
정말 오랜만에 글을 올리는데.... 오늘은 git의 내부 구조에 대해 정리해봤다.
Git을 사용하면서 git add, git commit 명령어를 수없이 입력하지만, 실제로 .git 폴더 내부에서 어떤 일이 일어나는지 고민해 본 적은 없는 것 같다. (정말 그냥 쓰기만 했다..)
여기서는 명령어가 무엇인지에 대해 기록하지 않는다. 진짜 구조를 파헤칠 예정이다.
그렇다면 우리가 작성한 코드는 어떤 과정을 거쳐 Github에 들어가게 될까?
크게 3단계를 거쳐 들어가게 된다.
Git Staging
- 코드를 작성한 뒤 commit 하려면 먼저 staging을 해야한다.
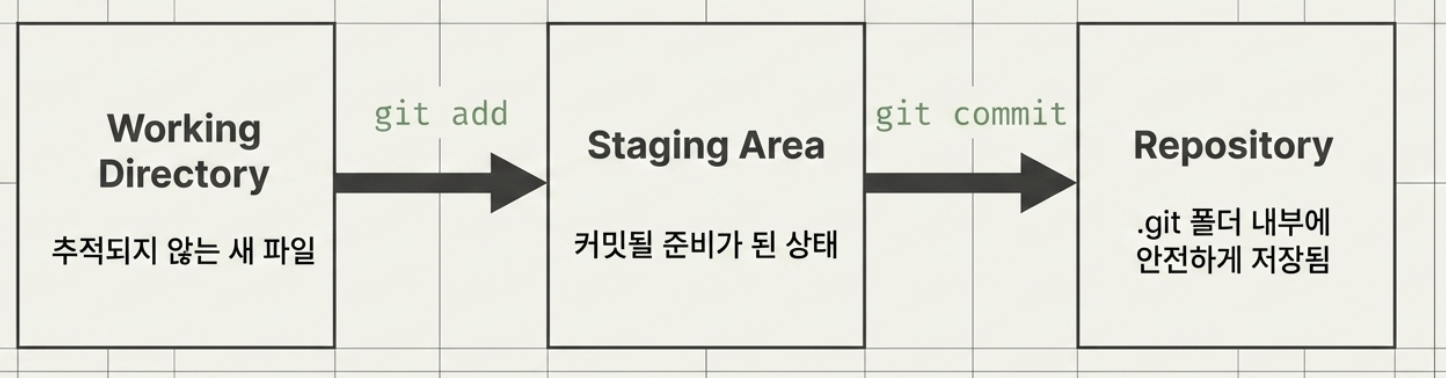
- Working Directory (작업 공간)
- 우리가 실제로 코드를 짜고 수정하는 곳
- 아직 Git이 추적하지 않는 새로운 파일이나, 방금 막 수정한 파일들이 널려있는 곳
- Staging Area (준비 공간)
git add명령어를 치면 책상 위에 있던 파일들이 '택배 상자'에 담깁니다. 즉 곧 창고로 보낼(커밋할) 준비가 완료된 상태
- Repository (저장 공간)
git commit명령어를 치면 택배 상자가.git폴더 안의 안전한 '금고' 속에 영구적으로 보관됨
우리가 git add 명령어를 실행하면 Git은 변경된 파일 내용을 다음 커밋에 포함할 대상으로 표시한다.
이 과정에서 Git은 파일 내용을 기반으로 객체를 만들고 스테이징 영역에는 다음 커밋에 어떤 내용이 들어갈지에 대한 정보가 반영된다.
즉 git add는 다음 커밋에 포함할 파일 상태를 확정하는 과정이라고 볼 수 있다.
이때 Git은 파일 내용을 기반으로 Blob 객체를 생성하고, staging area에는 해당 Blob을 참조하는 정보가 기록된다.
Git은 변경된 부분만 저장하는 것이 아니라 해당 시점의 전체 파일 상태를 snapshot 형태로 기록한다.
.git 폴더의 중요성
처음 시작할 때 git init을 할 텐데, git init 후 .git 폴더에 들어가면 아래 사진처럼 구조되어 있다. 이 중 중요한 건 objects라는 폴더다.
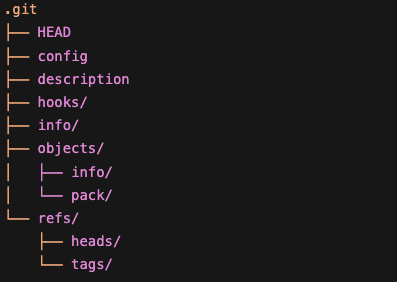
우리가 작성한 코드, 폴더 구조, 누가 언제 커밋했는지에 대한 모든 기록이 이 폴더 안에 저장되기 때문이다.
앞서 얘기한 스냅샷 데이터들이 쌓이는 곳이다.
이 폴더 안에 들어간 데이터는 원본 그대로 저장되는 것이 아니라 3가지 형태의 객체로 변환돼 압축저장한다.
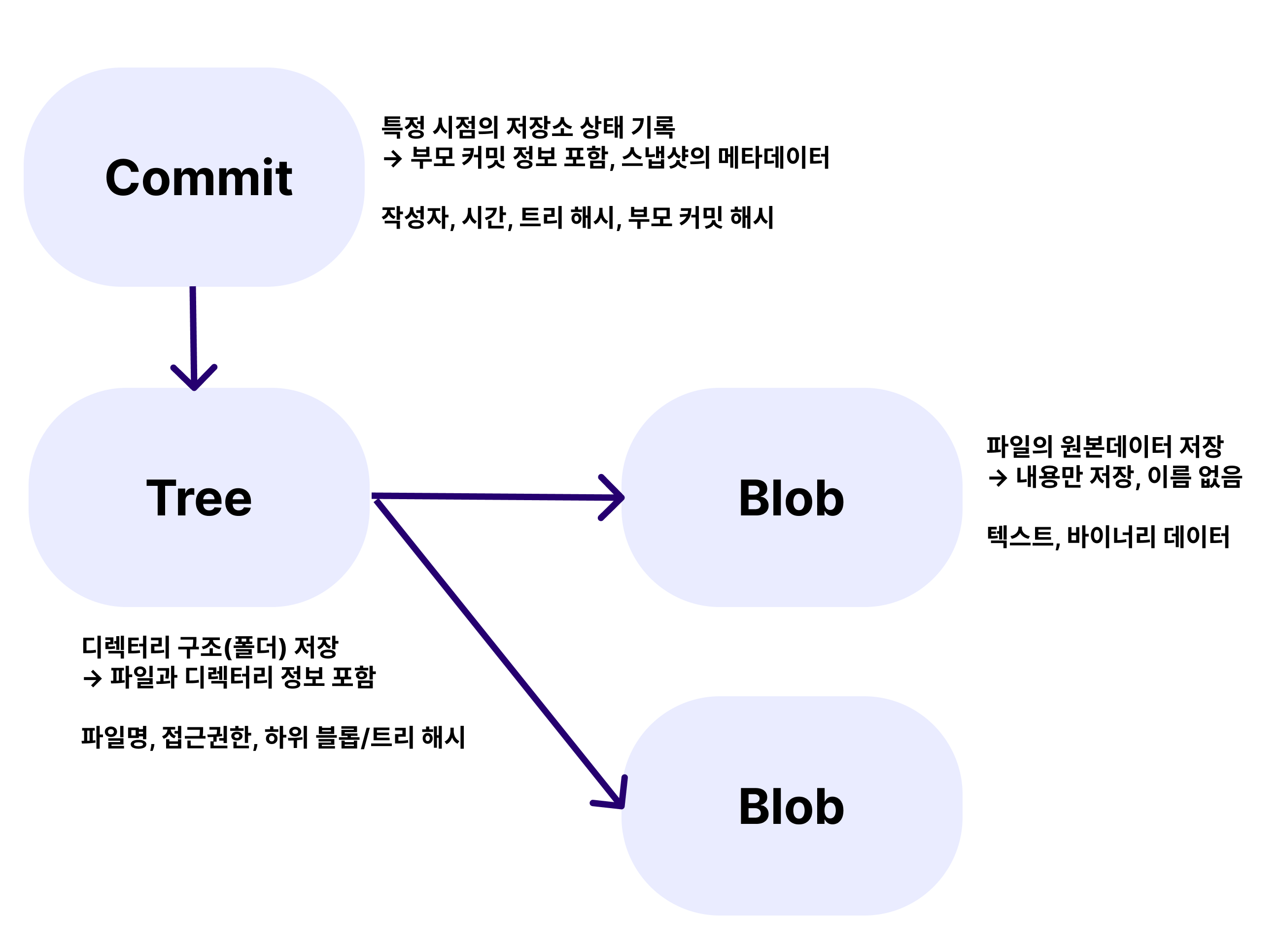
Git은 내부적으로 파일의 내용을 Blob, 디렉토리 구조를 Tree, 커밋 메타데이터를 Commit이라는 객체(Object)로 관리하며, 이 모든 데이터를 zlib로 압축하여 .git/objects 디렉토리에 저장한다.
이제 Git의 커밋 과정을 따라가며 객체가 어떻게 생성되고 변화하는지 낱낱이 파헤쳐 보자.
Git 저장소 초기화 & 파일생성
- 먼저 빈 디렉토리를 만들고 Git 저장소를 초기화해준다.
$ mkdir git-test && cd git-test
$ git init
$ find .git/objects -type f
→ 초기화 직후 디렉토리를 확인해보면 비어있다. 아무것도 출력되지 않는다. 마치 데이터가 하나도 없는 빈 DB가 생성된 것과 같다.
이제 테스트용 파일을 하나 생성해보자.
$ echo "hello git" > hello.txtgit add : Blob 객체
생성한 파일을 Staging Area에 올린다.
$ git add hello.txt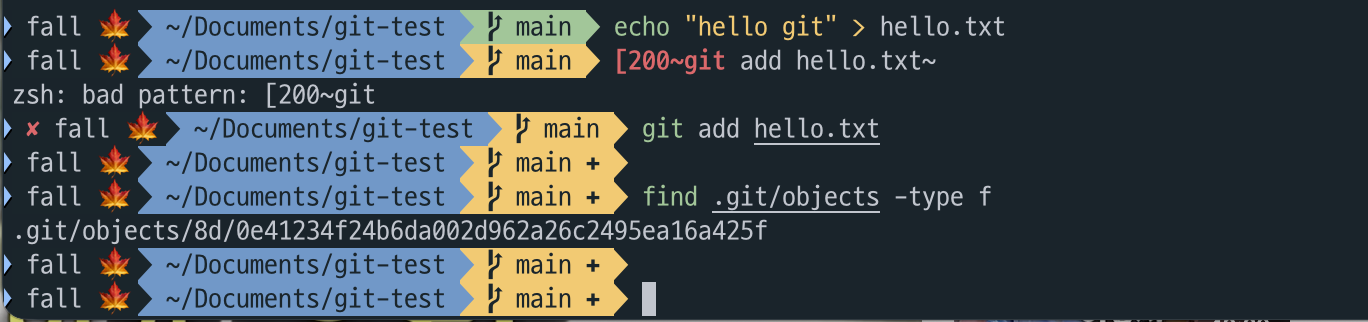
- 파일생성 후 ‘hello git’이라는 내용을 입력 했더니 변경이 감지돼서 색이 변한걸 알 수 있다.(현재 커스텀 터미널 테마 적용 중)
git add를 했더니 main 브랜치 옆에+표시가 생겼다. 파일이 Staging Area에 정상적으로 올라갔다는 뜻이다.
이제 .git/objects 폴더를 열어 확인해보면 새로운 파일이 생성된 것을 볼 수 있다.
- 이 파일이 바로
hello.txt의 내용을 담고 있는 Blob이라는 객체이다 - Git은 파일 내용의 SHA-1 해시값(8d0e41…)을 Key로 사용한다. 앞의 2자리는 디렉토리명 나머지는 38자리는 파일명으로 사용되 폴더 트리를 구성해 검색 속도를 높인다.
- 이 파일은
zlib로 압축되어 있고cat명령어로 읽으면 글자가 깨져 보인다.
Python zlib 라이브러리를 활용해 압축해제 후 내용을 확인해보자.
$ python3 -c '
import zlib
OBJECT_PATH = ".git/objects/8d/0e41234f24b6da002d962a26c2495ea16a425f"
print(zlib.decompress(open(OBJECT_PATH, "rb").read()))
'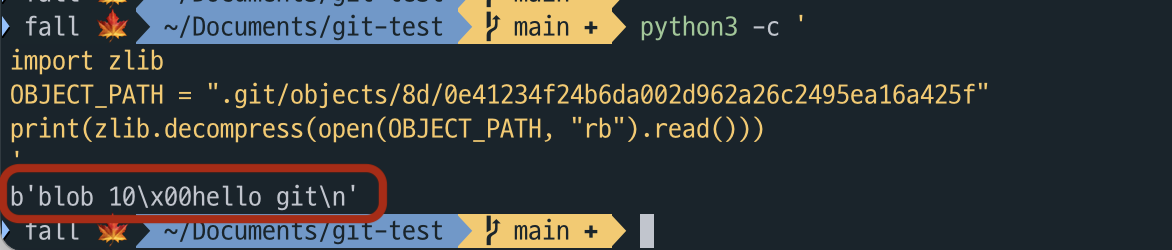
- 출력 결과를 보면 파일 이름(hello.txt)는 어디에도 없다.
- Blob 객체는 오직 파일의 원본 데이터(내용)만 저장하기 때문이다.
- 대신
[객체타입(blob)] [파일크기(10)]\0[파일내용(hello git)]형태로 헤더를 붙여서 저장한다.
Git commit : Tree와 Commit
이제 커밋을 생성해보자.
$ git commit -m "first commit"
커밋 후 .git/objets 폴더를 확인해보면 2개의 객체가 추가로 생성된 것을 확인할 수 있다.
$ find .git/objects -type f
추가된 두 객체의 내용도 압축을 풀어 확인해보자.
- Tree 객체 확인하기
Blob 객체에는 파일이름이 없었다. 그렇다면 파일 이름과 폴더 구조는 누가 기억할까?
바로 Tree 객체다.
$ python3 -c '
import zlib
print(zlib.decompress(open(".git/objects/07/ed5a7aebb914e3a02edf6d622b82d364037e3c", "rb").read()))
'
tree라는 타입과 함께 파일의 접근권한(100644), 파일명(hello.txt), 그리고 아까 git add 할 때 생성된 Blob 객체의 해시값(바이너리 형태)이 포인터처럼 연결되어 있는 것을 볼 수 있다.
- Commit 객체 확인하기
마지막으로 Commit 객체는 특정 시점의 저장소 상태 기록(스냅샷)을 담당한다.
# 본인의 .git/objects 폴더에 있는 커밋 객체 경로로 변경해서 실행!
$ python3 -c '
import zlib
# 예시: OBJECT_PATH = ".git/objects/7b/c94de71d075e2ae2ef4a8242ae0748a02b3a75"
OBJECT_PATH = "[본인의 Commit 객체 경로]"
print(zlib.decompress(open(OBJECT_PATH, "rb").read()).decode("utf-8"))
'
Commit 객체 안에는 방금 확인한 Tree 객체의 해시값(07ed5a...), 작성자 정보, 시간, 그리고 커밋 메시지(first commit)가 저장되어 있다. (만약 두 번째 커밋이었다면 parent [이전 커밋 해시] 정보도 포함되어 커밋 히스토리를 이어가게 된다.)
매일 무심코 치던 git commit 뒤에 이런 정교한 Key-Value 시스템이 숨어있다는 사실을 알고 나니, Git이 왜 그토록 빠르고 데이터 무결성을 잘 유지하는지 이해가 간다….
결국 Git은 파일이 아니라 객체와 포인터로 구성된 그래프 구조를 기반으로 동작한다.
