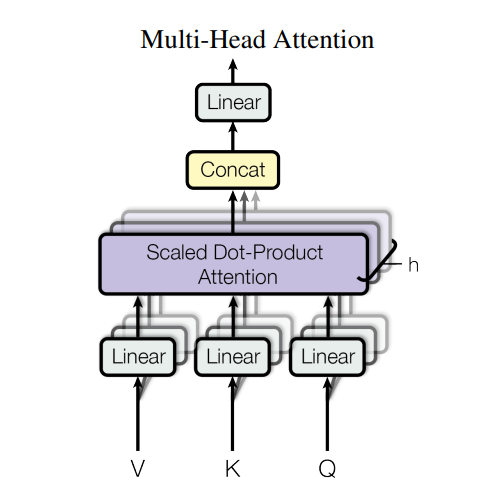
-
Q,K,V 를 각각 다른 Linear Layer 를 통과시켜 서로 다른 관점 (Head) 를 만들고 각 Attention 연산을 한 뒤 concat 을 한다.
-
여러 시각에서 Q, K,V 를 동시에 보고 결합하는 방식
-
같은 입력 벡터를 각 head마다 서로 다른 선형변환으로 투영해서 더 작은 차원의 여러 벡터를 만들게 됨.
-
예를 들어 512 차원의 벡터가 각 QKV 벡터였으면 정보 모두 포함한 각 64차원 벡터로 투영시킨다는 것임.
-
원본 그대로 보존이 목적이 아니라 특징 추출이 목적이기 때문에 이 방법이 유용했다.
-
Head 의 개수가 무조건 많다고 좋은건 아님. 다만 Head 가 많으면 주요 특징 추출에 유용하기 때문에 학습에 유용
Masked Multi-Head Attention
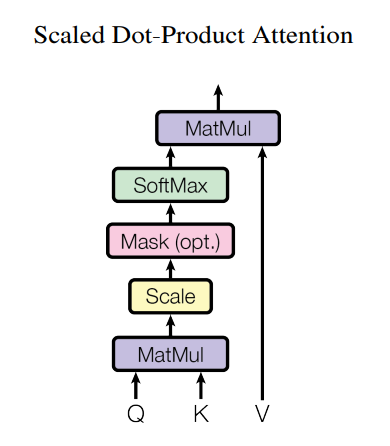
-
Multi-head attention = self-attention을 하되, head를 여러 개 둬서 다양한 관계와 정보를 표현.
-
Head 여러개 둬서 각 head 가 다른 패턴을 찾게 하는 건 동일한데 디코더 부분에서 출력시 이후 나올 단어를 지워놔서 뒷내용을 예측하게 두는 방식
-
훈련 단계에서는 입력 - 출력 정답이 있는 것을 학습시키니까, 정답을 보고 학습되지 않게 해가 위해 masking 을 해주는 것
-
추론 시에도 한 토큰씩 생성할 때 이전 토큰만 보도록 규칙을 유지
ex. [나는] (오늘, 밥을 을 못봄)
[나는], [오늘] (밥을 을 못봄)
[나는],[오늘],[밥을] (이 뒤에 못봄)
- 마스킹 할때 masked_scores=scores+mask
이때 mask 안할 부분은 mask = 0, masking 할 부분은 - 무한으로 지정해서 더함
☑️Residual Connection (그림에서는 Add)
Attention 계산 및 FFNN 이후 원본 입력 x 를 더한다.
output = LayerNorm(x + Sublayer(x))
이때 인풋 x 와 Layer 통과한 값을 더해줌
이유 : Vanishing Gradient 문제 해결 위해, 학습 속도 개선과 수렴을 위해서
F(x) + x
☑️Layer Normalization (그림에서는 Norm)
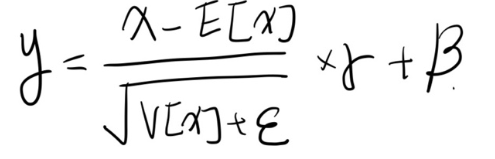
x: 한 토큰의 hidden vector 전체 (예: 512차원)
E[x]: 그 벡터의 평균
Var(x): 그 벡터의 분산
γ, β: 학습 가능한 스케일(scale) · 쉬프트(shift) 파라미터
ε: 분모가 0 되는 것을 방지하는 작은 값
즉, 각 토큰별 벡터를 정규화하는 것이 Layer Normalization
Attention - FFN - Residual Connection 반복하면 값이 폭발하기 쉬움.
Layer Normalization 으로 각 단계 값의 scale 을 안정화 시켜 학습 가능하게 만든 것.
☑️Final Thoughts
Transformer 구조를 revisit 해보니, 과연 현대 딥러닝 구조의 바이블이 맞다는 생각이 많이 든다. 어텐션 뿐만 아니라 트렌스포머 구조 자체 전반이 어떤 딥러닝 프로젝트에서든 아이디어로 쓰인다는게 좀 공부하고 보니 보인다.
잊을만 하면 다시 씹어먹으러 와야 하는 정말 중요한 구조구나 싶었다. 봐도 봐도 새로운게 보인다.
올해 처음 뭣도 모르고 동아리 들어와서 프로젝트 할때는 너무나 어렵게 느껴졌던 구조가 그래도 이해가 간다는게 신기하기도 하고, 여러모로 격세지감을 느끼게 만드는 논문.
1년이 늘 짧다고만 생각했는데, 생각보다 정말 길구나.
추가 의문점들 해결 (2026/03/26)
- 마스크는 패딩 마스크 형식 (0, - 무한)
- masked score=score+mask 이니까 mask 안하는건 0 있는건 -무한.
- softmax 통과하기에 - 무한 하면 0

-
Attention 모듈은 가중치 분배를 비선형적으로 결합, FFN 는 표현 자체를 비선형적으로 결합
-
FN 역할:
- Attention 부분들은 정보들의 관계를 파악하기 위해 필요하지만 참고해서 얻은 표현을 어떻게 변환할지에 대해 적용- 좀 더 풍부한 벡터 표현 (feature representation) 만들 수 있음
- Transformer의 FFN은 각 토큰 위치에 독립적으로 적용되는 2-layer MLP
-
Add & Norm
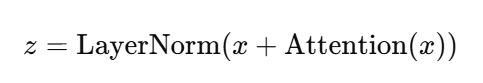
Add 는 Residual Connection (F(x) + x) 즉 어텐션 통과한거 + 원 정보
Norm 은 (Layer Norm)

하는 이유는 만약 한 값이 극단적으로 크면 정규화 안된 상태에서 진행하면 표현의 지나친 차이 때문에 전반적인 정보 표현력의 정확도가 낮아짐.
Transformer의 각 레이어마다 LayerNorm이 들어가고, 그 LayerNorm은 각 토큰 벡터를 독립적으로 정규화
Positional Encoding 이 필요한 이유 추가로
-
self attention 과정 중에 토큰 간 관
-
문장 시퀀스 전체를 한번에 처리함 (self-attention 과정으로) 따라서 순서 정보를 부여해줘야 함
-
시퀀스 내에서 관계 정보 처리하기 때문에 절대적 및 상대적 위치는 유실되니까 PE 쓰는거
