오늘 하루 요약

제 멘탈 정상영업 합니다...?
✏️ 오늘의 한 일
- Explicit Free List(with LIFO)
- JS- 2751, 수 정렬하기2
🌈오늘의 성장!
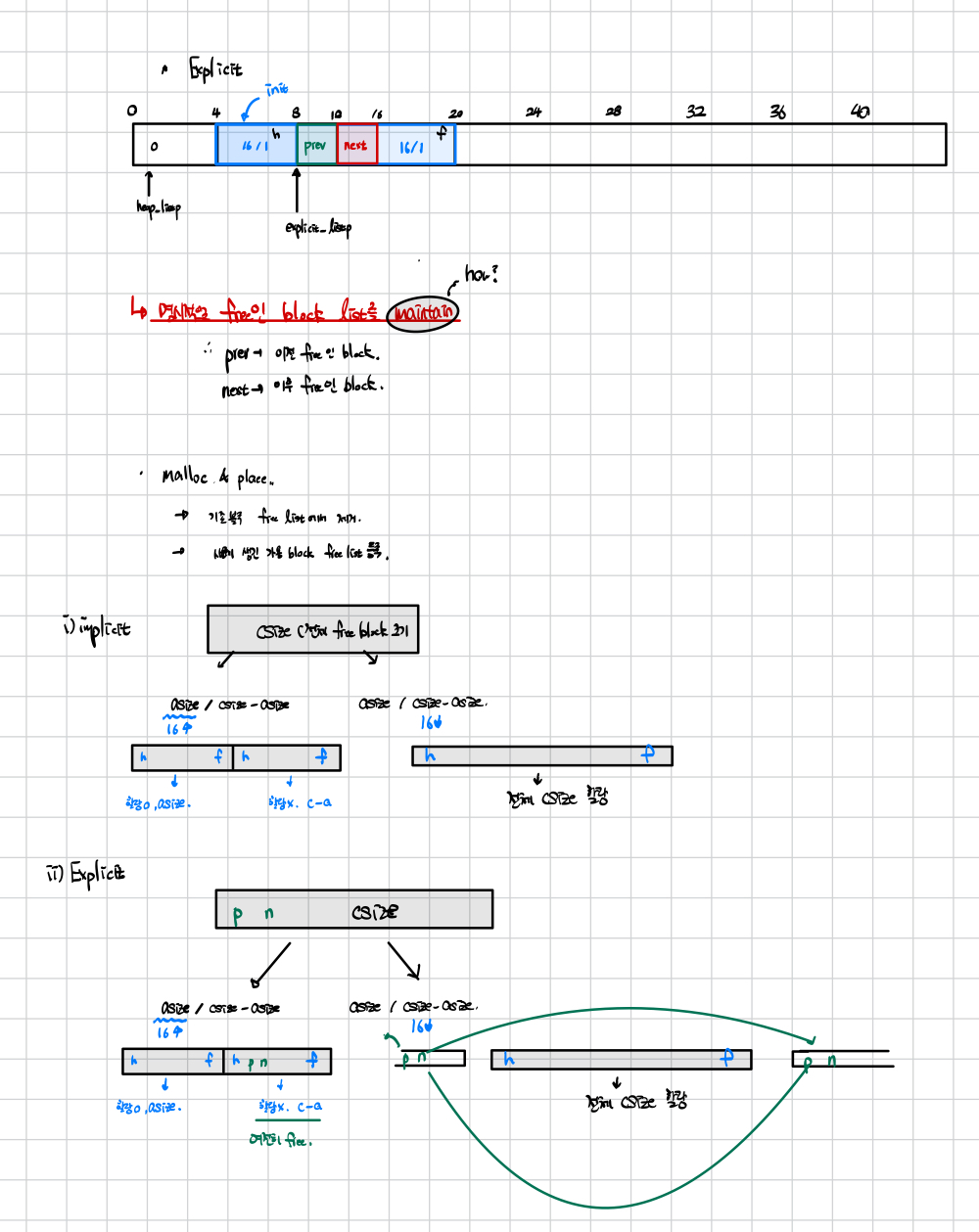
Explicit Free List(with LIFO)
1. 32비트 vs 64비트 시스템의 차이
| 구분 | 32비트 시스템 | 64비트 시스템 |
|---|---|---|
| 주소 공간 | 4GB (2³²) | 18EB (2⁶⁴, 이론적) |
| 포인터 크기 | 4바이트 (32비트) | 8바이트 (64비트) |
| 정수 크기 | int: 4바이트 | long: 8바이트 (보통) |
| 메모리 접근 | 4바이트 단위 접근 | 8바이트 단위 접근 |
- 포인터 크기는 시스템의 주소 공간 크기에 따라 결정됩니다.
- 64비트 시스템에서는 메모리 주소도 8바이트로 표현됩니다.
2. Explicit Free List에서 포인터의 역할
📝 명시적 가용 리스트 (Explicit Free List)
- 가용 블록끼리만 연결한 이중 연결 리스트.
- 각 블록의 페이로드에 이전 블록(PRED), 다음 블록(SUCC) 주소 저장.
💡 페이로드 내 포인터 저장 구조 (64비트 기준)
+--------------------+ ← HDRP(bp) (bp - 4)
| Header (4B) |
+--------------------+ ← bp (Payload 시작)
| PRED 포인터 (8B) | ← *(void **)(bp)
+--------------------+
| SUCC 포인터 (8B) | ← *(void **)((char *)(bp) + 8)
+--------------------+
| (Padding) |
+--------------------+ ← FTRP(bp) (푸터)
| Footer (4B) |
+--------------------+- PRED: 현재 블록의 이전 가용 블록 주소.
- SUCC: 현재 블록의 다음 가용 블록 주소.
3. 왜 64비트 환경에서는 bp + 8을 더해야 할까?
🧩 문제 상황
기존 32비트 환경에서 작성된 코드:
#define GET_SUCC_FREEP(bp) (*(void **)((char *)(bp) + 4)) // ❌ 32비트 전용- 32비트 포인터는 4바이트 → SUCC 포인터는
bp + 4위치.
🚨 64비트 환경에서 발생할 수 있는 문제:
- 포인터 크기는 8바이트.
bp + 4는 PRED 포인터의 뒷부분과 SUCC 포인터의 앞부분을 잘못 읽음.- 결과: 잘못된 메모리 접근 → Segmentation Fault.
✅ 64비트 환경에서 올바른 방식:
#define GET_SUCC_FREEP(bp) (*(void **)((char *)(bp) + 8)) // ✅ 64비트 기준- PRED 포인터는 bp ~ bp+7까지 8바이트 차지.
- SUCC 포인터는 그 다음인 bp + 8부터 저장됨.
4. 메모리 정렬 (Alignment)의 중요성
- 64비트 환경에서는 8바이트 정렬이 필요.
- 메모리 접근 효율과 CPU 성능에 직접적인 영향.
- 구조체나 블록에서 포인터는 반드시 8바이트 단위로 정렬되어야 안전하게 접근 가능.
5. 매크로 정리 (64비트 환경 기준)
#define DSIZE 8 // 포인터 크기 (8바이트)
#define GET_PRED_FREEP(bp) (*(void **)(bp)) // PRED 포인터
#define GET_SUCC_FREEP(bp) (*(void **)((char *)(bp) + DSIZE)) // SUCC 포인터
#define SET_PRED_FREEP(bp, ptr) (*(void **)(bp) = (ptr)) // PRED 설정
#define SET_SUCC_FREEP(bp, ptr) (*(void **)((char *)(bp) + DSIZE) = (ptr)) // SUCC 설정- 항상 DSIZE(8) 기준으로 계산해야 함.
- 실수로
+4와 같은 32비트 기준 코드를 사용하면 치명적인 오류 발생.
JS-2751, 수 정렬하기2
-
console.log는 겁나 느리다
// 시간초과 안나는 코드
num_list = num_list.sort((a, b) => a - b)
console.log(num_list.join('\n'))
// 시간초과 나는 코드
num_list.sort((arr, cur) => arr - cur);
num_list.forEach((elem) => console.log(elem));병합정렬 활용한 코드 : O(N log N), 2076ms
const fs = require("fs");
const input = fs.readFileSync('input.txt').toString().split('\n');
let N = parseInt(input[0]);
let num_list = [];
for (let i = 1; i <= N; i++) {
num_list.push(parseInt(input[i]));
}
function merge_sort(arr) {
if (arr.length < 2) {
return arr;
}
const mid = Math.floor(arr.length / 2);
const low_arr = merge_sort(arr.slice(0, mid));
const high_arr = merge_sort(arr.slice(mid));
let merged_arr = [];
let l = 0, h = 0;
while (l < low_arr.length && h < high_arr.length) {
if (low_arr[l] < high_arr[h]) {
merged_arr.push(low_arr[l]);
l += 1;
} else {
merged_arr.push(high_arr[h]);
h += 1;
}
}
// 남은 요소들 추가
merged_arr = merged_arr.concat(low_arr.slice(l));
merged_arr = merged_arr.concat(high_arr.slice(h));
return merged_arr;
}
const sorted_list = merge_sort(num_list);
console.log(sorted_list.join('\n'));sort 활용한 코드, 1236ms
const fs = require('fs');
const input = fs.readFileSync('input.txt').toString().trim().split('\n')
let N = parseInt(input[0]);
let num_list = [];
for (let i = 1; i <= N; i++) {
num_list.push(parseInt(input[i]));
}
num_list = num_list.sort((a, b) => a - b)
console.log(num_list.join('\n'))sort가 왜 더 빠를까?
항목 | 직접 구현 병합 정렬 | JS 내장 sort (Array.sort)
시간 복잡도 | O(N log N) | 평균 O(N log N)
내부 최적화 | 없음 (순수 JS) | 있음 (네이티브 최적화)
메모리 사용량 | 높음 (배열 복사 많음) | 최적화됨 (캐시 친화적)
알고리즘 다양성 | 병합 정렬 고정 | 상황 따라 다양한 알고리즘
작은 배열 성능 | 낮음 | 매우 높음
파이썬과 마찬가지로 V8 엔진에선 Timsort를 활용...
⛏ 오늘의 삽질
Segmentation 하루종일 봤던 오늘 하루가 그냥 삽질...

제 Velog에 오신 모든 분들이 작더라도 인사이트를 얻어가셨으면 좋겠습니다 :)