Redis

프로젝트를 진행 중 Refresh Token을 MySQL에 저장해 왔으나, 이는 중요한 데이터가 아닐 뿐만 아니라 조회 시 쿼리문 실행이 필요해 비효율적이였다. 그래서 외부 저장소에 저장하기로 하였고, 이런 Token 저장소와 캐싱 용도로 많이 사용되는 Redis를 도입하기로 하였다.
먼저 Refresh Token개념을 살짝 짚고 넘어가자.
Refresh Token
- 로그인을 완료하면 유효기간이 짧은
Access Token과 유효기간이 긴Refresh Token을 발급해준다. Access Token은 기존에 사용하던JWT라고 생각하면 되고Refresh Token은Access Token이 만료되었을 때 새로 발급해주는 토큰이라고 생각하면 된다.
과정
- 로그인을 하면
Access Token과Refresh Token을 발급해준다 - 클라이언트는 API를 호출할 때마다 발급받은
Access Token을 활용하여 요청을 한다 - 토큰을 사용하던 중 만료가 되어
Invalid Token Error가 발생한다면 사용자가 보낸 Access Token으로Redis의 Refresh Token을 찾아보고 Refresh Token이 유효하다면 Access Token을 다시 발급해준다 - Redis에 Refresh Token과 짝을 이루는 Access Token을 새로 발급한 토큰으로 업데이트한다.
- 만약 Refresh Token이 만료가 되면 다시 로그인을 하도록 요청하고 로그아웃 시 Refresh Token을 삭제하여 사용이 불가하도록 한다.
Refresh Token 개념을 활용하려면 서버측에서 토큰 정보를 저장할 수 있는 곳이 필요하고 사용하던 MySQL에 저장하기에는 중요한 데이터가 아닐 뿐더러 조회 시 쿼리문을 실행시켜야 해서 비효율적이였다. 그래서 Token처럼 빈번히 조회를 하는 경우 일반적인 디스크 I/O를 통한 DB보다는 메모리를 사용하는 Redis가 유리하다고 판단하였다.
하지만 이 과정에서 Redis의 사용법이나 개념등 모르는 것이 너무 많아 정리하려고 한다.
Redis(Remote Dictionary Server)
key : value형식의 dictionary 저장소- Strings, set, sorted-set, hashes, list
- Hyperloglog, bitmap, geospatial index
- Stream
- 쿼리를 사용할 필요가 없다.
In-Memory DataStructure Store- In-memory Database 로써 캐시(Cache) 영역에 존재하는 데이터베이스
- 프로세스로 존재하며 보통 remote에 존재함
- DB, Cache, Message Broker로 사용
- 디스를 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 빠르다
- Single Threaded
- 한 번에 하나의 명령만 처리할 수 있다.
- 중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 있는 명령어가 처리될 때까지 대기가 필요(하지만 get, set 명령어의 경우 초당 10만 개 이상 처리할 수 있을 만큼 빠름)
캐시라는 영역이 무엇인지 이해하려면 우선 메모리 계층에 대해 알아야 한다. 메모리는 아래처럼 크게 메모리 계층구조로 이루어져 있다.
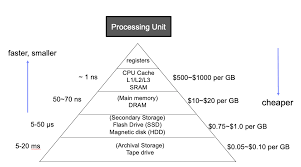
위로 갈 수록 빠르고 비싸며, 아래로 갈 수록 느려지고 저렴한 특징이 있다.
Cache
- 보통 데이터베이스는 컴퓨터가 꺼지더라도 데이터를 저장해야 하므로 SSD(디스크)에 데이터를 저장한다. 즉 데이터베이스 데이터에 접근하려면 시간이 조금 느리다
- Cache는 나중에 요청을 결과를 미리 저장해두었다가 빠르게 서비스를 해주는 것을 의미한다.
- 운영체제도 CPU가 디스크에 접근하는 속도가 느리므로, 중간에 캐시를 많이 둬서 이를 빠르게 사용하도록 한다.
- ex. Factorial -> 10! = 10 * 9! (9!를 캐싱해두면 연산이 훨씬 빨라짐)
- 데이터베이스 보다는 더 자주 접근하고 덜 자주 바뀌는 데이터를 Memory(메모리) 상에 저장해서 빠르고 쉽게 접근하자는 개념에서 등장한 것이 바로 In-memory Database(Cache) 인 Redis이다.
🧐 데이터베이스가 있는데 인메모리 저장소인 Redis를 사용하는 이유는 무엇일까?
- 우선 DB는 데이터를 디스크를 직접 쓰기 때문에 서버에 문제가 발생하여 다운되더라도 데이터 손실되지 않는다. 하지만 매번 접근해야 하기 때문에 사용자가 많아지면 부하가 많아 느려질 수 있다.
- 보통 규모가 작고 사용자가 많지 않은 서비스의 경우 WEB-WAS-DB의 구조로 사용하지만 사용자가 늘어난다면 DB에 과부하 될 수 있기 때문에 캐시 서버를 도입하여 사용한다.
- 캐시는 한 번 읽어온 데이터를 임의의 공간에 저장해 다음에 읽을 때 빠르게 결과값을 받을 수 있도록 도와주는 공간이다
- 같은 요청이 여러 번 들어오는 경우 매번 DB를 거치는 것이 아니라 캐시 서버에서 첫 번째 요청 이후 저장된 결괏값을 바로 내려주기 때문에 DB의 부하도 줄이고 속도도 느려지지 않는 장점이 있다.
웹 서버에서 사용되는 캐시 패턴
[보통 웹 서비스 구조]

- 캐싱 적용 x
- DB안에 모든 데이터가 존재하는 구조
- 디스크에 데이터를 저장하는 일반적인 구조
[ Look aside cache]
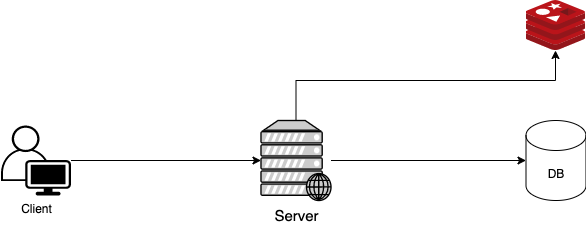
- 서버는 데이터가 존재하는지 Cache를 먼저 확인한다
- Cache에 데이터가 있으면 Cache에서 값을 가져온다(Cache Hit)
- Cache에 데이터가 없다면 DB에서 데이터를 가져와서 Cache에 저장하고 값을 가져온다(Cache Miss)
- write하는 방식
- 애플리케이션이 새로운 데이터 쓰기 혹은 업데이트할 때 캐시와 DB 모두에 같은 작업을 실행하는 방법
- 애플리케이션의 모든 쓰기 작업은 DB에만 적용되고, 기존의 캐시 데이터를 무효화시키는 방법
[write back]
- 서버는 모든 데이터를 캐시에만 저장한다
- 캐시에 특정 시간동안의 데이터가 저장되며 배치처리를 통해 캐시에 있는 데이터를 DB에 저장한다
- DB에 저장되었다면 캐시에는 해당 데이터를 삭제한다
- 단점
- 장애가 생기면 데이터가 날아갈 수 있고 안정성 부분에서 불안하다. 그래서 로그를 Redis에 넣어두고 배치적으로 저장할 때 많이 사용된다.
Redis는 언제 사용되나?
- Remote Data Store
- A 서버, B 서버, C 서버에서 데이터를 공유하고 싶을 때
- 한대에서만 필요한다면, 전역 변수를 쓰면 되지 않는가?
- Redis 자체가 Atomic을 보장해주기 때문. (싱글 스레드라.. Thread Safe하다)
- 물론 특정 상황에서 완벽하진 않다고 한다.
- 주로 많이 사용되는 곳
- 인증 토큰 등을 저장 (Strings 또는 hash)
- Ranking 보드로 사용 (Sorted Set)
- 유저 API Limit
- 잡 큐 (list)
만약 랭킹 서버를 직접 구현한다면?
- 가장 간단한 방법
- DB에 유저의 Score를 저장하고 Score로 Order by하고 정렬 후 읽어오기
- 하지만 이 방식은 데이터가 많아지면 속도에 문제가 발생하게 된다. 결국은 디스크를 사용하기 때문이다. (그래서 In-Memory 방식이 필요하다.)
In-Memory로 구현한다면?
Redis의Sorted Set을 이용하면, 랭킹을 구현 할 수 있다.- 다만 가져다 쓰면 거기의 한계에 종속적이게 된다. 즉 커스텀이 조금 필요하다.
- 랭킹에 저장해야할 id가 1개당 100byte라고 한다면 -> 10,000,000,000 (100억)이면 1TB까지 된다.
Redis 사용 시 주의점
- 서버에 장애가 발생했을 경우를 대비해 플랜이 꼭 필요하다
- 인메모리 데이터 저장소 특징상 서버에 장애가 발생했을 경우 데이터 유실이 발생할 수 있기 때문
- 메모리 관리가 중요하다
- 싱글 스레드의 특성상 한 번에 하나의 명령만 처리할 수 있다. 즉 처리하는데 시간이 오래 걸리는 요청이나 명령은 피해야 한다.

말못하는감자에서말하는감자가되기까지