
1. 오늘 일정
1) 강의 수강
2) 피어 세션
3) 논문 발표 준비
2. 학습 내용
NLP
7강 ~ 8강: Transformer
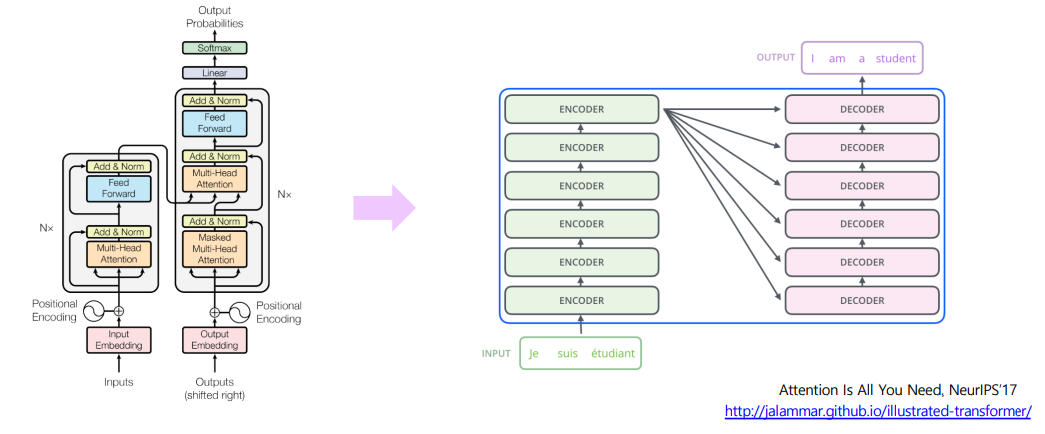
- Attention is all you need 논문에서 등장.
- 더 이상 RNN, CNN 모듈을 사용하지 않음.
RNN: Long-Term Dependency
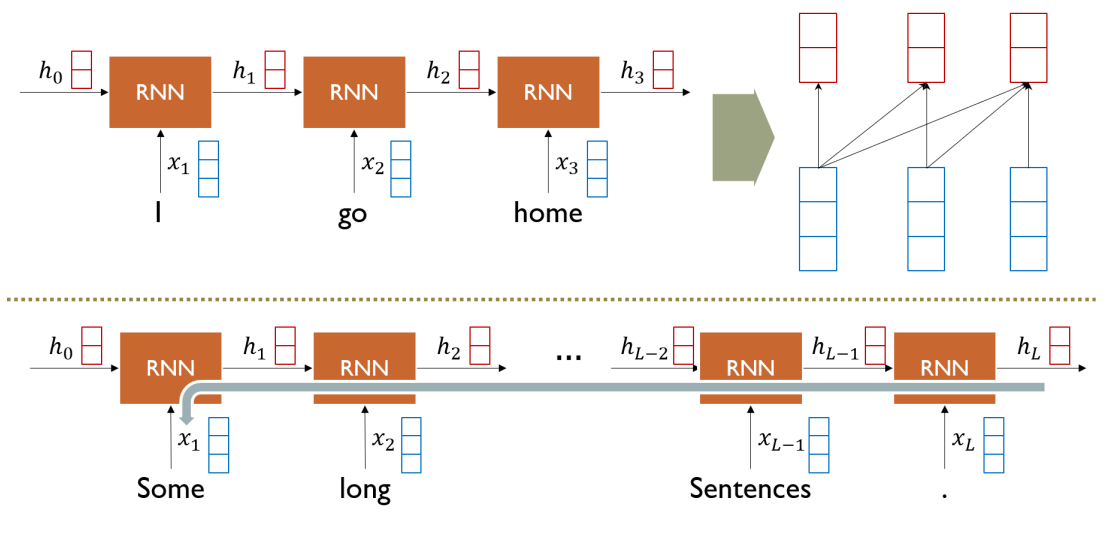
- RNN의 경우, 정보가 손실되는 Long-Term Dependency 문제를 지님
Bi-Directional RNNs
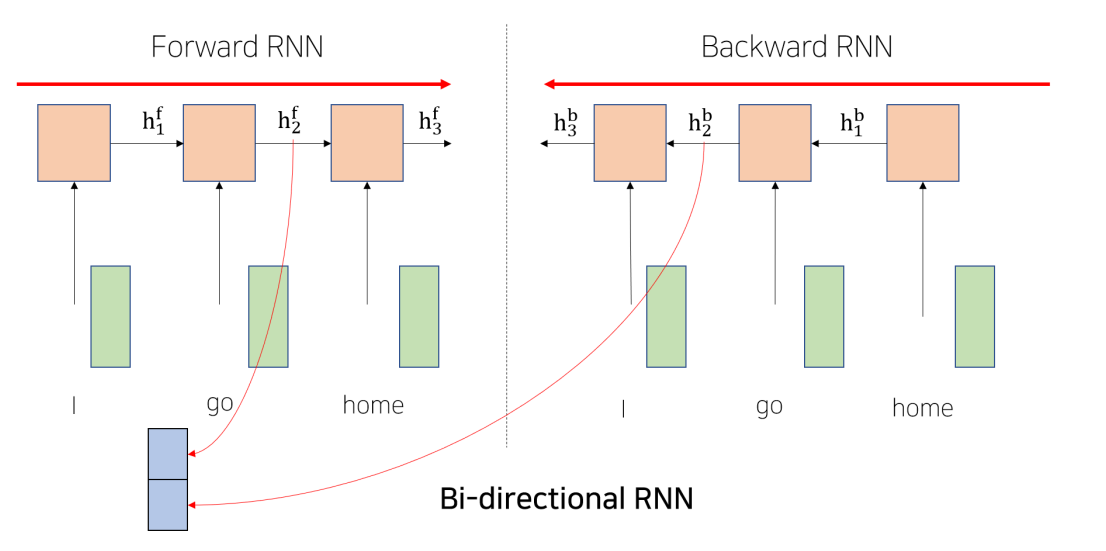
- 기존의 LSTM과 GRU와 같은 과거의 모델들은 예측하고자 하는 단어 뒤에 있는 정보를 이용할 수 없는 문제가 있음
- 양방향으로 예측할 수 있도록 Bi-Directional RNN이 등장
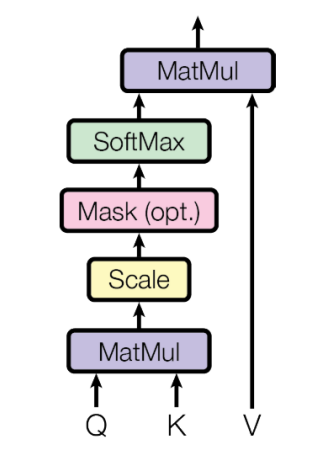
Transformer: Scaled Dot-Product Attention
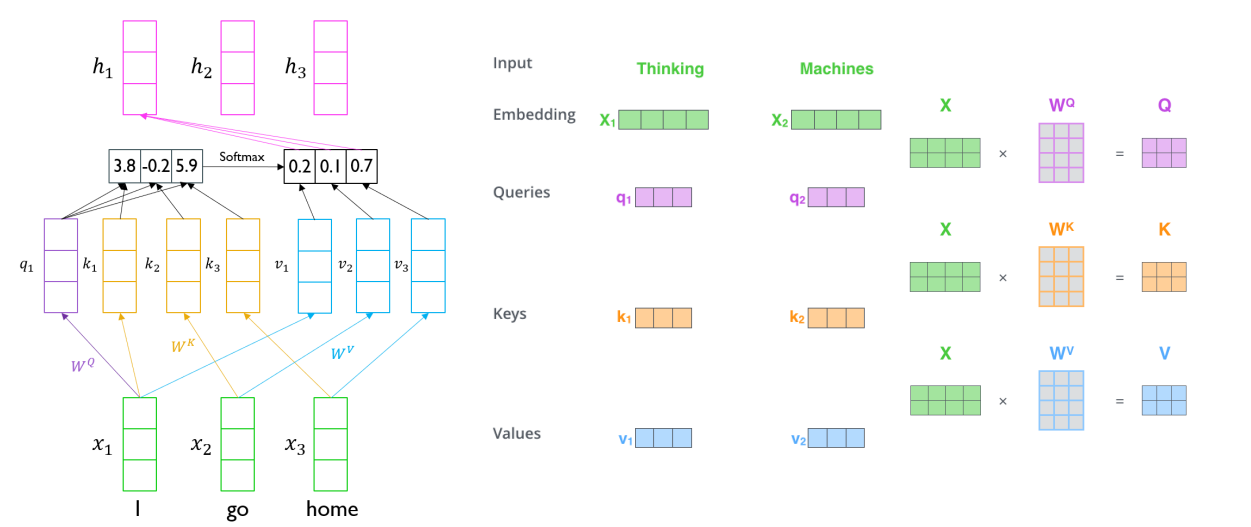
- Inputs: q, k, v
- Query, Key, Value, Output은 모두 벡터이다.
- Output은 value들의 weighted sum으로 구해진다.
- 각 value의 weight는 query와 대응하는 key의 내적에 의해 구해진다.
- Query와 Key의 차원은 로 같고 value의 차원은 라고 할 때

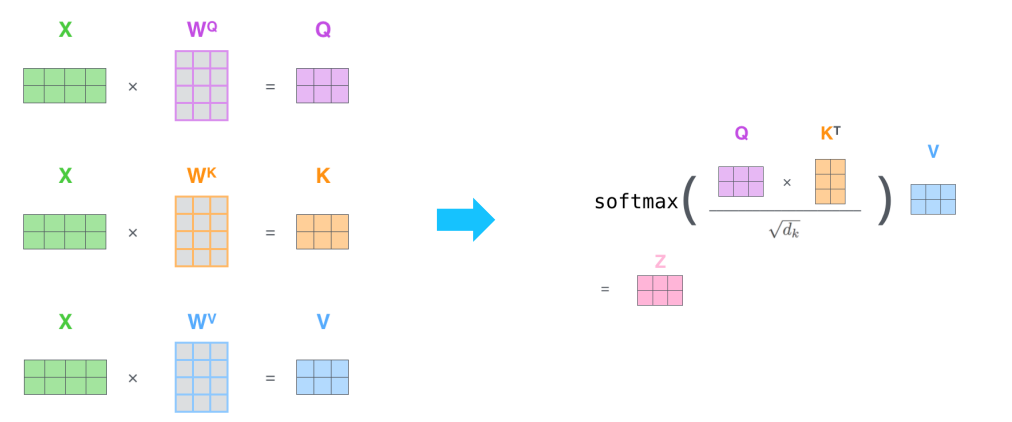
- 문제점
- 차원이 크면 분산이 커지고 표준편차가 커져서 큰 값에 몰리는 현상이 발생한다.
- 따라서, gradient vanishing 현상이 발생한다.
- 학습을 안정화시켜주기 위해서 를 나눠주어 다음과 같은 식이 나온다.
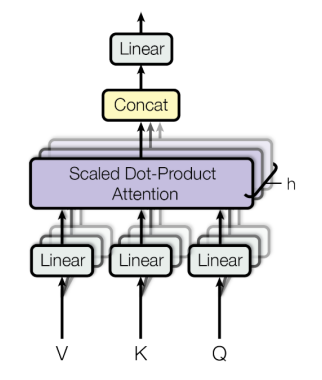
Transformer: Multi-Head Attention
-
input: query, key, value
-
single attention의 문제점: 단어들이 서로 상호작용하는 방법이 오직 하나!
-
해결책: Multi-head attention
- head별로 서로 다른 측면의 정보를 상호보완적으로 얻어낸다.
- ex) 1. 행동중심 2. 장소정보중심 등 (I went to school)
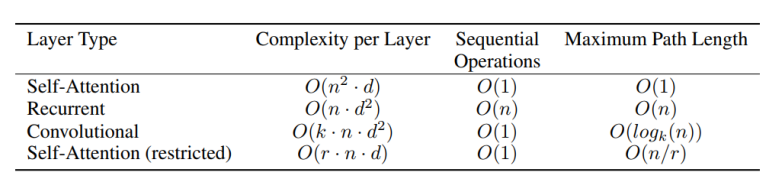
-
다음은 다양한 계층 유형에 대한 연산 수, 복잡도, path 최대 길이 등을 보여준다.
Transformer: Block-Based Model
- 각 블록은 2개의 sub-layer를 가진다.
- Multi-head attention
- Two-layer feed-forward NN (with ReLU)
- 또한, 각각은 Residual connection과 layer normalization을 지닌다.
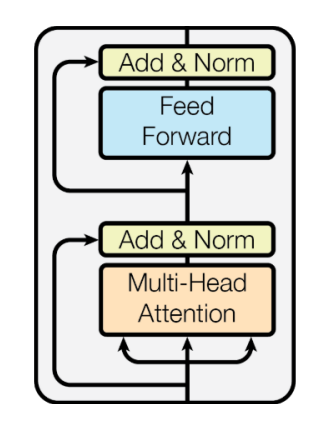
Transformer: Positional Encoding
- 위치에 대한 정보를 넣어준다.
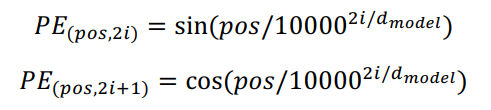
Transformer: Long-Term Dependency
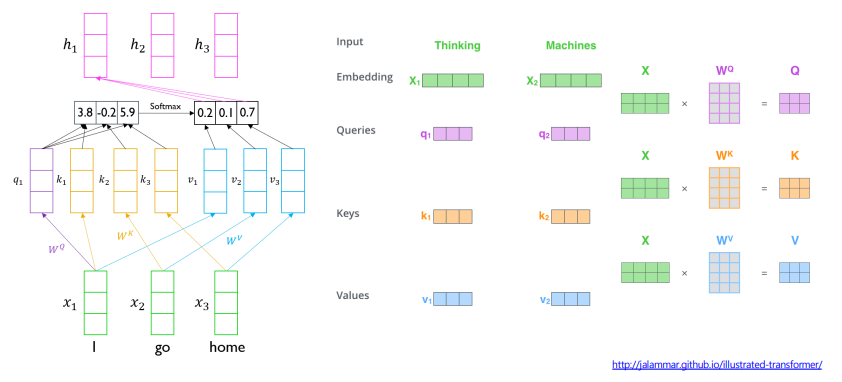
Transformer: Warm-up Learning Rate Scheduler
Transformer: Encoder Self-Attention Visualization
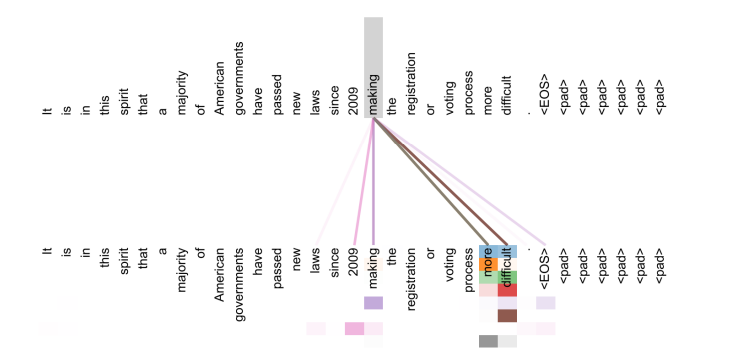
- 각 head마다 다른 정보에 집중하는 모습을 볼 수 있다.
Transformer: Decoder
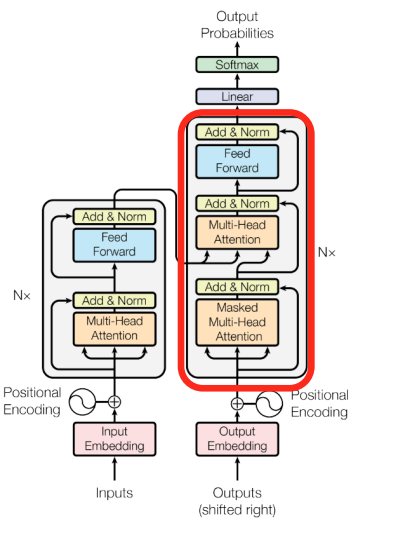
- 이전의 output으로 Masked decoder self-atention 진행
- encoder-decoder attention에서는 decoder의 query와 encoder의 output인 key, value가 합쳐진다.
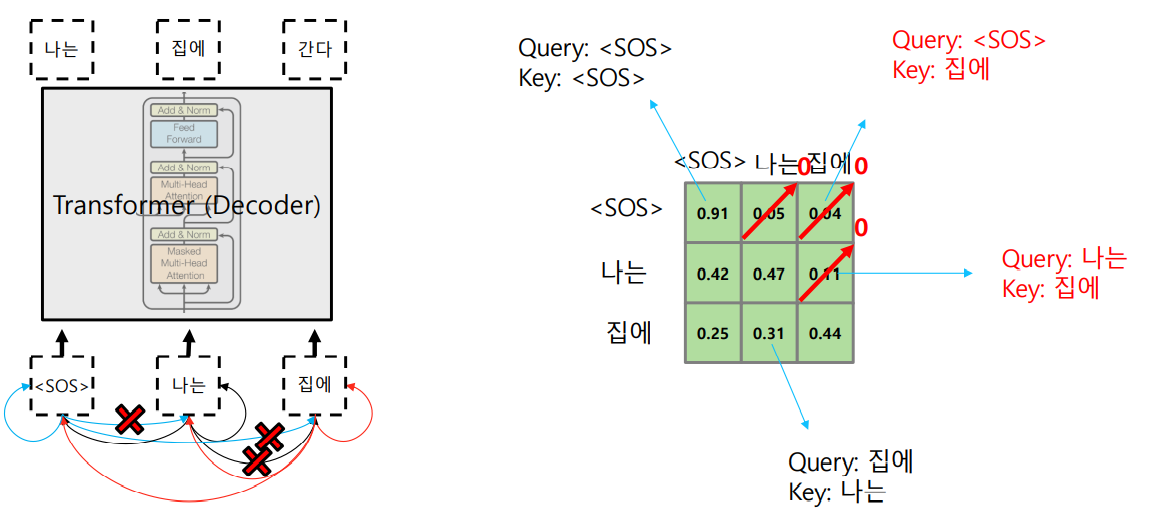
Transformer: Masked Self-Attention
- inference중에는 아직 생성되지 않은 word를 접근할 수 없다.
- softmax인 output값을 renormalization하여 생성되지 않은 단어에 접근하는 것을 막는다.
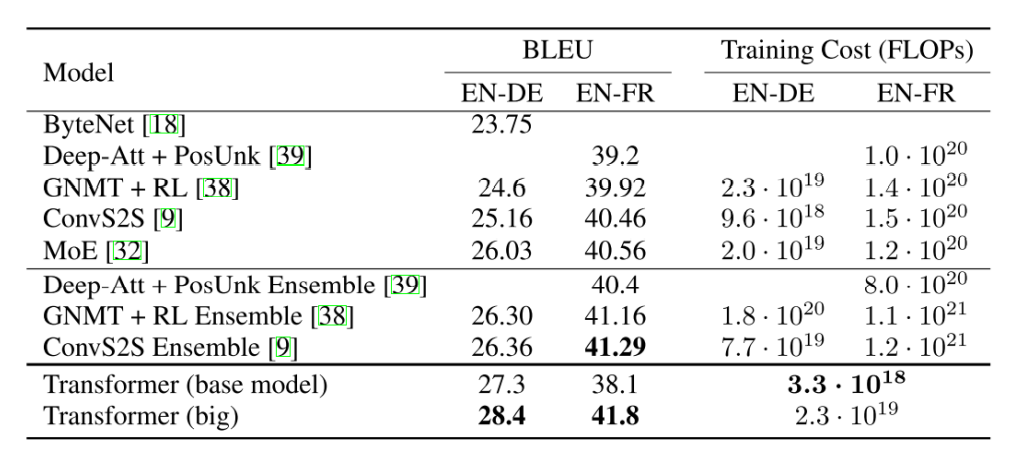
Transformer: Experimental Results
3. 회고
- 트랜스포머에 대해 예전보다는 이해가 되는 느낌을 받았다.
4. 내일 할일
- 트랜스포머 논문 읽기

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.