
하루 한줄 요약
더 많은 시간을 투자하는데 왜 푸는 문제 수는 적을까 ㅠ
오늘 공부한 내용
- 큐 & 우선순위 큐 & 해시
- 자료구조 vs 추상 자료형
- 백준(이진탐색 문제 - 2805)
새로 배우게 된 내용
큐
- FIFO, 먼저 들어간 것이 먼저 나온다
- Rear로 데이터가 들어가고 Front로 나온다 - Rear로 데이터를 집어넣는 것은 Enqueue, Front로 데이터를 꺼내는 것은 Dequeue
- 이때 Front에서 데이터를 제거하지 않고 확인만 하고 싶다면 Peek
덱(Deque)
- 큐와 다르게 양방향에서 삽입 삭제가 가능하다
파이썬에서의 큐 구현
- deque 모듈을 활용하여 구현할 수 있다.
queue = deque()
queue.append('b')
# queue = ['b']
queue.append('c')
# queue = ['b', 'c']
queue.appendleft('a')
# queue = ['a', 'b', 'c']
#########################
queue = deque()
queue.append('b')
# queue = ['b']
queue.append('c')
# queue = ['b', 'c']
popped_left = queue.popleft()
# popped_left = 'b'우선순위 큐
- 이름만 큐고 동작방식은 딴판
- 들어온 순서가 아닌, 우선순위가 더 높은 데이터가 먼저 나가는 구조
- Heap 자료구조로 구현하는 것이 효율성이 더 좋다
파이썬에서의 우선순위 큐 구현
import heapq
class PriorityQueue:
def __init__(self):
self.queue = []
def push(self, item):
heapq.heappush(self.queue, item)
def pop(self):
if not self.is_empty():
return heapq.heappop(self.queue)
else:
raise IndexError("pop from an empty priority queue")
def peek(self):
if not self.is_empty():
return self.queue[0]
else:
raise IndexError("peek from an empty priority queue")
def is_empty(self):
return len(self.queue) == 0
def size(self):
return len(self.queue)
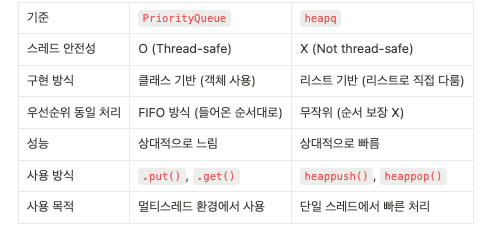
- PriorityQueue vs Heapq
해시
- 각각의 데이터를 고유한 숫자값으로 표현하는 것
- 입력을 고유한 해시값으로 변경, 이때 입력을 Key, 해시값을 만들어주는 함수를 Hash Value라고 함
- 해시를 쓰는 이유는 데이터의 저장과 삭제가 O(1)시간 안에 가능하기 때문
- 단, 최악의 경우(모든 경우에 해시 충돌 발생 시) O(N)의 시간 복잡도를 보일 순 있다.
해시 충돌
- 앞에서 해시 함수를 통해 받은 Hash Value가 Hash Table의 인덱스가 된다고 했다.
이렇게 되면 당연히 동일한 인덱스에 값이 여러개 들어갈 수 있다. 이게 바로 해시 충돌

- 해결법
- 체인법 -> 해시값이 같은 원소를 연결 리스트로 구현
- 오픈 주소 법 -> 빈 버킷을 찾을 때까지 해싱을 반복
파이썬에서의 해시 구현
- Dictionary 자료구조를 사용, Key와 Value 한쌍으로 구성하여 순서와 상관 없이 Key를 통해 Value에 접근한다.
# 해시 테이블을 위한 데이터 저장공간 생성
data = list([0 for i in range(8)]) #[0, 0, 0, 0, 0, 0, 0, 0]
# 내장 함수 hash()로 해시 키 만들기
hash('Dave') #-7514196283267883902
hash('Dave') % 8 #2
# 해시 함수 만들기
# 임의로 8개의 해싱함수 만들어보기
def hash_function(string):
return hash(string) % 8
# 해시함수를 사용하여 데이터 저장
data[hash_function('Dave')] = '000-1111-2222'
data[hash_function('David')] = '000-2222-3333'
# 해시함수 사용하여 데이터 읽어 오기
data[hash_function('Dave')] # '000-1111-2222'자료구조 vs 추상 자료형
- 자료구조
- 실제로 데이터를 저장 및 조작하는 방법을 다루는 법 => 메모리 내에서의 데이터의 배치와 관련- 추상 자료형을 구현하기 위한 구체적인 자료 구조
- 배열, 연결리스트, 트리, 그래프
- 추상 자료형
- 데이터의 추상적인 모델을 나타내는 개념 => 데이터에 대한 연산 정의, 어떤 연산을 수행하는 가- 스택, 큐, 리스트, 집합
백준(이진탐색 문제 - 2805)
- 재귀로 풀었는데, 가장 중요한 종료 조건 설정에서 확실하지 못해서 틀렸다.
- 절반씩 범위를 줄여도 2개의 수가 남을때의 설정을 하지 않아서 계속 틀렸었다.
# N : 나무 개수 (N <= 1,000,000)
# M : 집으로 가져가야하는 나무의 길이
# H : 톱날의 높이 (H <= 2,000,000,000)
# 구해야 할 것 : M미터의 나무를 집에 가져가기 위한 H의 최댓값
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
tree_list = list(map(int, input().split()))
# tree_list.sort()
start = 0 # 4
end = max(tree_list)
# 첫 임시 톱날 높이(temp_h) => (start + end) // 2
# temp_h로 잘랐을때 나오는 나무 길이인 temp_M.
# temp_M > M 일경우, 톱날의 높이는 더 높아야함, 따라서 temp_H ~ end까지
# temp_M < M 일경우 톱날의 높이는 더 낮아야함, 따라서 low ~ temp_H까지
def binary_search(data, start, end):
temp_h = (start + end) // 2 # 4 + 46 // 2 => 25
temp_M = 0
if start > end: # 나중에 34 35일 경우 종료조건으로 진행
return end
for tree in data:
if temp_h > tree:
continue
else:
temp_M += tree - temp_h
if temp_M == M:
return temp_h
elif temp_M > M:
return binary_search(data, temp_h + 1, end)
else:
return binary_search(data, start, temp_h -1)
print(binary_search(tree_list, start, end))공부하다가 아쉬운 점
- 스택을 활용한 수식의 후위 표기를 설명을 제대로 하지 못했다. 2회독 갈기자
- 이분탐색에서의 종료조건이라던지 디테일적인 부분에서 많이 부족하다. 깊이감을 더하자.

제 Velog에 오신 모든 분들이 작더라도 인사이트를 얻어가셨으면 좋겠습니다 :)