
오늘 하루 요약

이걸 어떻게 생각해 내?
새로 배우게 된 것
- LCS(최장 공통 부분 수열 구성방식)
- C언어에서의 LinkedList
LCS
어제는 점화식, 오늘은 LCS 구성방식을 정복...(?)

결국 두 문자열의 마지막 문자열을 비교해볼때
똑같다면 그 문자는 100퍼 LCS이다.
그러기에 그 문자열을 제외한 문자열에서 또 LCS를 찾는 것이고
만약 다르다면 둘다 마지막 문자열을 버려보고, 더 긴 LCS를 도출하는 것을 찾는 것.
이 원리를 이용해서 DP 테이블의 [M][N]에서 역으로 올라가면서 문자열을 구성하게 된다.
- 두 문자가 같을 경우
대각선↖️ 이동, 이 문자는 LCS기 때문에 리스트 만들어서 어디 저장해놓으면 된다. - 두 문자가 다를 경우
이렇게 되면 두가지 케이스가 나오는데 위로 가느냐🔼, 왼쪽으로 가느냐⬅️ 이다.
이걸 결정하는 기준은 DP 테이블에 저장된 값을 확인해서 더 큰 쪽으로 가면 된다.
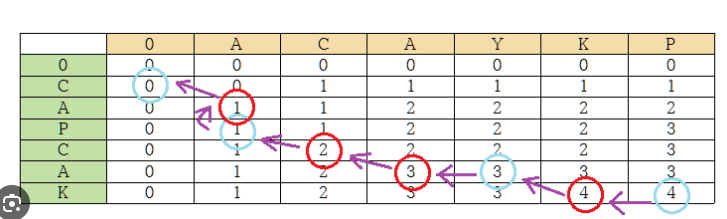
그래서 위 과정을 따라 올라가면서 문자열을 append를 하고 이를 역순 출력하면 바로 LCS!
LinkedList in C
- 배열이 있음에도 왜 이걸 쓰는가?
- 배열은 삭제시 흔적이 남는다
배열은 특정 Idx의 데이터를 지우려면 0을 할당하는 등의 행위로 지우게 되는데, 연속적인 바이트에 저장되기 때문에 그 흔적이 남는다.(칸 자체 삭제가 불가)
반면 연결리스트는 포인터를 옮겨버리면 되기에 칸 자체를 없앨 수 있다.
- 원형 트리형 양방향 등등으로 구현 가능
- 노드 초기화
struct node
{
int data;
struct node *next; // 다른 노드의 주소를 저장할 포인터
};
typedef struct node Node; // 구현의 편의를 위한 이름 재정의- 정적 구현 연결리스트
데이터를 하나씩 노가다로 넣은걸 말한다
#include <stdio.h>
struct node
{
int data;
struct node *next; // 다른 노드의 주소를 저장할 포인터
};
typedef struct node Node*
int main()
{
Node a, b, c, d;
a.data = 1;
a.next = &b;
b.data = 2;
b.next = &c;
c.data = 3;
c.next = &d;
d.data = 4;
d.next = NULL;
return 0;
}- 동적 구현 하기
이때 부터 malloc이 등장한다.
malloc은 프로그램 실행중에 메모리를 할당하는 것을 말한다.
#include <stdio.h>
#include <stdlib.h> // malloc, free 함수가 선언된 헤더 파일
struct NODE { // 연결 리스트의 노드 구조체
struct NODE *next; // 다음 노드의 주소를 저장할 포인터
int data; // 데이터를 저장할 멤버
};
int main()
{
struct NODE *head = malloc(sizeof(struct NODE)); // 머리 노드 생성
// 머리 노드는 데이터를 저장하지 않음
struct NODE *node1 = malloc(sizeof(struct NODE)); // 첫 번째 노드 생성
head->next = node1; // 머리 노드 다음은 첫 번째 노드
node1->data = 10; // 첫 번째 노드에 10 저장
struct NODE *node2 = malloc(sizeof(struct NODE)); // 두 번째 노드 생성
node1->next = node2; // 첫 번째 노드 다음은 두 번째 노드
node2->data = 20; // 두 번째 노드에 20 저장
node2->next = NULL; // 두 번째 노드 다음은 노드가 없음(NULL)
struct NODE *curr = head->next; // 연결 리스트 순회용 포인터에 첫 번째 노드의 주소 저장
while (curr != NULL) // 포인터가 NULL이 아닐 때 계속 반복
{
printf("%d\n", curr->data); // 현재 노드의 데이터 출력
curr = curr->next; // 포인터에 다음 노드의 주소 저장
}
free(node2); // 노드 메모리 해제
free(node1); // 노드 메모리 해제
free(head); // 머리 노드 메모리 해제
return 0;
}근데 문득, 왜 노드마다 malloc을 써야 할까? 라는 근본적인 궁금증이 들더라.
찾아보니까, 아마 리스트의 크기가 계속 바뀌기 때문이 아닐까 싶다.
연결 리스트의 가장 큰 장점이 바로 노드를 자유롭게 추가하거나 삭제할 수 있다는 것.
그래서 노드를 새로 만들 때마다 malloc으로 메모리 아무 데나 공간을 만들고,
이걸 이전 노드의 포인터가 가리키게 하면 그게 바로 연결 리스트에서 말하는 “노드 삽입”
단! malloc을 썼으면 free로 직접 해제해주자.
공부하다가 아쉬운 점
DP는 중복계산을 떼네어내는 재귀라고 들었는데 어디서 중복계산을 하고, 뭘 저장해둘지를 고민해도 안보인다.

제 Velog에 오신 모든 분들이 작더라도 인사이트를 얻어가셨으면 좋겠습니다 :)