2nd project 코드를 살펴보니..
위코드에서 참여했던 2차 프로젝트 코드를 다시 한번 살펴봤다. 프로젝트는 국내 인테리어 플랫폼 사이트 '그녀의 집'을 모티프로 웹을 제작하는 것이었고, 내가 맡은 기능은 소셜 로그인이었다. 위코드 과정이 끝난 뒤 공부했던 내용을 정리할 필요성을 느껴서, 첫 번째 순서로 2차 프로젝트를 Refactoring하게 되었다.
내가 구현한 기능뿐만 아니라, 팀원이 작성한 코드들도 살펴봤다. 그런데... 실력이 조금은 향상된 모양이다. 이전에는 눈에 띄지 않았던 문제점이 보이기 시작했다. 2차 프로젝트와 1차 프로젝트 모두에서 마찬가지다.(특히 1차 프로젝트는 정말 심각한 수준이다...) 덕분에, 취업이 될 때까지 할 일 없이 멍하게 시간을 보내는 일이 줄어들 것 같다.
Kakao 소셜 로그인 - '동의 항목'에 대한 예외처리하기
-
Kakao 소셜 로그인 기능을 구현하려면 '동의 항목'에 대한 설정이 필요하다. '동의 항목 설정'이란 kakao 로그인 사용자 정보를 kakao에 요청하기 위해, 사용자로부터 동의를 받아야 하는 항목을 정하는 일이다. 동의 항목의 범위를 어떻게 설정하느냐에 따라, api로부터 받아볼 수 있는 데이터의 종류가 달라지므로, 소셜 로그인을 구현할 때 반드시 설정이 필요한 부분이다. 한 가지 명심해야 할 것은... 결국 동의의 주체는 사용자라는 것이다. 엔지니어가 동의 항목을 여러 개 지정했다고 해도, 결국 사용자가 소셜 로그인 과정에서 동의를 거부하면, kakao api의 그림자도 구경할 수 없다.
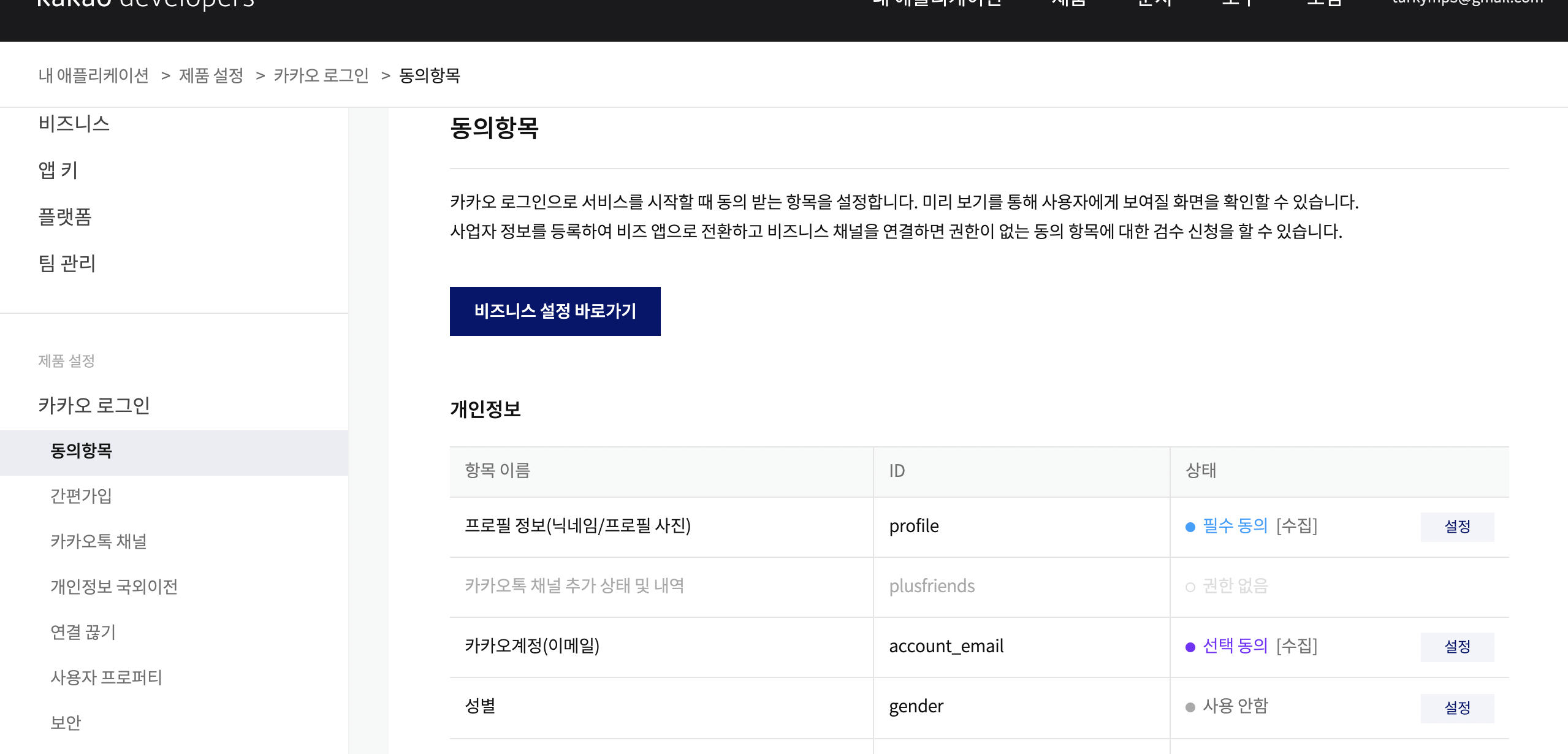
-
위 이미지의 개인정보에서 '상태' column을 살펴보자. 상태의 종류로 '필수 동의', '선택 동의', '사용 안함'이 존재한다. 간단한 의미는 다음과 같다.
- 필수 동의: kako로그인 사용자가 반드시 동의해야 하는 항목. 동의하지 않으면 로그인 자체가 진행되지 않는다. 서버 입장에서 해당 정보(프로필 정보)는 예외 없이 받아볼 수 있다.
- 선택 동의: kako로그인 사용자가 동의해도 되고 하지 않아도 되는 항목. 동의하지 않아도 로그인은 정상 진행된다. 다만 데이터(카카오계정 정보)에 접근할 수 없다.
- 사용 안함: 사용자에게 동의를 구하지 않는 항목. 당연히 관련 데이터도 요청할 수 없다.
-
문제의 발생: 문제는 항목의 '상태'가 '선택 동의'일 때 발생한다. 만약 kakao 로그인 사용자가 항목에 대해 동의하지 않았다고 가정해보자. 이 경우 항목에 관한 데이터를 요청하지 못하게 되고, 이는 코드의 로직에 따라 다르겠지만 error의 원인이 되기도 한다. 데이터를 받아오지 못하는 경우에 대한 예외처리가 필요한 것도 그래서다.
-
예외 처리: 다행히 나의 코드에선 소셜 로그인 사용자가 동의하지 않아도 가시적인 Error가 발생하진 않았다. 대신
email= profile_request.get('kakao_account').get('email')에서 변수 email에null값이 할당되는 문제가 발생했다.(이는 결과적으로 로그인 기능 로직의 문제을 발생시켰다.) 그래서 에외처리 코드를 아래와 같이 추가하였다.
# refactoring 이전 코드
class KakaoSigninView(View):
def post(self, request):
try:
access_token = request.headers['Authorization']
profile_request = requests.get(
"https://kapi.kakao.com/v2/user/me",
headers={"Authorization" : f"Bearer {access_token}"}
).json()
if profile_request.get('code')==-401 or not profile_request:
return JsonResponse({'message' : 'INVALID_TOKEN'}, status = 401)
id_number = profile_request.get('id')
email = profile_request.get('kakao_account').get('email')
if not User.objects.filter(email=email).exists():
return JsonResponse({'message' : 'INVALID_USER', 'id_number' : id_number, 'email' : email }, status=401)
token = jwt.encode({
'user_id':User.objects.filter(email=email).first().id},
my_settings.SECRET_KEY, algorithm="HS256"
)
return JsonResponse({'message' : 'SUCCESS', 'token' : token}, status=200)
except KeyError:
return JsonResponse({"message" : "KEY_ERROR"}, status = 400)# refactoring 이후
class KakaoSigninView(View):
def post(self, request):
try:
access_token = request.headers['Authorization']
profile_request = requests.get(
"https://kapi.kakao.com/v2/user/me",
headers={"Authorization" : f"Bearer {access_token}"}
).json()
if profile_request.get('code')==-401 or not profile_request:
return JsonResponse({'message' : 'INVALID_TOKEN'}, status = 401)
id_number = profile_request.get('id')
email = profile_request.get('kakao_account').get('email')
### 추가된 코드
if not email:
return JsonResponse({'message' : 'NEED_USER_AGREEMENT'}, status=401)
###
if not User.objects.filter(email=email).exists():
return JsonResponse({'message' : 'INVALID_USER', 'id_number' : id_number, 'email' : email }, status=401)
token = jwt.encode({
'user_id':User.objects.filter(email=email).first().id},
my_settings.SECRET_KEY, algorithm="HS256"
)
return JsonResponse({'message' : 'SUCCESS', 'token' : token}, status=200)
except KeyError:
return JsonResponse({"message" : "KEY_ERROR"}, status = 400)상품 리스트 view - annotate() 활용하기
-
annoate(): django에서 사용되는 쿼리 표현식 중 하나로,aggregate()처럼 데이터베이스의 특정 값(Count(),Avg(),Sum()로 계산된 값)을 집계하는데 사용된다.annotate()의 가장 큰 특징은 집계된 값을 필드 값으로 갖는 Column 생성이 가능하다는 점이다. -
코드 예시
-
annotate()가 사용된 예시 코드1product_list = Product.objects.all().annotate(count_images=Count(‘productimage’)).order_by(name)[:30]` -
위 코드는 products 테이블(Model Product의 테이블 이름에 해당)의 전체 Object(전체 row)를 QuerySet으로 불러오는 쿼리문이다.
-
위 코드에선
annotate()를 통해 products 테이블에 count_images라는 Column을 추가했다. 그렇다면 QuerySet을 구성하고 있는 개별 Object의 count_images Column에 대한 필드 값은 무엇일까? 정답은 products 테이블의 개별 Object와 대응하는(역참조된) product_images 테이블의 Object 개수이다.(Count()로 계산하였으므로...) 위 ORM 쿼리문을 SQL 쿼리문으로 표현하면 아래와 같다. Scalar Subquery를 사용한 것이 특징이다.SELECT products.*, (SELECT COUNT(*) FROM product_images AS pro_img WHERE products.id = pro_img.product_id) AS count_images FROM products ORDER BY name asc LIMIT 30; -
annotate()가 사용된 예시 코드2products = Product.objects.filter(q).annotate(star_rating=Avg('review__star_rating')).order_by(ordering) -
위 코드에선
annotate()를 통해 products 테이블에 star_rating라는 Column을 추가했다. 그렇다면 QuerySet을 구성하고 있는 개별 Object의 star_rating Column에 대한 필드 값은 무엇일까? 정답은 products 테이블의 개별 Object와 대응하는(역참조된) reviews 테이블의 Object들(1:N의 관계이므로...)의 Column에 해당하는 star_rating 필드 값의 평균이다.
-
-
annoate()vsaggregate()-
annotate(): 쿼리문으로 가져온 QuerySet의 개별 Object 단위로 연산자(Count(),Avg(),Sum())가 적용된다. 결괏값으로 QuerySet을 반환한다. -
aggregate(): 쿼리문으로 가져온 QuerySet의 모든 Object의 필드 값에 대해 연산자가 적용된다. 모든 Object의 값을 계산하기 때문에 결괏값은 1개이며, Dictionary 형태로 반환된다. -
Count(): 쿼리문으로 가져온 QuerySet의 Object의 모든 개수(데이터의 모든 개수)를 구한다. 굳이aggregate()사용을 고민하지 않아도 된다. 단, 가져온 QuerySet의 Object가 역참조 중인 테이블의 데이터 개수를 구할 때에는aggregate()를 사용해야 한다. -
사용법
-
annotate(): 불러온 QuerySet에 새로운 column과 필드 값을 추가하고 싶을 때 사용한다. -
aggregate(): 불러온 QuerySet을 for문으로 하나씩 꺼내서 개별 객체마다 key:value형태로 값을 지정할 때 사용한다. —>aggregate()의 경우 쿼리문이 for문으로 반복되는 횟수만큼 실행되므로 효율성을 고려하여 사용해야 한다.
-
-
-
annotate()와aggregate()의 차이를 구분하는 것은 어째서 중요할까? 이유는 두 쿼리문의 사용 용도가 다르기 때문이다. 가령annotate()활용이 필요한 곳에aggregate()를 사용하면, 코드 효율성이 엄청나게 떨어지는 불상사가 발생할 수 있다. 내가 Refactoring을 하게 된 이유도 이러한 효율성(쿼리문 실행 시간)을 높이기 위함이었다. -
문제의 코드:
'star_rating': round(product.review_set.all().aggregate(Avg('star_rating'))['star_rating__avg'],1) if product.review_set.all() else None, -
문제의 원인: 위 코드는 쿼리문
aggregate()가 적절히 사용되지 못한 예시다.aggregate()가 list comprehension 내부에서 사용되면, 반복 횟수만큼 쿼리문이 실행되기 때문이다. 만약 QuerySet이 1000개의 Object를 요소로 가지고 있다면,aggregate()쿼리문은 1000번 실행될 것이다. 이는 결괏값을 도출하는 데는 문제가 없다. 다만 쿼리문 실행 횟수가 많아지면서 데이터 처리 시간이 엄청나게 증가할 뿐이다. -
문제의 해결:
annotate()를 사용하면 속도를 단축시킬 수 있다. 이미 전체 쿼리문을 실행할 때,annotate()를 사용하여 새로운 Column을 생성했기 때문에, list comprehension 내부에서 그대로 사용하면 된다.'star_rating': round(product.star_rating,1) if product.star_rating else None, -
100개의 Object에 대한 처리 시간을 측정 해보니,
aggregate()를 사용할 때보다 시간이 1/3로 감소했다.
# refactoring 이전 코드
class ProductListView(View):
def get(self,request):
try:
ordering = request.GET.get('ordering','-price')
category_id = request.GET.get('category-id', None)
q=Q()
if category_id:
q = Q(category_id=category_id)
products = Product.objects.filter(q).annotate(star_rating=Avg('review__star_rating')).order_by(ordering)
product_lists = [
{
'id' : product.id,
'name' : product.name,
'price' : int(product.price),
'manufacturer' : product.manufacturer,
'discount_rate' : product.discount_rate,
'star_rating' : round(product.review_set.all().aggregate(Avg('star_rating'))['star_rating__avg'],1) if product.review_set.all() else None,
'review_number' : product.review_set.count(),
'is_freedelivery' : product.is_freedelivery,
'thumbnail_image' : product.thumbnail_image,
'hot_deal' : random.randrange(0,2),
} for product in products]
if len(product_lists)==0:
return JsonResponse({'MESSAGE':'INVALID_CATEGORY_ID'}, status=401)
return JsonResponse({'MESSAGE':'SUCCESS','product_lists':product_lists}, status=200)
except FieldError:
return JsonResponse({'MESSAGE':'INVALID_ORDERING_METHOD'}, status=401)# refactoring 이후
class ProductListView(View):
def get(self,request):
try:
ordering = request.GET.get('ordering','-price')
category_id = request.GET.get('category-id', None)
q=Q()
if category_id:
q = Q(category_id=category_id)
products = Product.objects.filter(q).annotate(star_rating=Avg('review__star_rating')).order_by(ordering)
product_lists = [
{
'id' : product.id,
'name' : product.name,
'price' : int(product.price),
'manufacturer' : product.manufacturer,
'discount_rate' : product.discount_rate,
### 바뀐 코드
'star_rating' : round(product.star_rating,1) if product.star_rating else None,
###
'review_number' : product.review_set.count(),
'is_freedelivery' : product.is_freedelivery,
'thumbnail_image' : product.thumbnail_image,
'hot_deal' : random.randrange(0,2),
} for product in products]
if len(product_lists)==0:
return JsonResponse({'MESSAGE':'INVALID_CATEGORY_ID'}, status=401)
return JsonResponse({'MESSAGE':'SUCCESS','product_lists':product_lists}, status=200)
except FieldError:
return JsonResponse({'MESSAGE':'INVALID_ORDERING_METHOD'}, status=401)