윈도우 함수
1. 행과 행간의 관계에서 다양한 연산 처리를 할 수 있는 함수
2. 분석함수로도 알려져 있다. (ANSI 표준은 윈도우 함수이다.)
3. 윈도우 함수는 일반 함수와 달리 중첩하여 호출 될 수 없다.
윈도우 함수의 종류
| 종류 | 설명 |
|---|---|
| 순위관련함수 | - RANK, DENSE_RANK, ROW_NUMBER |
| 집계관련함수 | - SUM, MAX, MIN, AVG, COUNT |
| 행순서관련함수 | - FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 그룹내 비율관련함수 | - CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT |
윈도우 함수 문법
SELECT
윈도우함수(인자) OVER (PARTITION BY 컬럼 ORDER BY 컬럼)
윈도우절
FROM 테이블명
;| 항목 | 설명 |
|---|---|
| 윈도우함수 | - 다양한 윈도우 함수를 사용 가능 |
| 인자 | - 함수에 따라 O-N개의 인자를 사용 |
| PARTITION BY | - 전체 집합을 기준에 의해 소그룹으로 나눌 수 있다. |
| ORDER BY | - 어떤 항목에 대해 순위를 지정할지 ORDER BY 절을 기술할 수 있다. |
| 윈도우절 | - 함수의 대상이 되는 행 기준의 범위를 지정 - ROWS는 물리적인 결과 행의 수를 뜻한다. - RANGE는 논리적인 값에 의한 범위를 뜻한다. |
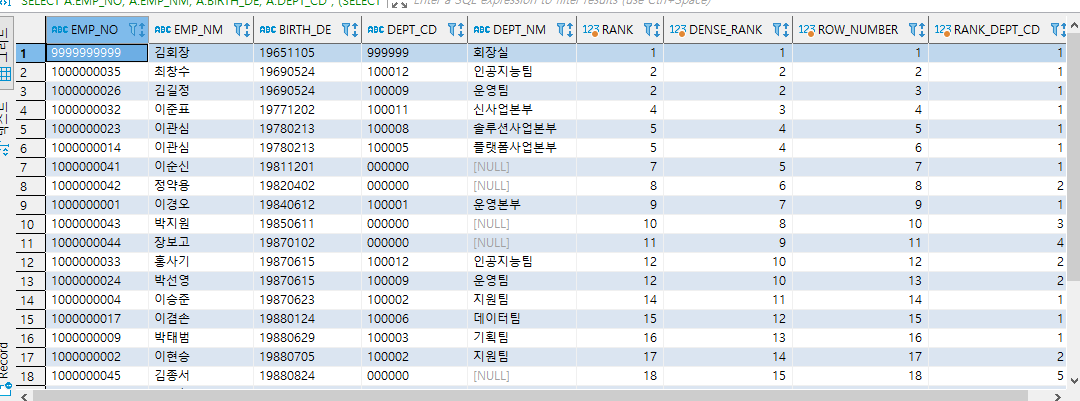
윈도우 함수 실습 - 그룹내 순위 함수
- 전 직원중 성별이 남성인 직원들의 생년월일을 조회하고 생년월일 순으로 RANK를 구함.
- RANK 함수는 동일값이라면 동일 순위라고 판단하여 순위를 정함 1 2 2 4 (BIRTH_DE 기준으로 순위를 매김)
- DENSE_RANK 함수는 동일값이라면 동일 순위라고 판단하여 1 2 2 3 순으로 순위를 정함 (BIRTH_DE 기준으로 순위를 매김)
- ROW_NUMBER 함수는 동일값이라도 무조건 순위를 정함 1 2 3 4 (BIRTH_DE 기준으로 순위를 매김)
- DEPT_CD 기준으로 PARTITION BY하여 부서별 생일 순위도 같이 구하였음. (RANK_DEPT_CD는 ROW 정보가 자신의 부서에서 생일이 빠른 순서를 보여준다.)
SELECT A.EMP_NO, A.EMP_NM, A.BIRTH_DE, A.DEPT_CD
, (SELECT L.DEPT_NM FROM TB_DEPT L WHERE L.DEPT_CD = A.DEPT_CD) AS DEPT_NM
, RANK() OVER(ORDER BY A.BIRTH_DE) AS RANK
, DENSE_RANK() OVER(ORDER BY A.BIRTH_DE) AS DENSE_RANK
, ROW_NUMBER() OVER(ORDER BY A.BIRTH_DE) AS ROW_NUMBER
, RANK() OVER(PARTITION BY A.DEPT_CD ORDER BY A.BIRTH_DE) AS RANK_DEPT_CD
FROM TB_EMP A
WHERE A.SEX_CD = '1' --남성
ORDER BY A.BIRTH_DE ; 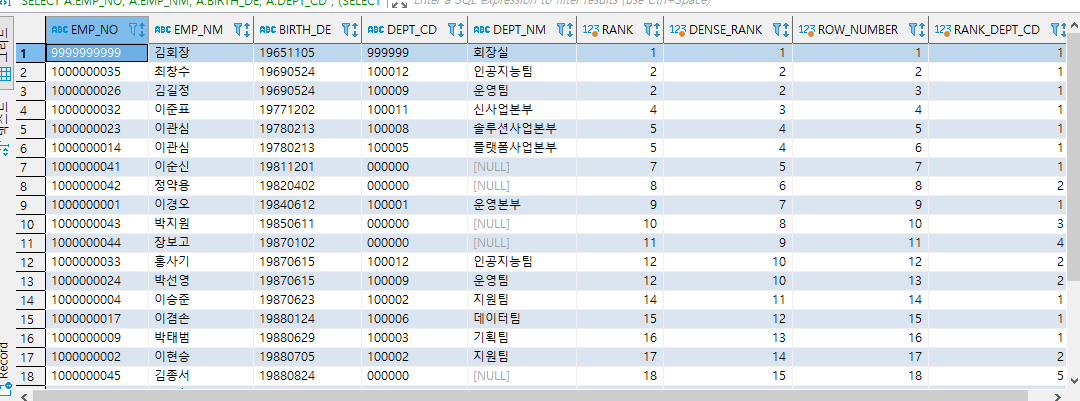
윈도우 함수 실습 - 집계 관련 함수
- 2019년 기준 전직원의 연봉액수를 조회하는 SQL문
- SUM, MAX, MIN, AVG, COUNT
- SUM : 속한 부서의 연봉 총액 및 연봉 누적 합계 (RANGE UNBOUNDED PRECEDING은 현재행을 기준으로 파티션내 첫번째 행까지의 범위를 지정한다.)
- MAX : 자신이 속한 부서의 최고 연봉액
- MIN : 자신이 속한 부서의 최저 연봉액
- AVG : 자신이 속한 부서의 평균 연봉액
- COUNT : 부서별 직원의 수
SELECT A.EMP_NO
, A.MAX_EMP_NM
, A.연봉
, A.MAX_DEPT_CD
, (SELECT DEPT_NM FROM TB_DEPT L WHERE L.DEPT_CD = A.MAX_DEPT_CD) AS DEPT_NM
, SUM(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD) AS "속한부서의연봉총액"
, SUM(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD ORDER BY A.연봉
RANGE UNBOUNDED PRECEDING) AS "속한부서의연봉누적합계"
, MAX(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD) AS "속한부서의최고연봉액"
, MIN(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD) AS "속한부서의최저연봉액"
, TRUNC(AVG(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD)) AS "속한부서의평균연봉액"
, TRUNC(AVG(A.연봉) OVER(PARTITION BY A.MAX_DEPT_CD ORDER BY A.연봉
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
)
) AS "속한부서에서앞뒤자신의평균연봉액"
, COUNT(*) OVER (PARTITION BY A.MAX_DEPT_CD) AS "부서별직원수"
FROM
(
SELECT B.EMP_NO
, MAX(A.EMP_NM) AS MAX_EMP_NM
, MAX(A.DEPT_CD) AS MAX_DEPT_CD
, SUM(B.PAY_AMT) AS "연봉"
FROM TB_SAL_HIS B , TB_EMP A
WHERE B.PAY_DE BETWEEN '20190101' AND '20191231'
AND A.EMP_NO = B.EMP_NO
GROUP BY B.EMP_NO
ORDER BY B.EMP_NO
) A
ORDER BY A.MAX_DEPT_CD, A.연봉;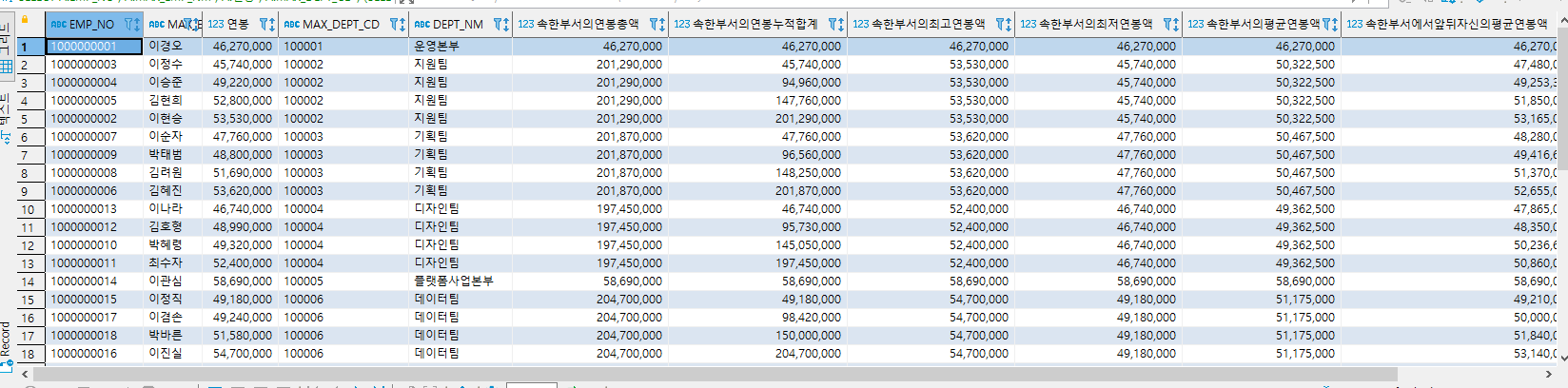
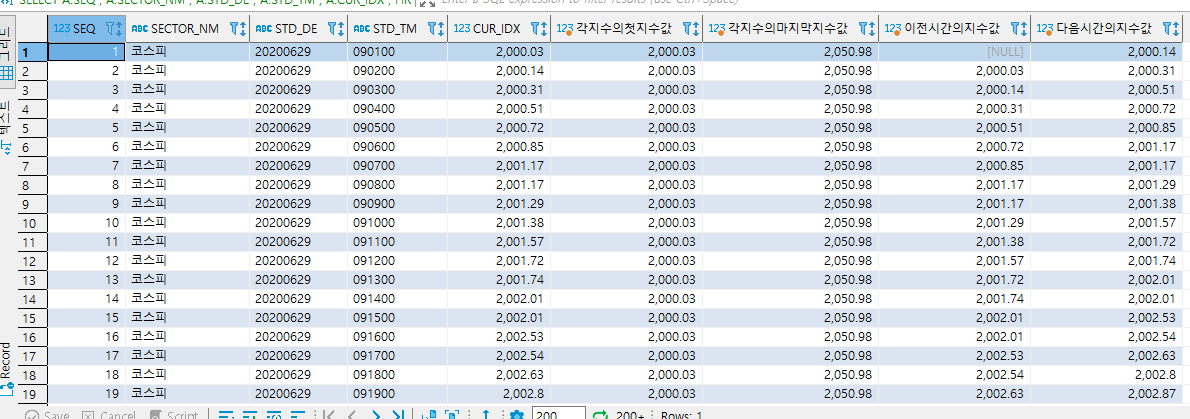
윈도우 함수 실습 - 행순서 관련 함수
- FIRST_VALUE, LAST_VALUE, LAG, LEAD
- FIRST_VALUE : 각 지수의 첫 번째 지수값.
- LAST_VALUE : 각 지수의 마지막 지수값.
- LAG : 각 지수의 이전 시간의 지수값. (LAGGED VARIABLE 개념)
- LEAD : 각 지수의 다음 시간의 지수값.
SELECT * FROM TB_REAL_IDX ORDER BY SEQ;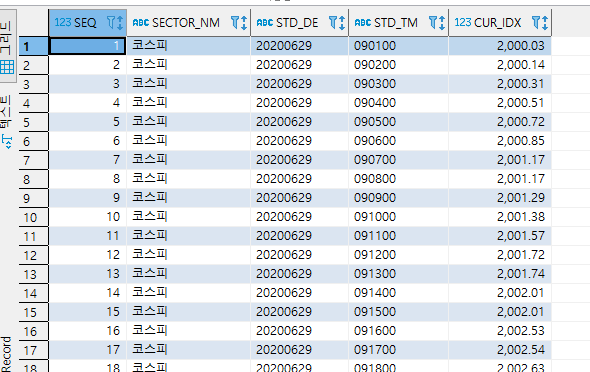
SELECT A.SEQ
, A.SECTOR_NM
, A.STD_DE
, A.STD_TM
, A.CUR_IDX
, FIRST_VALUE(CUR_IDX) OVER(PARTITION BY A.SECTOR_NM ORDER BY A.STD_TM
ROWS UNBOUNDED PRECEDING) AS "각지수의첫지수값"
, LAST_VALUE(CUR_IDX) OVER(PARTITION BY A.SECTOR_NM ORDER BY A.STD_TM
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS "각지수의마지막지수값"
, LAG(CUR_IDX, 1) OVER (PARTITION BY A.SECTOR_NM ORDER BY A.STD_TM) AS "이전시간의지수값"
, LEAD(CUR_IDX, 1) OVER (PARTITION BY A.SECTOR_NM ORDER BY A.STD_TM) AS "다음시간의지수값"
FROM TB_REAL_IDX A
ORDER BY A.SECTOR_NM DESC, A.STD_DE, A.STD_TM
;
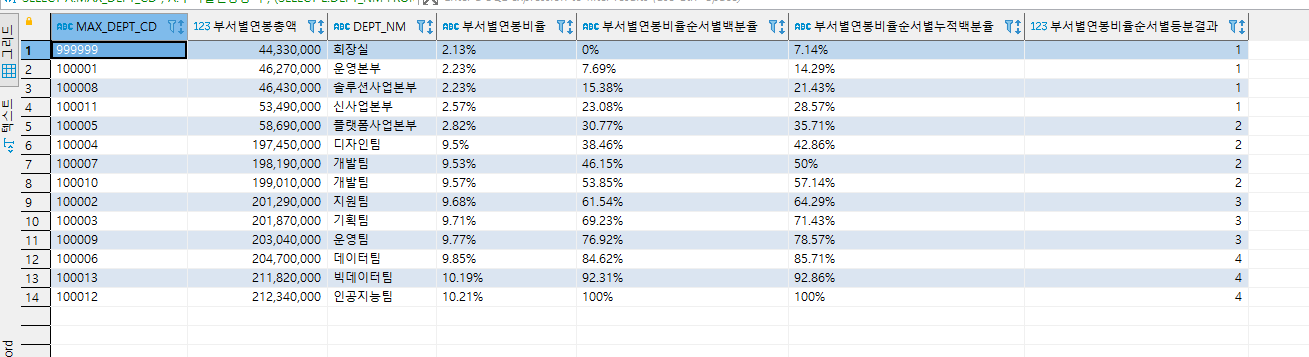
윈도우 함수 실습 - 그룹내 비율 관련 함수
- CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT
- RATIO_TO_REPORT : 전체 연봉에서 부서별 연봉의 비율을 나타낸다.
- PERCENT_RANK : 부서별 연봉 비율 순위를 백분율로 나타낸다.
- CUME_DIST : 부서별 연봉 비율 순위의 누적 백분율을 나타낸다.
- NTILE : 부서별 연봉 비율의 등분 결과를 나타낸다.
SELECT
A.MAX_DEPT_CD
, A.부서별연봉총액
, (SELECT L.DEPT_NM FROM TB_DEPT L WHERE L.DEPT_CD = A.MAX_DEPT_CD) AS DEPT_NM
, ROUND(RATIO_TO_REPORT(A.부서별연봉총액) OVER(), 4) * 100 || '%' AS "부서별연봉비율"
, ROUND(PERCENT_RANK() OVER(ORDER BY A.부서별연봉총액), 4) *100 || '%' AS "부서별연봉비율순서별백분율"
, ROUND(CUME_DIST() OVER(ORDER BY A.부서별연봉총액), 4) *100 || '%' AS "부서별연봉비율순서별누적백분율"
, NTILE(4) OVER(ORDER BY A.부서별연봉총액) AS "부서별연봉비율순서별등분결과"
FROM
(
SELECT
A.MAX_DEPT_CD
, SUM(A.연봉) AS "부서별연봉총액"
FROM
(
SELECT B.EMP_NO
, MAX(A.EMP_NM) AS MAX_EMP_NM
, MAX(A.DEPT_CD) AS MAX_DEPT_CD
, SUM(B.PAY_AMT) AS "연봉"
FROM TB_SAL_HIS B , TB_EMP A
WHERE B.PAY_DE BETWEEN '20190101' AND '20191231'
AND A.EMP_NO = B.EMP_NO
GROUP BY B.EMP_NO
ORDER BY B.EMP_NO
) A
GROUP BY A.MAX_DEPT_CD
ORDER BY A.MAX_DEPT_CD
) A
;

안녕하세요