01. 웹의 기본 아키텍쳐
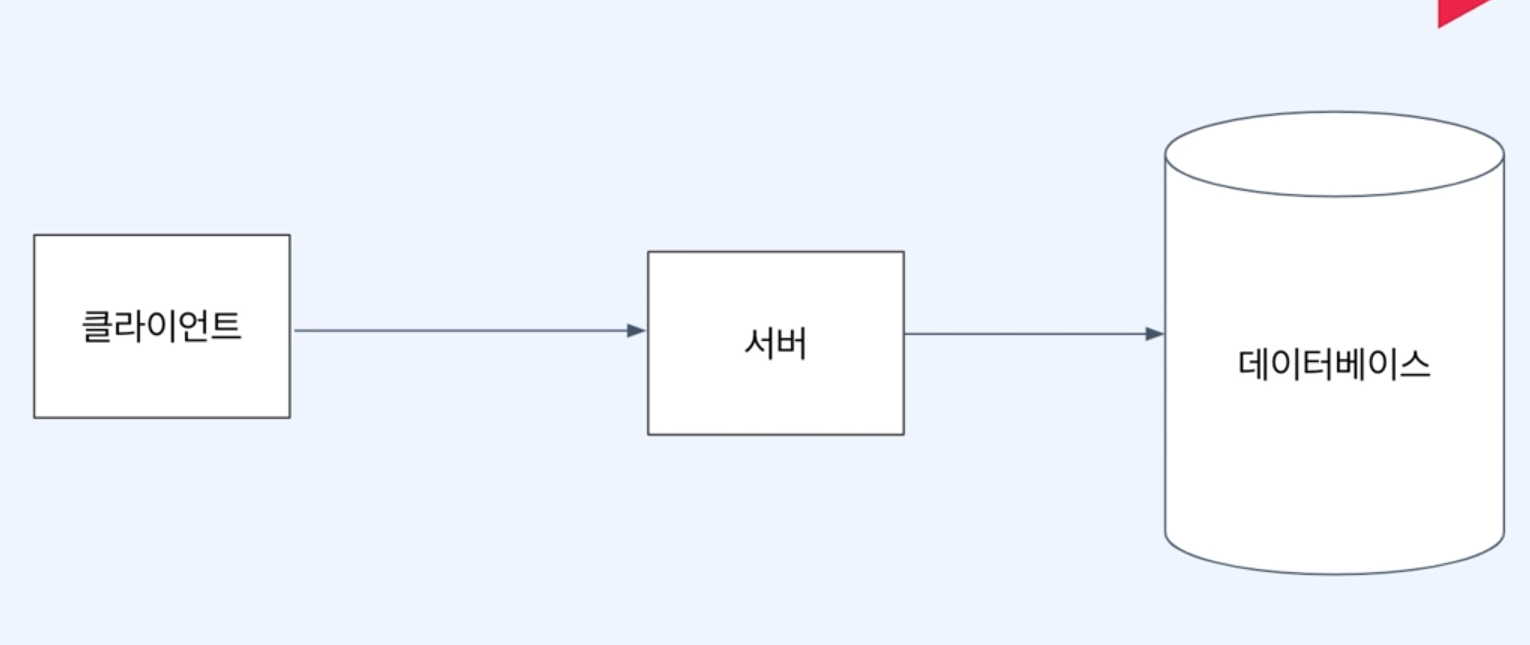
과거 : 클라이언트 - 웹 서버 - 데이터베이스
현재 : 클라이언트 - 웹 서버 - 웹 어플리케이션서버 - 데이터베이스
웹 서버 : 정적인 내용들을 다룬다.
웹 어플리케이션 서버 : 동적으로 변하는 내용들 (데이터)들을 다룬다.
웹 서버, 웹 어플리케이션 서버는 왜 나누어졌을까?
웹의 복잡도가 증가함에 따라...
핵심은
관심사의 분리 / 관측가능한 시스템 / 효율적인 리소스 사용
각 컴포넌트를 역할에 맞춰서 나누는 것으로 문제에 범위가 국한이 되어 문제 해결이 쉽다.
단점도 있다. 레이어가 늘어남에 시스템의 복잡도가 증가하였다.
아까 그림에서 클라이언트들이 늘어난다면 어떻게 될까?
-> 대용량 시스템에서는 이런 것을 구현하기 위해서 많은 노력을 한다.
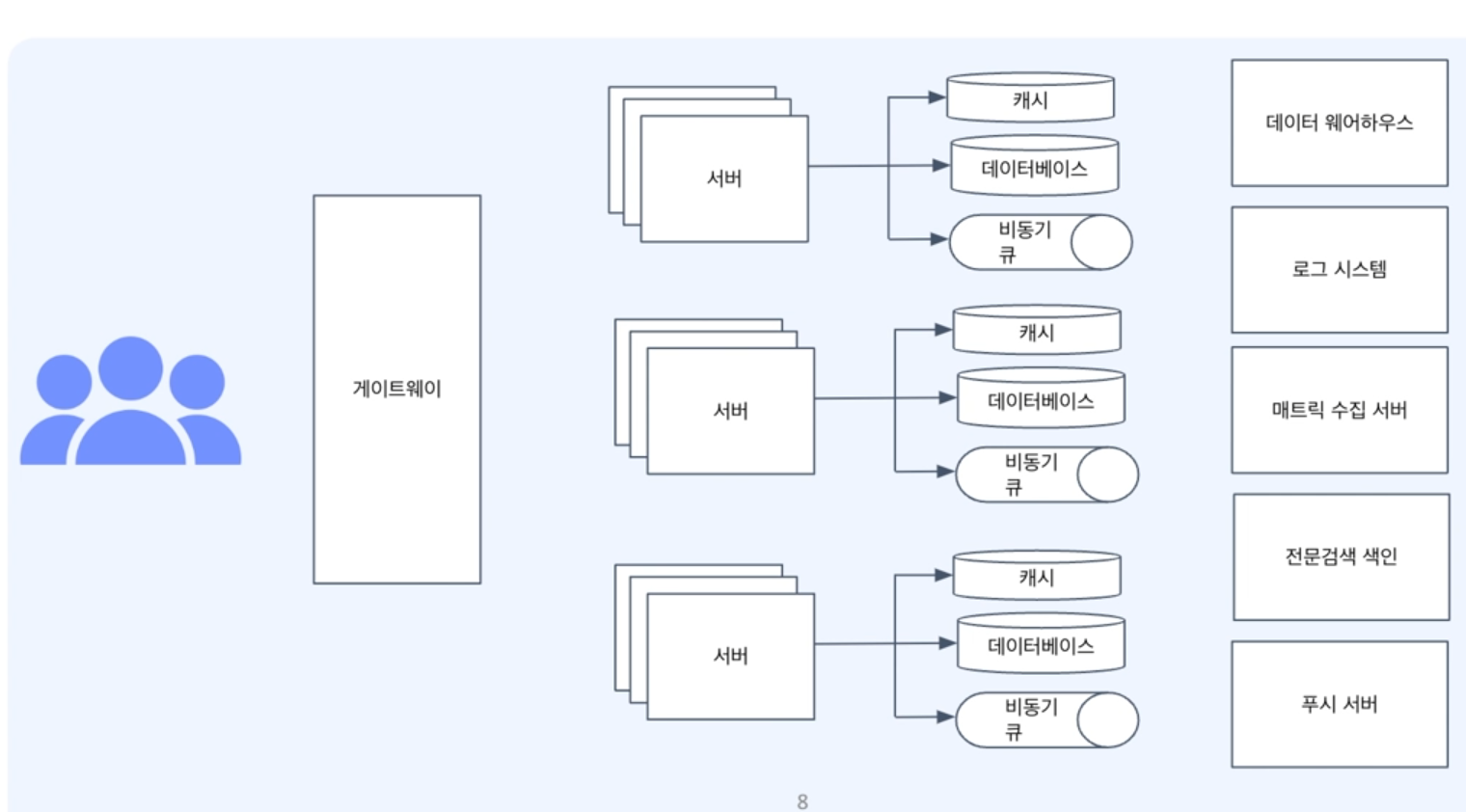
최종적으로 위와 같은 아키텍쳐의 프로젝트를 만드는 것이 목표이다.
02. 왜 데이터베이스가 병목일까?
스케일 업과 스케일 아웃
스케일 업은 사양을 높혀서 부하를 담당하는 것이다.
스케일 아웃은 서버를 늘려서 부하를 담당한다.
수직 확장이냐? 수평 확장이냐?
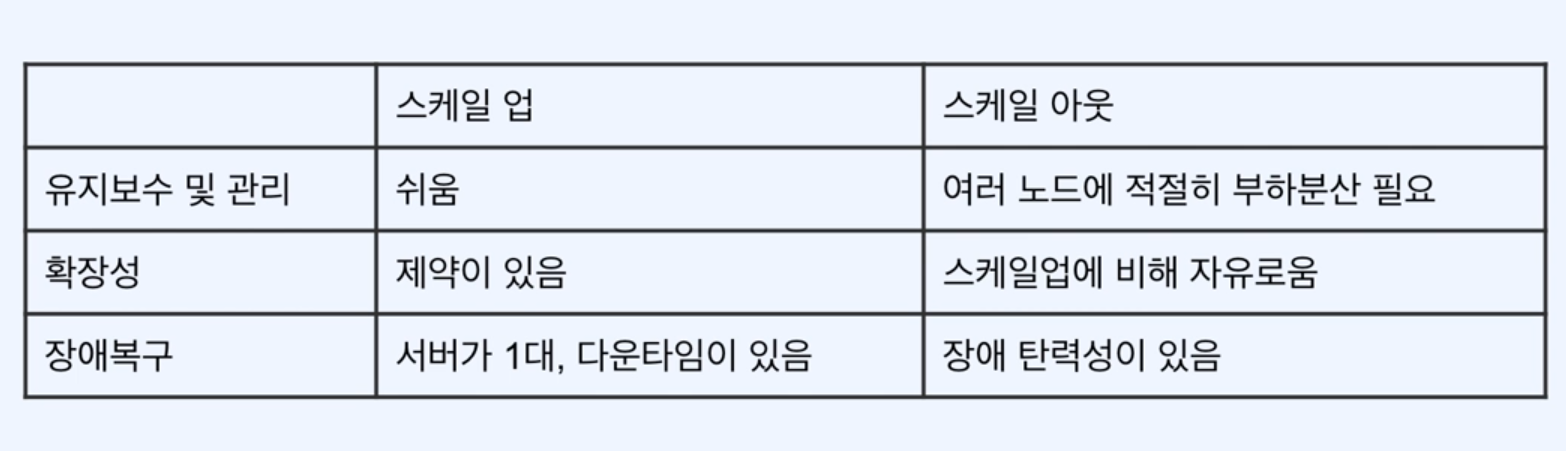
현재는 스케일 아웃이 대세
-> 무중단 배포를 하거나 비용이 싸고 좋다.
하나의 데이터 베이스를 스케일 아웃하는 것은 어떨까?
=> 데이터베이스는 데이터라는 상태를 관리하고 있어 서버보다 스케일 아웃을 하기 위해서는 훨씬 많은 비용이 필요
현대 서버 아키텍쳐는 상태관리를 데이터베이스에 위임하고, 서버는 상태관리를 하지 않는 방향으로 발전
스케일 아웃외에도 데이터베이스는 디스크의 데이터를 접근해서 가져온다.
데이터베이스는 이러한 제약에 따라 병목이 발생한다.
03. 대용량 시스템 아키첵처 맛보기
대용량 트래픽 / 데이터 처리는 왜 어려울까?
하나의 서버 또는 데이터베이스로 감당하기 힘든 부하
-> 다수의 서버와 데이터베이스를 마치 하나인 것 처럼
웹 서비스들은 24시간 무중단
-> 잘못된 코드 한줄이 미치는 영향이 크다.
여러 마이크로 서비스들이 복잡한 의존 관계를 가진다.
-> 시스템 복잡도가 상당히 높다.
대용량 시스템은 어떠해야하는가?
고가용성
언제든 서비스를 이용할 수 있어야한다.
확장성
시스템이 비대해짐에 따라 증가하는 데이터와 트래픽에 대응할 수 있어야 한다.
관측가능성
문제가 생겼을 때 빠르게 인지할 수 있어야하고 문제의 범위를 최소화 할 수 있어야한다.
진화하기
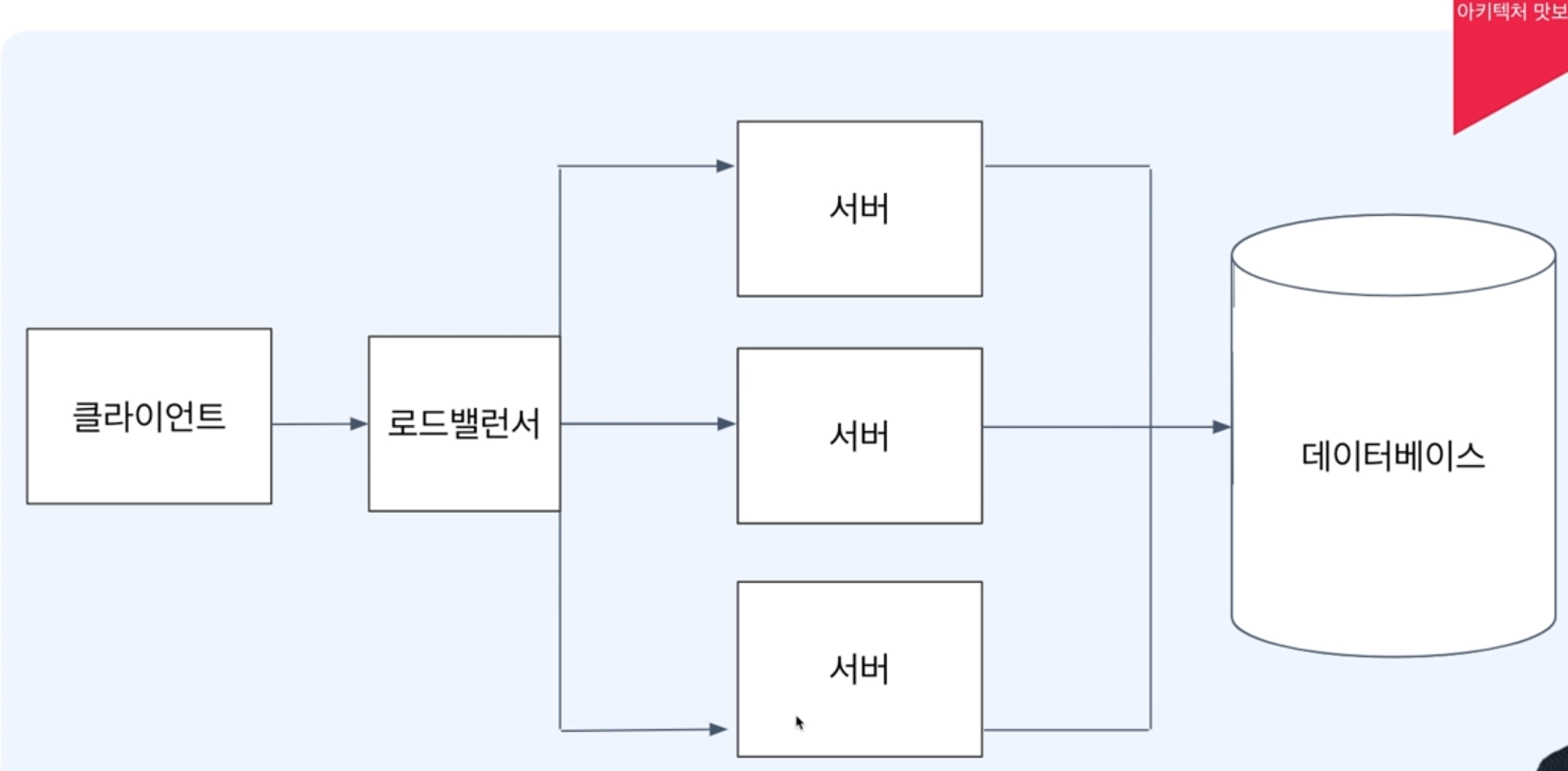
로드밸런서 => nginx
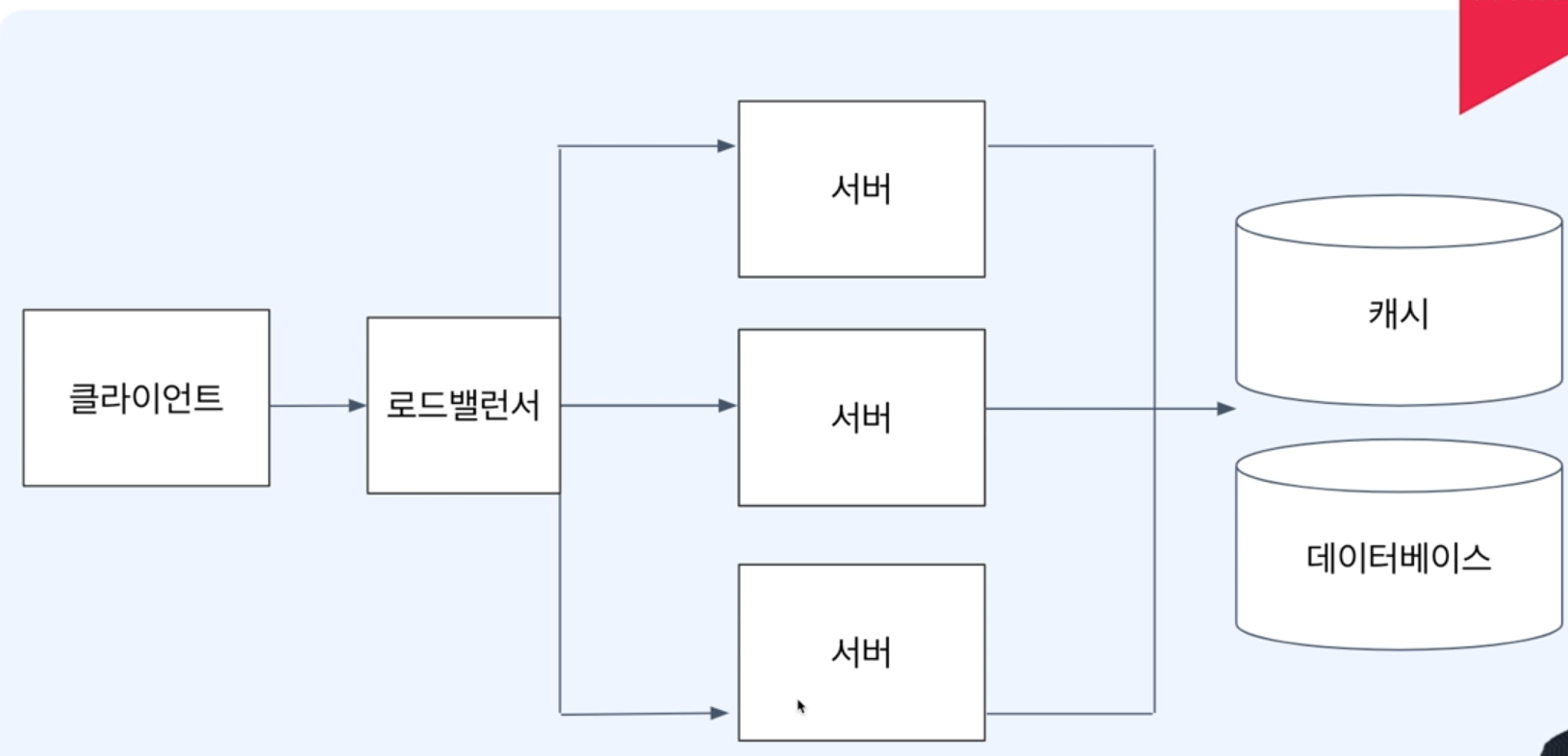
캐시를 둔다. Redis
글로벌 캐싱을 둘지 아니면 로컬 캐싱을 할지를 생각해보자.
캐시의 주기와 만료 조건을 정해서 해준다.
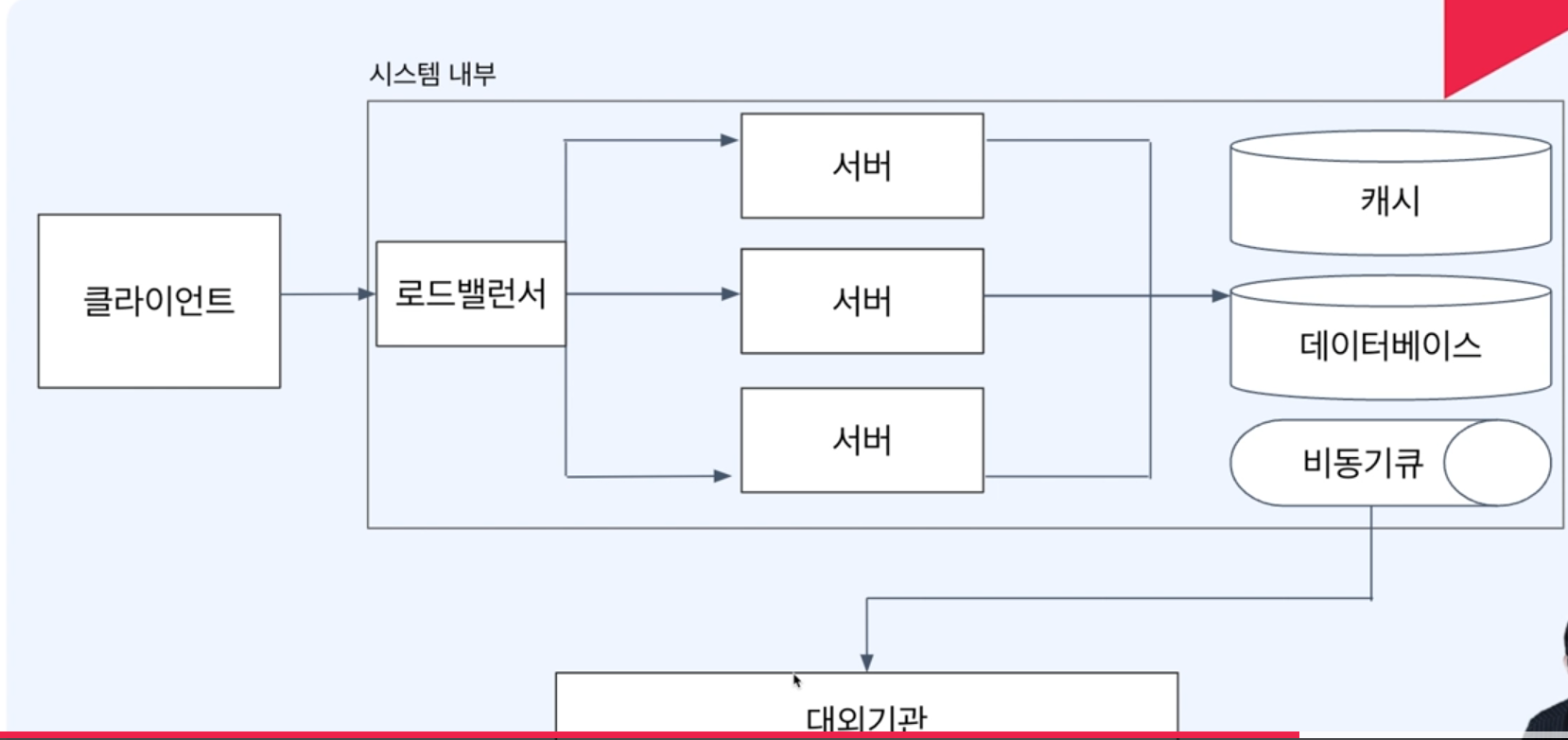
외부 기관과 연동하는 부분에서 속도가 느려진다.
-> 이것을 해결하기 위해서 비동기 큐를 사용한다.
비동기 요청중에 대외기관 연동을 하게 한다.
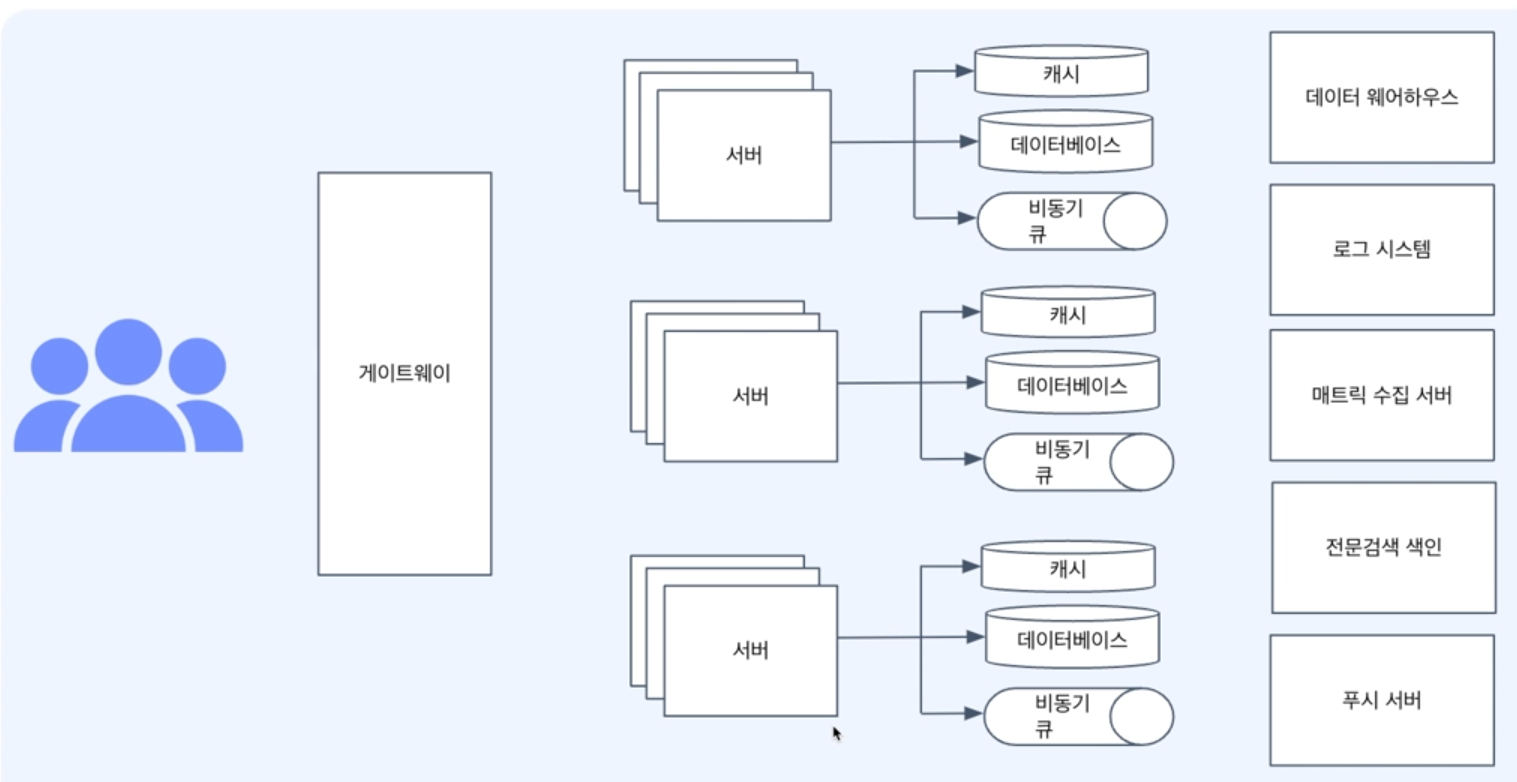
각 기술들이 왜 생겼는지 이게 왜 쓰이는지를 아는 것이 중요하다.
