문제
세로 두 줄, 가로로 N개의 칸으로 이루어진 표가 있다. 첫째 줄의 각 칸에는 정수 1, 2, …, N이 차례대로 들어 있고 둘째 줄의 각 칸에는 1이상 N이하인 정수가 들어 있다. 첫째 줄에서 숫자를 적절히 뽑으면, 그 뽑힌 정수들이 이루는 집합과, 뽑힌 정수들의 바로 밑의 둘째 줄에 들어있는 정수들이 이루는 집합이 일치한다. 이러한 조건을 만족시키도록 정수들을 뽑되, 최대로 많이 뽑는 방법을 찾는 프로그램을 작성하시오. 예를 들어, N=7인 경우 아래와 같이 표가 주어졌다고 하자.
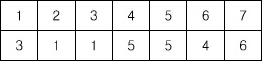
이 경우에는 첫째 줄에서 1, 3, 5를 뽑는 것이 답이다. 첫째 줄의 1, 3, 5밑에는 각각 3, 1, 5가 있으며 두 집합은 일치한다. 이때 집합의 크기는 3이다. 만약 첫째 줄에서 1과 3을 뽑으면, 이들 바로 밑에는 정수 3과 1이 있으므로 두 집합이 일치한다. 그러나, 이 경우에 뽑힌 정수의 개수는 최대가 아니므로 답이 될 수 없다.
# 2668
# pypy3로 제출하면 메모리초과가 발생한다.
import sys
input = lambda: sys.stdin.readline().strip()
sys.setrecursionlimit(10**9)
n = int(input())
graph = []
for _ in range(n+1):
graph.append([])
for i in range(1, n+1):
k = int(input())
graph[i] = k
visited = [[False] * (n+1) for _ in range(2)]
arr = []
def dfs(v, now_arr):
global n, graph, arr, visited
g = graph[v]
if visited[0][v] or visited[1][g]:
return 0
visited[0][v] = True
visited[1][g] = True
if visited[0] == visited[1]:
arr = arr + now_arr
else:
dfs(g, now_arr+[g])
visited[0][v] = False
visited[1][g] = False
for i in range(1, n+1):
visited = [[False] * (n+1) for _ in range(2)]
dfs(i, [i])
arr = list(set(arr))
arr.sort()
arr_len = len(arr)
print(arr_len)
for a in arr:
print(a)