
1. 오늘 일정
1) 강의 수강
2) 과제
3) 오피스 아워
4) 멘토링
2. 학습 내용
NLP
9강: Self-supervised Pre-training Models
최근 트렌드
- NLP뿐만 아니라 다른 분야에서도 트랜스포머와 Self-attention block이 일반적인 구성이 되었다.
- self-supervised learning을 위한 Transformer를 쌓아서 깊게 학습하는 방식이 다양한 NLP 분야에서 향상된 결과를 가져 왔다.
- BERT, GPT-3, XLNet, ALBERT, RoERTa, Reformer, T5, ELECTRA...
- 다른 분야에서도 self-attention과 Transformer 구조에 대해 빠르게 적응중이다.
- 추천 시스템, 컴퓨터 비전, 약물 발견 등
- greedy decoding의 관점에서 한계는 존재.
GPT-1
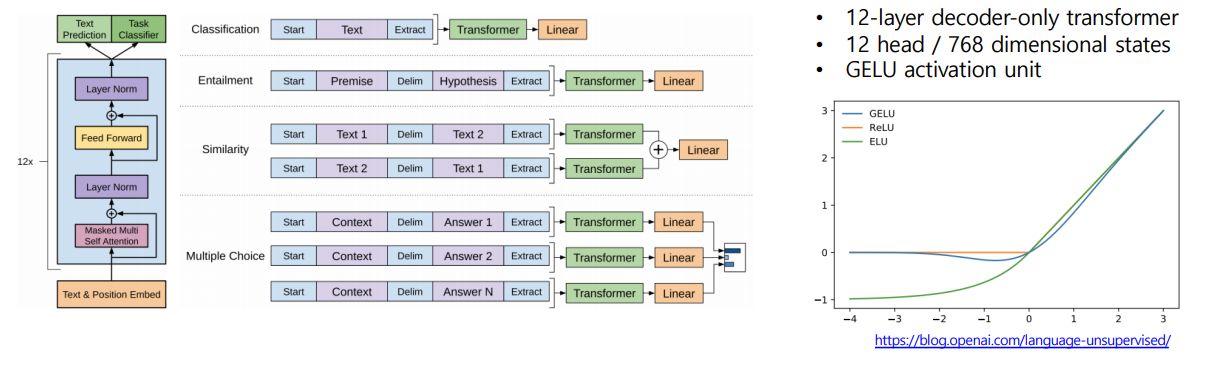
- < S >,< E >,$ 등의 다양한 special token을 활용하여 fine-tuning시의 성능을 극대화 한다.
- 같은 transformer 구조를 별도의 학습 없이 여러 task에서 활용할 수 있다.
BERT
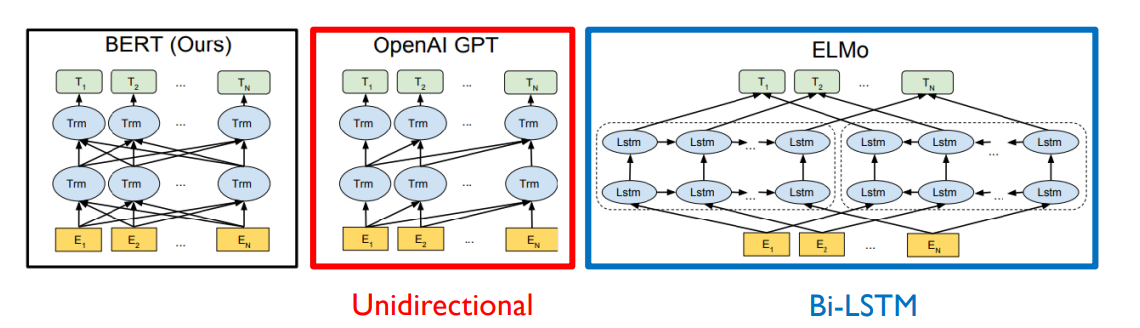
- masked language modeling을 통해 학습
Masked Language Model
- 원인: 기존의 Language model은 오직 왼쪽 혹은 오른쪽 문맥만 사용한다. 하지만, 언어를 이해하기 위해서는 bi-directional하게 살펴봐야 한다.
- 방법: 각 단어를 일정 확률로 Mask로 치환해서 맞추도록 한다.
- 단어의 15%를 예측하도록 한다.
- 80%는 [MASK]로 치환된다.
- 10%는 random한 단어로 치환된다.
- 10%는 유지한다.
the man went to the [Mask] to buy a [MASK] of milk- making이 너무 적다면 학습이 안되고, 너무 많다면 문맥을 파악할 수 없다.
Next Sentence Prediction (NSP)
- 두 문장 A, B를 주어, B가 실제로 A의 뒤에 오는 문장인지 예측하도록 한다.

BERT 요약
1. Model Architecture
- BERT BASE: L = 12, H = 768, A = 12
- BERT LARGE: L = 24, H = 1024, A = 16
- Input Representation
- WordPiece embeddings (30,000 WordPiece)
- Learned positional embedding
- [CLS] - Classification embedding
- Packed sentence embedding [SEP]
- Segment Embedding
- Pre-training Tasks
- Masked LM
- Next Sentence Prediction
BERT: Fine-tuning Process
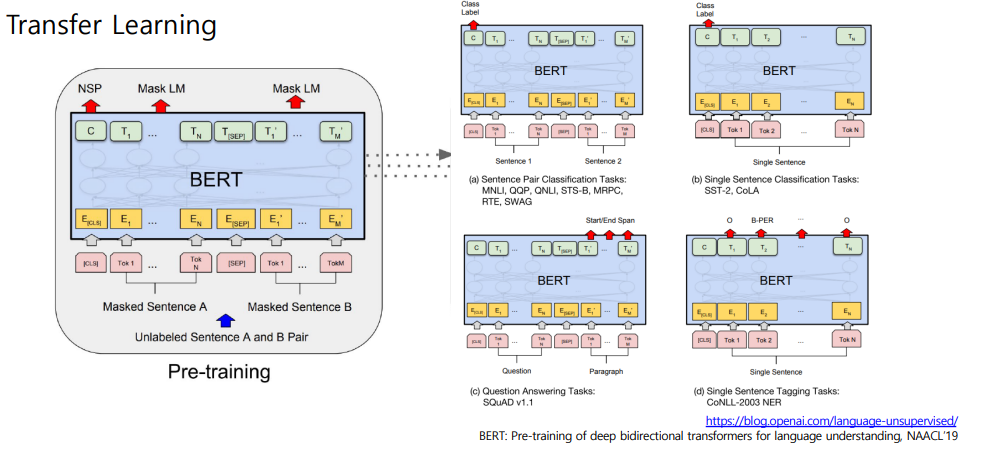
BERT vs GPT-1
- Traning 데이터 사이즈
- GPT: 800M words (BookCorpus)
- BERT: 2,500M words (BookCorpus and Wikipedia)
- Training tokens during training
- BERT: [SEP], [CLS], sentence A/B embedding을 학습한다.
- Batch size
- GPT: 32.000 words
- BERT: 128,000 words
- Task-specific fine-tuning
- GPT: 5e-5의 학습률을 동일하게 적용
- BERT: task별로 다른 lr을 적용
BERT: GLUE Benchmark Results
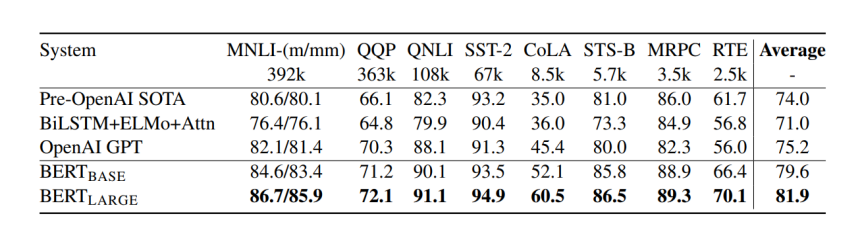
BERT: SQuAD
SQuAD 1.1
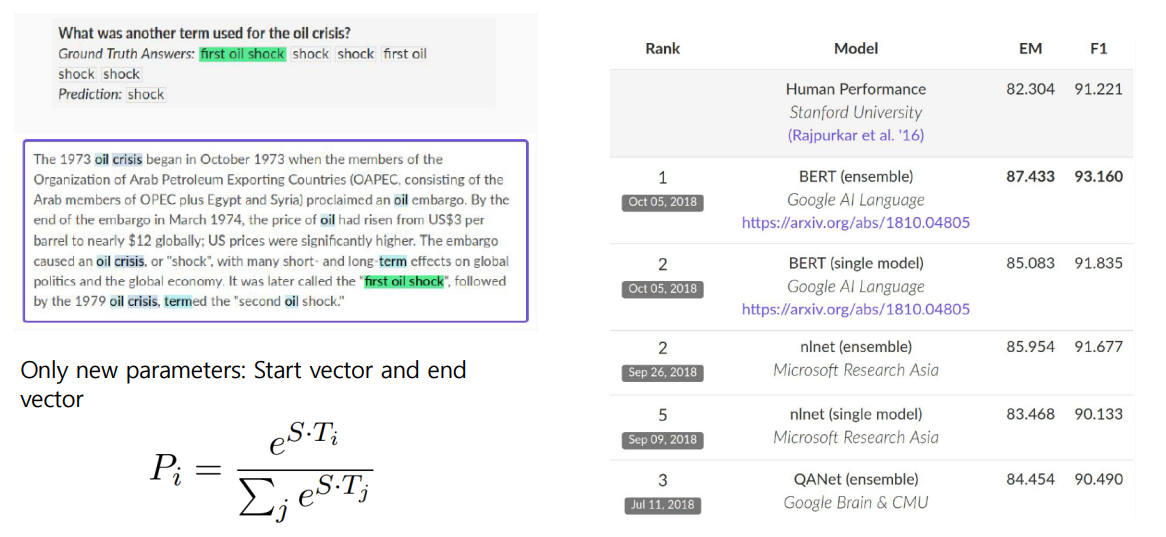
- start word와 ending word에 대해 FCL을 두어 Fine Tuning을 진행한다.
SQuAD 2.0
- no answer를 포함시킨다.
BERT: On SWAG

- 다수 문장에서 다음에 나타날 문장을 예측
BERT: Ablation Study
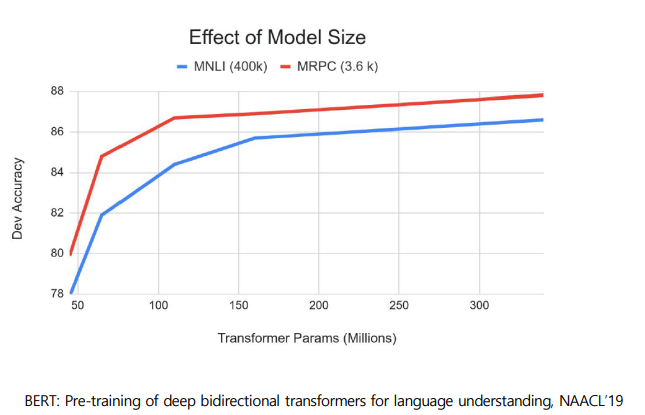
- 모델이 크면 클수록 도움이 된다.
10강: Advanced Self-supervised Pre-training Models
GPT-2
- 단지 정말 큰 Transformer Language Model
- 40GB의 텍스트로 Train 됨
- 데이터셋의 품질을 높이기 위해서 상당한 노력을 했다고 함
- zero-shot setting으로 작업을 수행할 수 있다.
GPT-2: Datasets
- 웹 크롤링과 같은 방법으로 다양한 text를 모을 수 있었음.
- 레딧, 소셜 미디어 플랫폼, 웹텍스트 등으로 부터 스크랩함.
- 45M links
- 사람이 페이지를 필터링
- 최소 좋아요 3개를 받은 페이지
- Byte pair encoding (BPE)로 전처리
GPT-2: Model (변경점)
- Layer normalization은 각 sub-block의 인풋으로 옮겨졌다.
- 마지막 self-attention block뒤에 layer normalization이 추가 되었다.
- 모델 깊이에 따른 residual path의 누적에 관한 부분의 초기화 방법이 변경되었다.
- N이 residual layer의 수라 할 때, residual layer의 가중치에 을 곱했다.
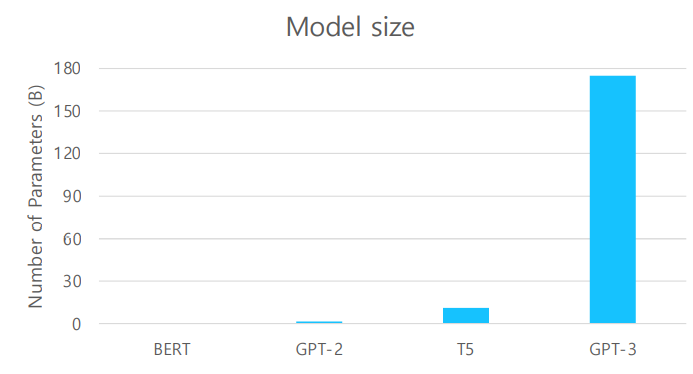
GPT-3
- Language Model들은 few shot learning이 목표!
- few shot learning: 풀고자 하는 문제에 대해 몇 개의 예시만 보고 태스크에 적응하여 문제를 푸는 것
- 모델의 크기를 키우는 것은 few-shot performance를 향상시켰다.
- 175 billion parameter로 few-shot setting
- 96 Attention layers, 3.2M의 배치 사이즈
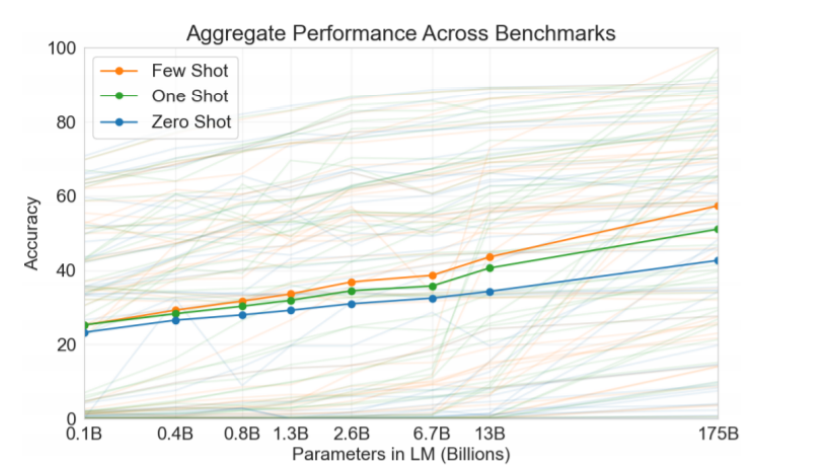
Zero-shot: 오직 자연어의 서술만으로 답을 예측
One-shot: 하나의 예제를 추가
Few-shot: 약간의 예제를 추가
Performance
- Zero-shot performance는 모델 사이즈와 함께 일정하게 증가
- Few-shot performance는 더욱 빠르게 증가

ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- 큰 모델의 한계
- Memory 제한
- Training 속도
다음의 해결책들이 제시되었다.
1) Factorized Embedding Parameterization
- 임베딩 벡터에서는 적은 정보로도 충분하다.
- 따라서, 다음과 같이 Factorize가 가능하다.
- V = Vocabulary size
- H = Hidden-state dimension
- E = Word embedding dimension
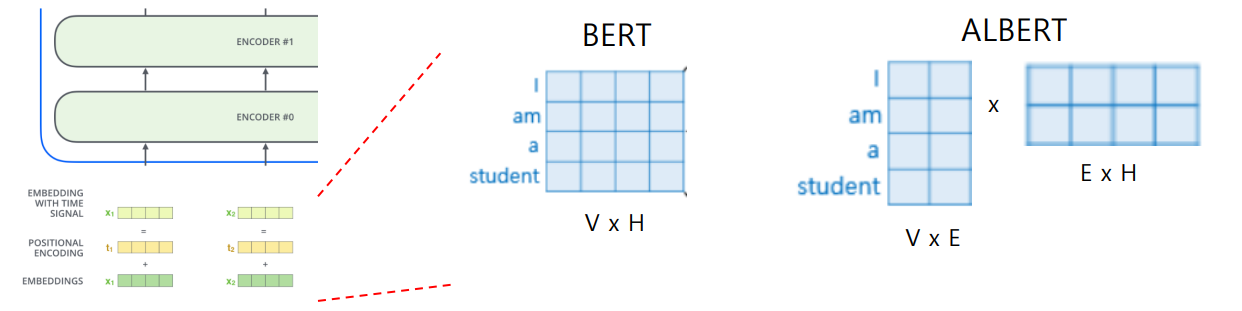
2) Cross-layer Parmeter Sharing
- Shared-FFN: layer별로 오직 feed-forward network parameter 공유
- Shared-attention: layer별로 오직 attention parameter 공유
- All-shared: 위 둘을 합친 경우
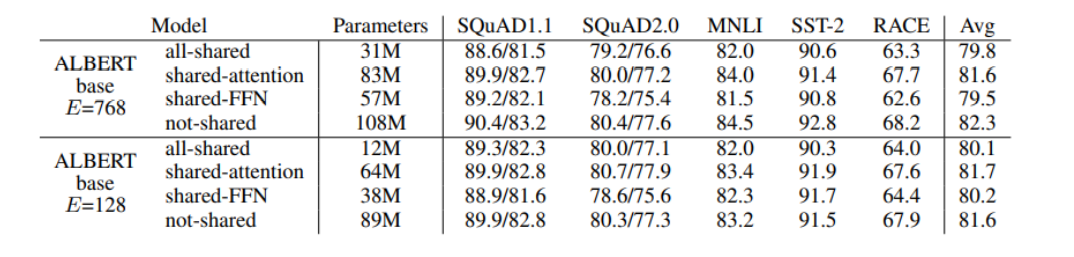
- Parameter는 줄면서 성능은 크게 차이가 없음을 볼 수 있다.
- 기존의 모델에서 파라미터가 많이 논다고 생각해도 되겠다.
3) (For Performance) Sentence Order Prediction
- 기존의 NSP (Next Sentence Prediction)은 효과가 미미했음.
- 따라서 연속된 문장이지만 순서가 바뀐 sequence를 넣어주어 SOP (Sentence Order Prediction)을 수행

- NSP의 경우, SOP를 해결하지 못하지만, SOP는 NSP에서도 어느정도 높은 성능을 보인다.
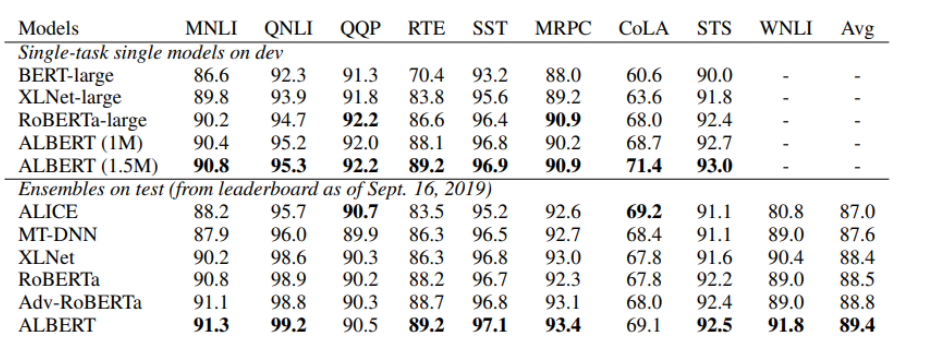
GLUE Results
ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately
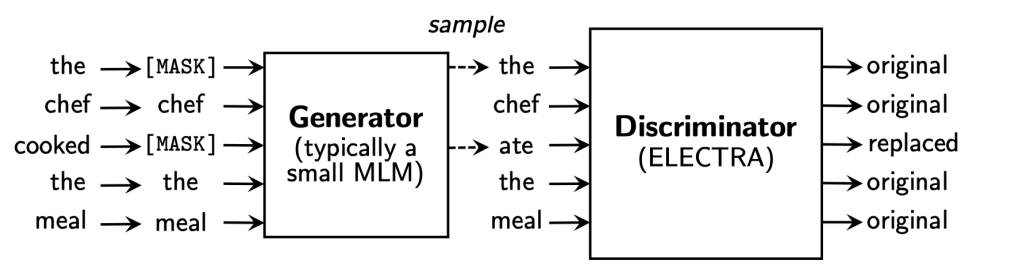
- Generator에서 Masking된 단어를 복원하여 Discriminator에서 original인지 replaced인지 분류하는 모델
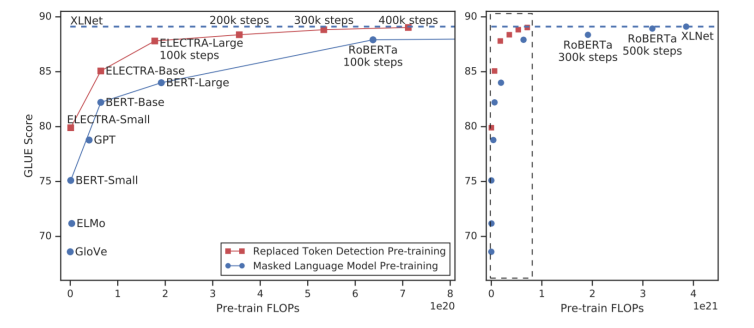
- 같은 조건의 BERT모델보다 훨씬 높은 성능을 보임.
Light-weight Models
- DistillBERT
- tearcher model과 student model을 두어서 경량화 시킨다.
- TinyBERT
Language Model에서의 외부정보 결합
- ERNIE
- KagNET
3. 피어 세션 정리
- BERT에 대한 논문 발표 경청
4. 과제 수행 과정
- hugging face 사용법 등 천천히 익혀야될듯 함.
5. 회고
- NLP 강의가 끝났다. 강의를 듣기 전과 후, 확실히 트랜스포머와 관련해서는 어느정도 이해가 되었다.
- 논문도 처음 읽어보았는데, 매주 하나씩은 꾸준히 읽으려고 노력해야겠다.
6. 내일 할일
- 마무리

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.