game-tree
1.최대최소 탐색을 활용한 삼목게임(tic-tac-toe)

인공지능 과목을 공부하면서 배운 게임트리를 실제로 구현해보고자 간단한 삼목게임(tic-tac-toe)을 만들어보았습니다. 게임트리는 최대최소 탐색을 통해 작성됩니다.
2.알파-베타 가지치기를 활용한 삼목게임(tic-tac-toe)
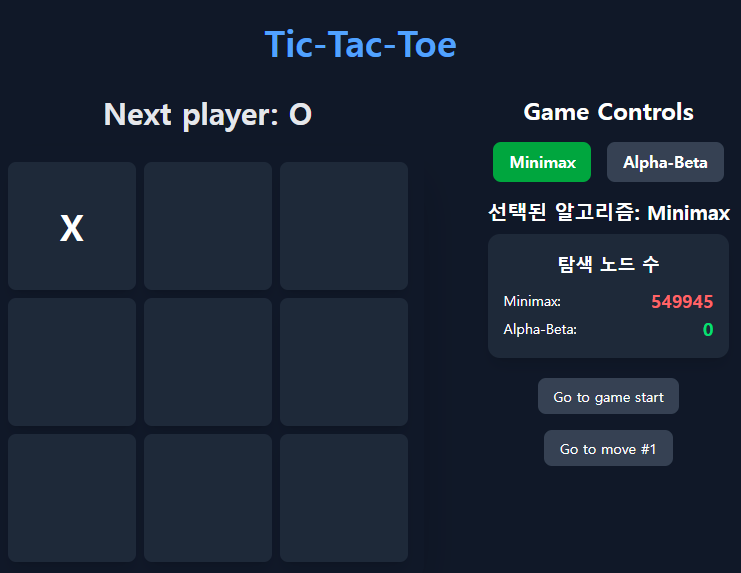
알파-베타 가지치기 방법을 도입하여, 기존의 최대최소 탐색에 비해 탐색량을 크게 줄일 수 있었습니다.아래는 첫 수 착수에 필요한 탐색량을 비교한 것입니다.약 55만 -> 약 1만 7천
3.오셀로(Othello) 게임 AI - 최대최소(Minimax) 탐색 알고리즘 적용
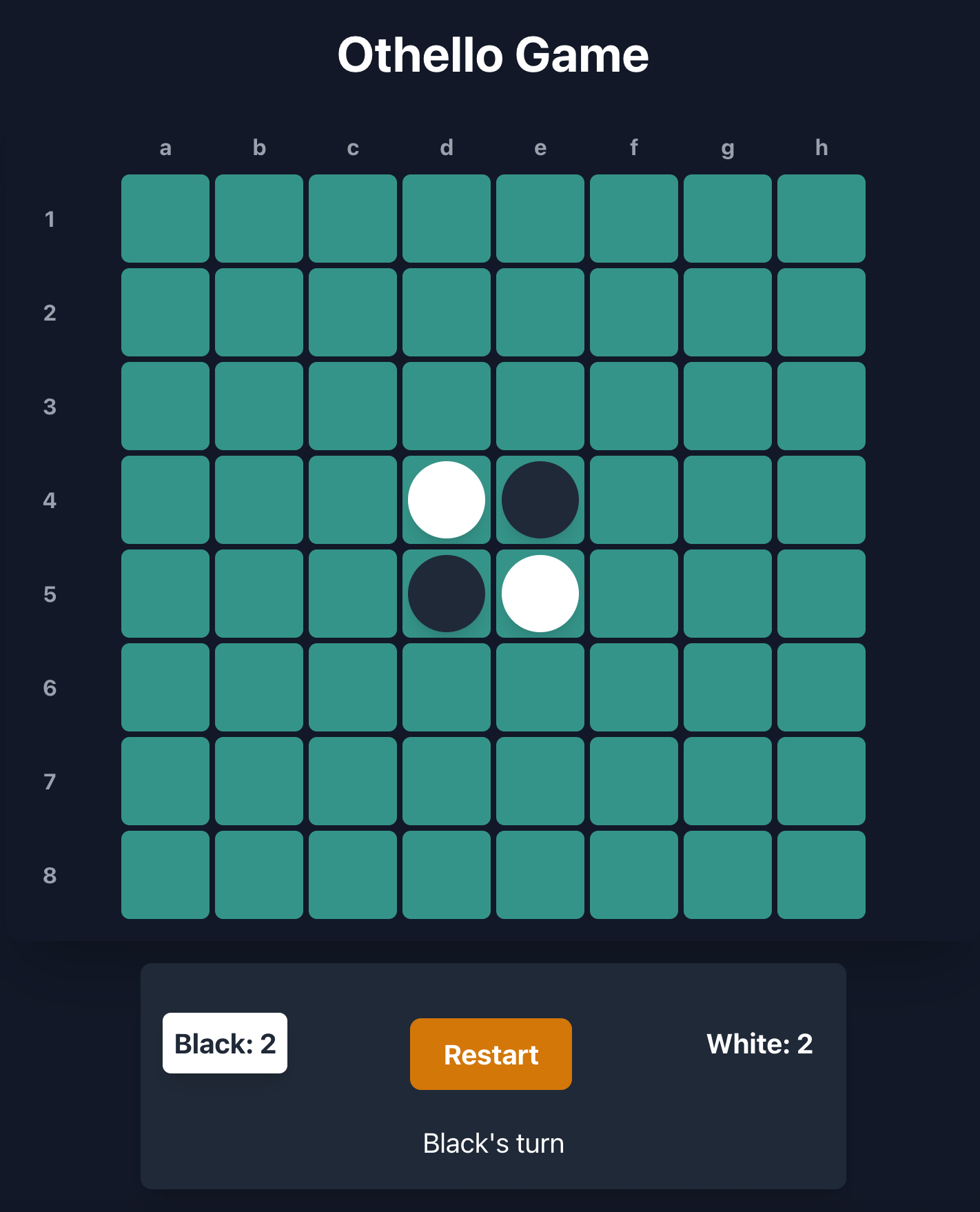
최대최소(Minimax) 탐색 알고리즘을 통해 오셀로(Othello)를 플레이하는 AI를 구현해 보았습니다.
4.오셀로(Othello) 게임 AI 2 - 평가 함수 개선(위치 가중치 맵 적용)
평가 함수를 개선하기 위해 위치 가중치 맵을 적용하고, 이어 시뮬레이션을 통해 성능을 검증해보았습니다.
5.오셀로(Othello) 게임 AI 3 - 알파-베타 가지치기(alpha-beta pruning) 적용
탐색량을 줄이기 위해 알파-베타 가지치기 방법을 도입했습니다. 탐색 함수 또한 negamax를 참고하여 단일 호출 함수로 리팩토링 했습니다. 자체 경기 시뮬레이션 결과, 최대 탐색 깊이 변화에 따른 흥미로운 결과가 도출되었습니다.
6.오셀로(Othello) 게임 AI 4 - 무브 오더링(Move Ordering)을 통한 탐색 가속
무브 오더링(Move Ordering)을 적용하여 알파-베타 가지치기의 효율성을 높일 수 있었습니다. 이 과정에서 얕은 깊이로 유망한 수를 탐색하는 동적 정렬 방법과 위치 가중치 기반 정적 정렬 방법을 고안하고, 게임을 시뮬레이션 하여 결과를 도출했습니다.
7.오셀로(Othello) 게임 AI 5 - 비동기 AI와 새로운 패러다임: MCTS vs. IDDFS-αβ
지금까지 개발했던 Minimax가 아닌 새로운 탐색 패러다임으로 Monte-Carlo Tree Search 알고리즘을 구현하고 적용해보았습니다. 그리고 α-β 가지치기 알고리즘에 IDDFS를 적용한 AI 사이의 오셀로 게임 대결을 시뮬레이션 해보았습니다.
8.오셀로(Othello) 게임 AI 6 - MCTS 강화: 가중치 기반 시뮬레이션 (Lightweight Rollout)
Version 6에서는 MCTS의 롤아웃 전략을 강화하기 위해 위치 가중치를 반영해보았습니다. 승률의 개선이 유의미하지만, 여전히 약하다는 점이 아쉬웠습니다.
9.오셀로(Othello) 게임 AI 7 - MCTS Rollout 심화 실험 및 한계 분석
MCTS의 Rollout 전략을 수정해서 MCTS를 강화하려고 시도했습니다. 하지만 결국 실패했습니다. 이제 다른 방향을 모색해보려 합니다.
10.오셀로(Othello) 게임 AI 8(완) - MCTS 최종 실험: RAVE 하이퍼파라미터 튜닝
MCTS를 개선하기 위해 RAVE를 적용해 보았습니다. k값을 변경해가며 시뮬레이션을 진행했지만 결국 IDDFS-αβ를 상대로 승리하지 못했습니다. 그렇지만 배운점도 참 많았습니다.