
Underbar
- 자바스크립트 배열 내장 메서드(forEach, map, filter, reduce 등)의 원리를 이해한다.
- 콜백 함수 전달을 자유롭게 할 수 있다.
bareMinimum
// _.identity는 전달인자(argument)가 무엇이든, 그대로 리턴합니다.
// 이 함수는 underbar의 기능 구현 및 테스트를 위해 재사용되는 함수입니다.
_.identity = function (val) {
return val
};// _.take는 배열의 처음 n개의 element를 담은 새로운 배열을 리턴합니다.
// n이 undefined이거나 음수인 경우, 빈 배열을 리턴합니다.
// n이 배열의 길이를 벗어날 경우, 전체 배열을 shallow copy한 새로운 배열을 리턴합니다.
_.take = function (arr, n) {
let result = [];
if (n === undefined || n <= 0) return [];
if (n > arr.length) return arr
if (n <= arr.length) {
for (let i = 0; i < n; i++) { // arr.length -1 을 해도 통과.. 왜?
result.push(arr[i])
}
} return result
};// _.drop는 _.take와는 반대로, 처음 n개의 element를 제외한 새로운 배열을 리턴합니다.
// n이 undefined이거나 음수인 경우, 전체 배열을 shallow copy한 새로운 배열을 리턴합니다.
// n이 배열의 길이를 벗어날 경우, 빈 배열을 리턴합니다.
_.drop = function (arr, n) {
let result = [];
if (n === undefined || n <= 0) return arr
if (n > arr.length) return [];
if (n <= arr.length) {
result.push(arr[arr.length-1]) // 완벽히 이해는 안감
}
return result
};// _.last는 배열의 마지막 n개의 element를 담은 새로운 배열을 리턴합니다.
// n이 undefined이거나 음수인 경우, 배열의 마지막 요소만을 담은 배열을 리턴합니다.
// n이 배열의 길이를 벗어날 경우, 전체 배열을 shallow copy한 새로운 배열을 리턴합니다.
// _.take와 _.drop 중 일부 또는 전부를 활용할 수 있습니다.
_.last = function (arr, n) {
let result = [];
if (n === 0) return []
if (n === undefined || n < 0) return [arr.pop()]
if (n > arr.length) return arr
if (n <= arr.length) {
result.push(arr[arr.length-n], arr.length)
}
return result
};// _.each는 명시적으로 어떤 값을 리턴하지 않습니다.
_.each = function (collection, iteratee) {
if (Array.isArray(collection)) {
for (let i = 0; i < collection.length; i++) {
iteratee(collection[i], i, collection)
}
} else {
for (let obj in collection) { //of 썼다가 틀림
iteratee(collection[obj], obj, collection)
}
}
};// _.indexOf는 target으로 전달되는 값이 arr의 요소인 경우, 배열에서의 위치(index)를 리턴합니다.
// 그렇지 않은 경우, -1을 리턴합니다.
// target이 중복해서 존재하는 경우, 가장 낮은 index를 리턴합니다.
_.indexOf = function (arr, target) {
// 배열의 모든 요소에 접근하려면, 순회 알고리즘(iteration algorithm)을 구현해야 합니다.
// 반복문을 사용하는 것이 가장 일반적이지만, 지금부터는 이미 구현한 _.each 함수를 활용하여야 합니다.
// 아래 _.indexOf의 구현을 참고하시기 바랍니다.
let result = -1;
_.each(arr, function (item, index) {
if (item === target && result === -1) {
result = index;
}
});
return result;
};
// _.filter는 test 함수를 통과하는 모든 요소를 담은 새로운 배열을 리턴합니다.
// test(element)의 결과(return 값)가 truthy일 경우, 통과입니다.
// test 함수는 각 요소에 반복 적용됩니다.
_.filter = function (arr, test) {
let result = [];
_.each (arr, function (el) {
if (test(el)) {
result.push(el)
}
})
return result
};// _.reject는 _.filter와 정반대로 test 함수를 통과하지 않는 모든 요소를 담은 새로운 배열을 리턴합니다.
_.reject = function (arr, test) {
let result = [];
_.each (arr, function (el) {
if (!test(el)) {
result.push((el))
}
})
return result
// TIP: 위에서 구현한 `filter` 함수를 사용해서 `reject` 함수를 구현해 보세요.
};// _.uniq는 주어진 배열의 요소가 중복되지 않도록 새로운 배열을 리턴합니다.
// 중복 여부의 판단은 엄격한 동치 연산(strict equality, ===)을 사용해야 합니다.
// 입력으로 전달되는 배열의 요소는 모두 primitive value라고 가정합니다.
_.uniq = function (arr) {
let result = [];
_.each (arr, function (el) {
if(_.indexOf(result, el) === -1 ) {
result.push(el)
}
})
return result
};
// _.map은 iteratee(반복되는 작업)를 배열의 각 요소에 적용(apply)한 결과를 담은 새로운 배열을 리턴합니다.
// 함수의 이름에서 드러나듯이 _.map은 배열의 각 요소를 다른 것(iteratee의 결과)으로 매핑(mapping)합니다.
_.map = function (arr, iteratee) {
// TODO: 여기에 코드를 작성합니다.
// _.map 함수는 매우 자주 사용됩니다.
// _.each 함수와 비슷하게 동작하지만, 각 요소에 iteratee를 적용한 결과를 리턴합니다.
let newArr = [];
_.each(arr, function (el) {
// iterateee
newArr.push(iteratee(el));
});
return newArr;
};// _.pluck은
// 1. 객체 또는 배열을 요소로 갖는 배열과 각 요소에서 찾고자 하는 key 또는 index를 입력받아
// 2. 각 요소의 해당 값 또는 요소만을 추출하여 새로운 배열에 저장하고,
// 3. 최종적으로 새로운 배열을 리턴합니다.
// 예를 들어, 각 개인의 정보를 담은 객체를 요소로 갖는 배열을 통해서, 모든 개인의 나이만으로 구성된 별도의 배열을 만들 수 있습니다.
// 최종적으로 리턴되는 새로운 배열의 길이는 입력으로 전달되는 배열의 길이와 같아야 합니다.
// 따라서 찾고자 하는 key 또는 index를 가지고 있지 않은 요소의 경우, 추출 결과는 undefined 입니다.
_.pluck = function (arr, keyOrIdx) {
// _.pluck을 _.each를 사용해 구현하면 아래와 같습니다.
// let result = [];
// _.each(arr, function (item) {
// result.push(item[keyOrIdx]);
// });
// return result;
// _.pluck은 _.map을 사용해 구현하시기 바랍니다.
return _.map (arr, function (item) {
return item[keyOrIdx]
})
};//reduce 설명 생략
_.reduce = function (arr, iteratee, initVal) {
// TODO: 여기에 코드를 작성합니다.
// 일단 누적 값을 구해야 하니까 initVal를 변수 result에 할당
// arr요소를 돌면서 iteratee함수에 따라 result에 중첩
// initVal가 undefined 거나 0 일때
let result = initVal;
_.each(arr, function (ele, idx, collection) {
// 초기값 설정되있지 않을 경우
if(initVal === undefined && idx === 0) { /// 왜 idx === 0 이 있어야 하는가??
result = ele;
}
else {
result = iteratee(result, ele, idx, collection);
}
})
return result;
};비동기
- client : '서버로 접속하는 컴퓨터' (보통 우리의 컴퓨터)
- Server : '무언가(서비스, 리소스 등)을 제공하는 컴퓨터 (웹, 게임 서버 등)

Callback
순서를 제어하고 싶은 경우
const printString = (string) => {
setTimeout(
() => {
console.log(string)
},
Math.floor(Math.random() * 100) + 1
)
}
const printAll = () => {
printString("A")
printString("B")
printString("C")
}
printAll() // ?????????
순차적으로 A,B,C를 제어할 수가 없다
그래서 콜백함수를 사용
const printString = (string, callback) => {
setTimeout(
() => {
console.log(string)
callback()
},
Math.floor(Math.random() * 100) + 1
)
}
const printAll = () => {
printString("A", () => {
printString("B", () => {
printString("C", () => {})
})
})
}
printAll() // now ????????callback 함수를 받아 실행해주고,
A를 실행하고, 또 callback을 받아 넘김
callback 함수 안에서 B를 실행하고 또다른 callback
....
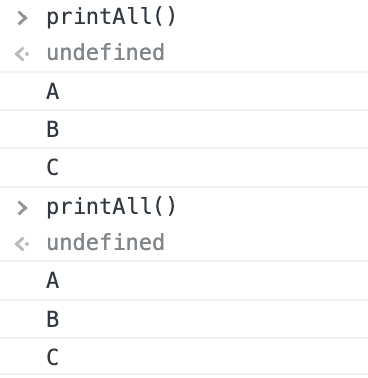
ABC 순서를 지켜서 출력
const somethingGonnaHappen = callback => {
waitingUntilSomethingHappens ()
if (isSomethingGood) {
callback(null, something) // callback에 인자를 넘겨 줌
}
if (isSomethingBad) {
callback(something, null)
}
}somethingGonnaHappen((err, data) => {
if (err) {
console.log('ERR!!');
return;
}
return data;
})사용자를 고려해서 애초에 콜백을 인자로 받아서 설계 가능
일반적으로는 앞에 에러를 주고 뒤에 데이터를 넣어 준다.
앞으로 API나 library를 쓰든 앞에 에러를 쓰고 뒤에 결과값을 가지고 오는 경우가 많이 생길 것임
Promise
const printString = (string) => {
return new Promise((resolve, reject) => { //promise 낟의 콜백을 받음
setTimeout(
() => {
console.log(string)
resolve() // 위에서 인자로 받았던 resolve를 받음
// 만약 에러가 발생하는 경우엔 reject도 사용
},
Math.floor(Math.random() * 100) + 1
)
})
}
const printAll = () => {
printString("A")
.then(() => { // .then으로 이어나갈 수 있음
// printString이 끝나면 다음 함수를 실행해줘~
return printString("B")
})
.then(() => {
return printString("C")
})
}
printAll()동작은 콜백과 동일하게 동작
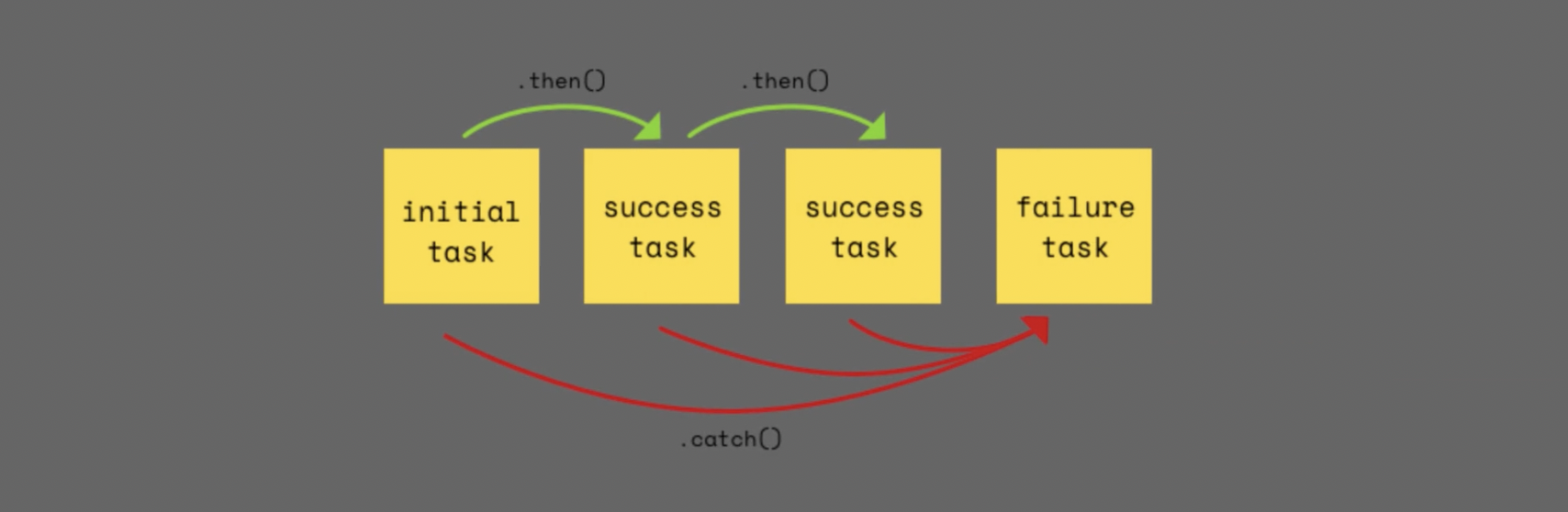
첫 테스크가 끝나고 나서 다음 태스크를 진행할 수 있다
기존에 콜백에서 에러를 넘겨주는 함수를 이용했다면 -> 콜백을 처리할 때마다 에러처리를 해줘야함
근데 프로미스를 사용하면 .then, .then -- 해서 마지막에 catch를 이용해 에러를 잡아 낼 수 있다.
하지만 Promise를 활용한 방식 역시 Callback 함수를 이용한 방법과 마찬가지로 메소드들이 엄청나게 중첩되게 되면 코드의 가독성이 떨어지게 된다. (Promise Hell)
function wakeUp() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('wake up') }, 100)
})
}
function dailyCoding() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('dailyCoding') }, 100)
})
}
function haveMeal() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('haveMeal') }, 100)
})
}
function lol() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('lol') }, 100)
})
}
wakeUp()
.then(data => {
console.log(data)
dailyCoding()
.then(data => {
console.log(data)
haveMeal()
.then(data => {
console.log(data)
lol()
.then(data => {
console.log(data)
})
})
})
})promise hell
⬇️
promise chain
wakeUp()
.then(data => {
console.log(data)
return haveMeal()
})
.then(data => {
console.log(data)
return drinkSoju()
})
.then(data => {
console.log(data)
return sleep()
})
.then(data => {
console.log(data)
})ASYNC / AWAIT
const result = async () => {
const one = await wakeUp();
console.log(one)
const two = await dailyCoding();
console.log(two)
const three = await haveMeal();
console.log(three)
const four = await lol();
console.log(four)
}
result (); // wake up, dailyCoding, haveMeal, lol비동기 함수들을 마치 동기적인 프로그램인 것처럼 사용.
function wakeUp() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('wake up') }, 200)
})
}
function dailyCoding() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('dailyCoding') }, 100)
})
}
function haveMeal() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('haveMeal') }, 500)
})
}
function lol() {
return new Promise((resolve, reject) => {
setTimeout(() => { resolve('lol') }, 10)
})
}
undefined
const result = async () => {
const one = await wakeUp();
console.log(one)
const two = await dailyCoding();
console.log(two)
const three = await haveMeal();
console.log(three)
const four = await lol();
console.log(four)
}시간을 변경해도 조금 늦게 실행될 뿐 순차적으로 출력
