
📌 Crawling
📖 Creawling을 사용하는 이유
현대사회에서의 빅데이터에 대한 지속적인 관심과 실험적인 시도들은 다변화된 현대 사회를 보다 정교하게 예측하고 효율적으로 작동하도록 정보를 제공하며, 개인화된 사회 구성원들에게 적합한 정보를 제공하고 관리하려는 목적에 기인한다.
실제로, 민간영역에서는 신용카드 이용 내역에 관한 정보부터 소셜미디어의 웹 데이터 등을 토대로 고객선호도를 분석하고, 고객의 구매 패턴과 실구매 트렌드를 파악해 개인 고객 수요에 맞는 맞춤형 정보 제공 등 마케팅에 적극 활용하고 있다.
📖 데이터 분석 과정
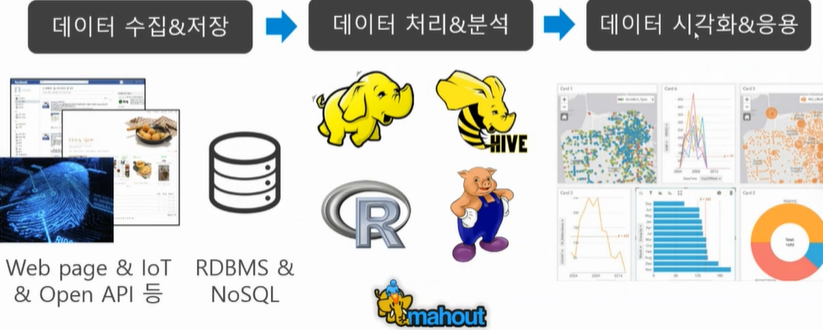
데이터를 분석하는 과정은 아래에 보이는것과 같다.
1. 데이터를 수집 및 저장을 하고
2. 데이터를 처리 및 분석을 하여 가공을 한며
3. 마지막으로 수집된 데이터를 시각화 시키고 응용하고 저장한다.
📌 수집데이터 형태
📖 정형 데이터(Structured)
데이터베이스의 정해진 규칙에 맞게 데이터를 들어간 데이터 중 수치만으로 의미 파악이 쉬운 데이터 를 뜻한다. Ex) 관계 DB, 스프레드시트, CSV, ..등
📖 반정형 데이터(Semi-Structured)
고정된 필드에 저장된 데이터는 아니지만, 메타 데이터 및 스키마를 포함하는 데이터를 뜻한다. Ex) XML, HTML 텍스트, JSON, ..등

📖 비정형 데이터(Unstructured)
고정된 필드에 저장되어 있지 않는 데이터를 뜻한다.
Ex) 소셜데이터(트위터, 페이스북), 영상, 이미지, 음성, 텍스트, ..등

위 3가지를 사용하여 웹 사이트의 내용에 접근하여 원하는 정보를 추출해 내는 행위를 Web Crawling이라고 한다.
📌 마무리
📖 추가 사항
📋 웹 페이지에서 데이터 수집할 때 생각할 것
- Web Page가 어떤 구조로 되어 있는가?
- 어떻게 원하는 데이터를 추출할 것인가?
📋 웹 크롤링을 위한 라이브러리
- requests : 접근할 웹 페이지의 데이터를 요청/응답 받기 위한 라이브러리
- BeautifulSoup : HTML문서에서 원하는 데이터를 추출하기 쉽게 해주는 라이브러리

숨쉬는 돌멩이, 말하는 감자.