
생각대로 SQL - 7
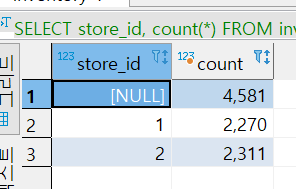
문제1번) 대여점(store)별 영화 재고(inventory) 수량과 전체 영화 재고 수량은? (grouping set)
SELECT store_id, count(*)
FROM inventory i
GROUP BY
GROUPING SETS(
(store_id),
()
)
문제2번) 대여점(store)별 영화 재고(inventory) 수량과 전체 영화 재고 수량은? (rollup)
SELECT store_id, count(*)
FROM inventory i
GROUP BY ROLLUP (store_id) 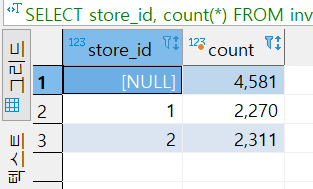
문제3번) 국가(country)별 도시(city)별 매출액, 국가(country)매출액 소계 그리고 전체 매출액을 구하세요. (grouping set)
SELECT country, city, sum(amount)
FROM payment p
INNER JOIN customer c ON p.customer_id =c.customer_id
INNER JOIN address a ON c.address_id = a.address_id
INNER JOIN city c2 ON c2.city_id = a.city_id
INNER JOIN country c3 ON c2.country_id = c3.country_id
GROUP BY
GROUPING SETS (
(country, city),
(country),
()
)
ORDER BY country, city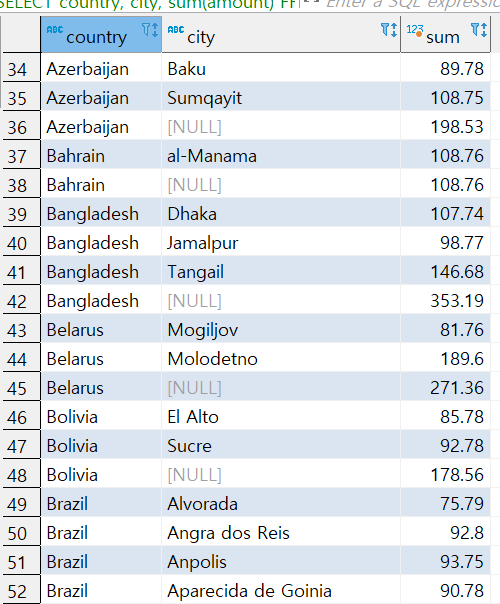
문제4번) 국가(country)별 도시(city)별 매출액, 국가(country)매출액 소계 그리고 전체 매출액을 구하세요. (rollup)
SELECT country, city, sum(amount)
FROM payment p
INNER JOIN customer c ON p.customer_id =c.customer_id
INNER JOIN address a ON c.address_id = a.address_id
INNER JOIN city c2 ON c2.city_id = a.city_id
INNER JOIN country c3 ON c2.country_id = c3.country_id
GROUP BY ROLLUP (country, city)
ORDER BY country, city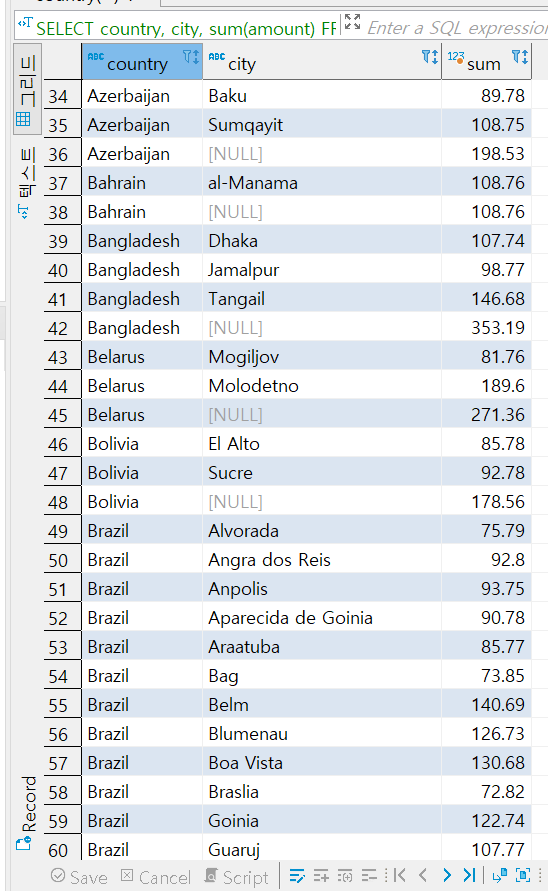
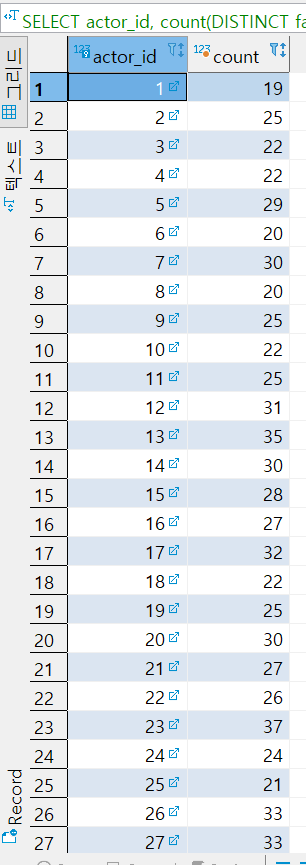
문제5번) 영화배우별로 출연한 영화 count 수 와, 모든 배우의 전체 출연 영화 수를 합산 해서 함께 보여주세요.
SELECT actor_id, count(DISTINCT fa.film_id)
FROM film_actor fa
GROUP BY
GROUPING SETS (
(actor_id),
()
)
문제6번) 국가 (Country)별, 도시(City)별 고객의 수와 , 전체 국가별 고객의 수를 함께 보여주세요. (grouping sets)
SELECT country, city, count(*)
FROM customer c
INNER JOIN address a ON c.address_id = a.address_id
INNER JOIN city c2 ON a.city_id = c2.city_id
INNER JOIN country c3 ON c2.country_id = c3.country_id
GROUP BY
GROUPING SETS (
(country, city),
(country),
()
)
ORDER BY country, city 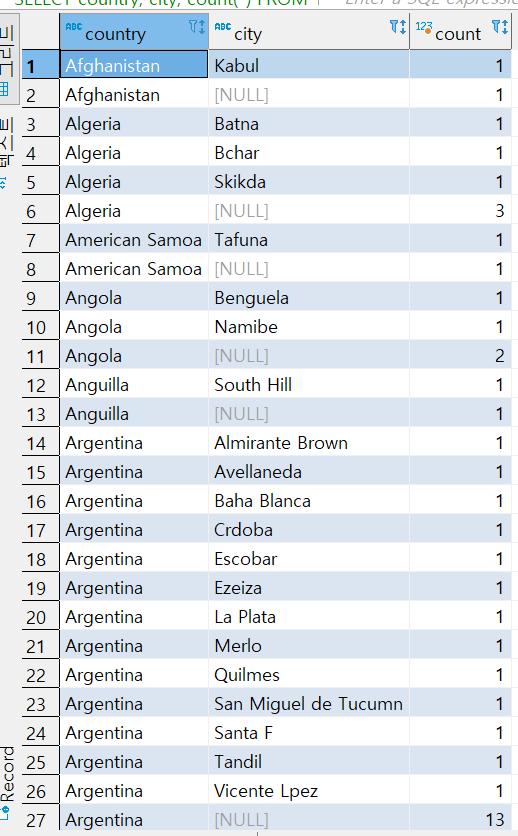
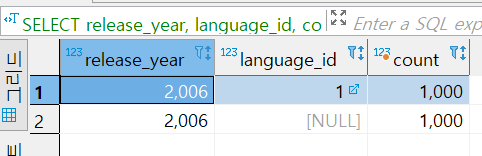
문제7번) 영화에서 사용한 언어와 영화 개봉 연도 에 대한 영화 갯수와 , 영화 개봉 연도에 대한 영화 갯수를 함께 보여주세요.
SELECT release_year, language_id, count(*)
FROM film f
GROUP BY
GROUPING SETS (
(language_id, release_year),
(release_year)
)
문제8번) 연도별, 일별 결제 수량과, 연도별 결제 수량을 함께 보여주세요.
- 결제수량은 결제 의 id 갯수 를 의미합니다.
SELECT
EXTRACT (YEAR FROM p.payment_date) AS YEAR
, EXTRACT (MONTH FROM p.payment_date) AS MONTH
, EXTRACT (DAY FROM p.payment_date)AS DAY
, count(p.payment_id)
FROM payment p
GROUP BY GROUPING sets (
( EXTRACT (YEAR FROM p.payment_date)
, EXTRACT (MONTH FROM p.payment_date)
, EXTRACT (DAY FROM p.payment_date))
, ( EXTRACT (YEAR FROM p.payment_date)
, EXTRACT (MONTH FROM p.payment_date))
, ( EXTRACT (YEAR FROM p.payment_date))
)
ORDER BY YEAR, MONTH, day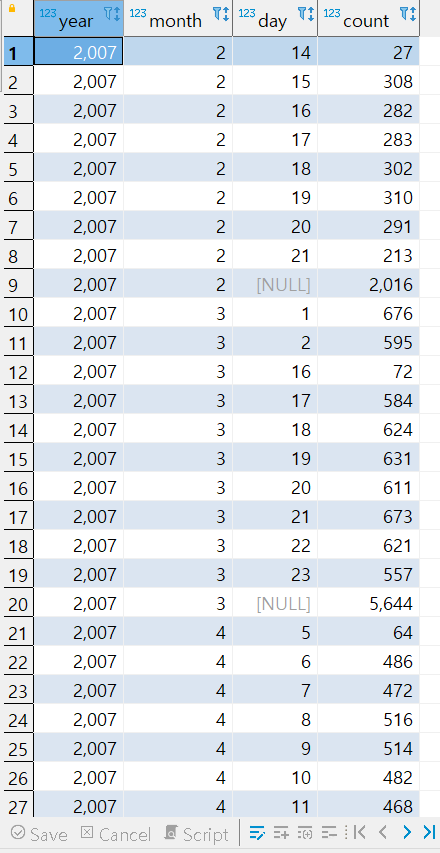
문제9번) 지점 별, active 고객의 수와 , active 고객 수 를 함께 보여주세요.
지점과, active 여부에 대해서는 customer 테이블을 이용하여 보여주세요.
- grouping sets 를 이용해서 풀이해주세요.
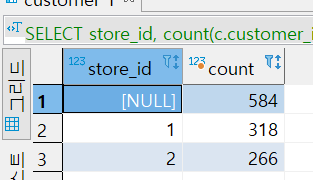
SELECT store_id, count(c.customer_id)
FROM customer c
WHERE c.active = 1
GROUP BY
GROUPING SETS (
(store_id)
, ()
)
문제10번) 지점 별, active 고객의 수와 , active 고객 수 를 함께 보여주세요.
지점과, active 여부에 대해서는 customer 테이블을 이용하여 보여주세요.
- roll up으로 풀이해보면서, grouping sets 과의 차이를 확인해보세요.
SELECT store_id, count(c.customer_id)
FROM customer c
WHERE c.active = 1
GROUP BY ROLLUP (store_id)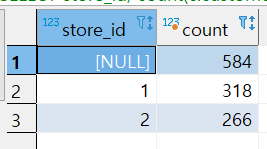
차이점은 GROUPING SETS를 이용하여 ROLLUP을 처리하려면 만약 GROUP의 대상이 많을 경우 번거럽다는 것이다.
분석함수란
특정 집합 내에서 결과 건수의 변화 없이 해당 집합안에서 합계 및 카운트 등을 계산할 수 있는 함수이다.
-실습 환경-
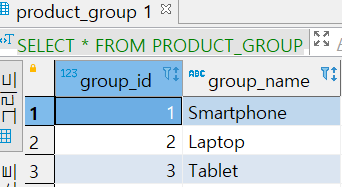
PRODUCT_GROUP
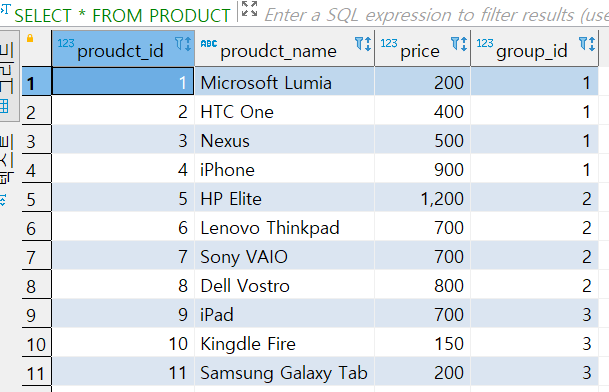
PRODUCT
분석 함수 결과 예시
SELECT COUNT(*)
FROM PRODUCT;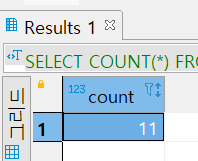
집계함수는 집계의 결과만을 출력한다.
집계결과 및 집합을 함께 보고 싶다 그럴 경우 사용하는 것이 분석 함수이다.
SELECT COUNT(*) OVER() , A.*
FROM PRODUCT A;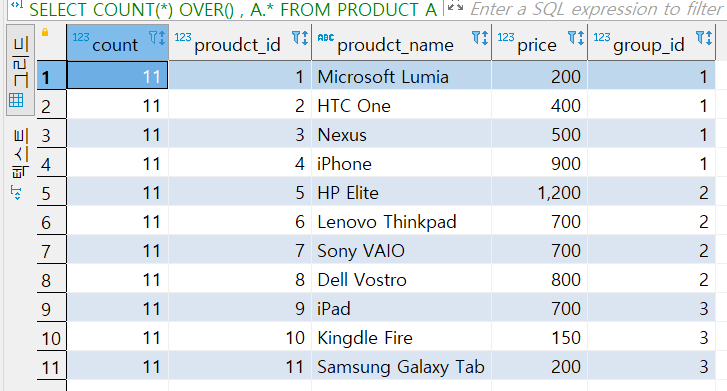
집계와 함께 같이 나왔다.
AVG함수
분석함수 AVG() 부터 본격적으로 분석함수를 학습한다. 그전에 분석함수의 문법에 대해서 간략히 알고 넘어간다.
분석함수 문법
SELECT C1
, 분석함수(C2,C3, ...) OVER (PARTITION BY C4 ORDER BY C5)
FROM TABLE_NAME;사용하고자 하는 분석함수를 쓰고 대상 컬럼을 기재 후 PARTITION BY에서 값을 구하는 기준 컬럼을 쓰고 ORDER BY에서 정렬 컬럼을 기재한다.
<실습>
SELECT AVG(PRICE)
FROM product;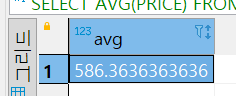
<AVG 함수 실습 -GROUP BY + AVG 구하기>
SELECT b.group_name, AVG(PRICE)
FROM PRODUCT a
INNER JOIN PRODUCT_GROUP b
ON (a.group_id = b.group_id)
GROUP BY
b.group_name;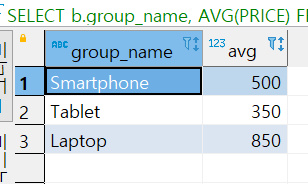
각 그룹 별 AVG를 묶어서 표현을 하였다.
그룹 바이는 그룹으로 묶은 값만을 표현한다.
그렇다면 개개인 값에 그룹 별 AVG를 표현하고 싶다면 어떻게 할까?
이때 쓰는 것이 AVG함수이다.
SELECT p.proudct_name
, p.price
, pg.group_name
, AVG(p.price) OVER (PARTITION BY pg.group_name)
FROM PRODUCT p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)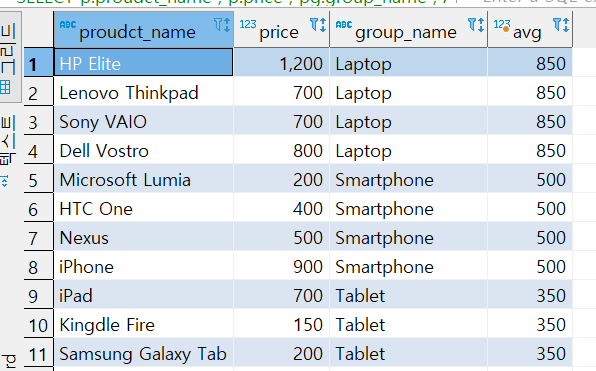
다음과 같이 집계와 함께 각각의 값을 구해서 다음과 같이 결과가 나왔다.
이를 이용하여 누적 합계또한 구할 수 있다.
<누적합계 실습>
SELECT p.proudct_name
, p.price
, pg.group_name
, AVG(p.price) OVER (PARTITION BY pg.group_name ORDER BY p.price)
FROM PRODUCT p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)
ORDER BY를 추가하였다. 이것 때문에 누적 합계가 되었다.
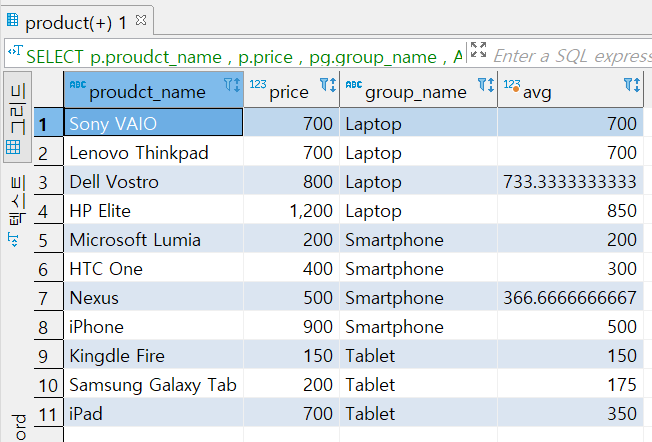
각 줄이 내려가면 내려갈 수록 새로운 평균을 구하였다.
ROW_NUMBER, RANK, DENSE_RANK 함수
특정 집합 내에서 결과 건수의 변화 없이 해당 집합안에서 특정 컬럼의 순위를 구하는 함수이다.
ROW_NUMBER 함수 실습 - 무조건 1, 2, 3, 4, 5 ...
SELECT p.proudct_name
, pg.group_name
, p.price
, ROW_NUMBER () OVER
( PARTITION BY pg.group_name ORDER BY p.price)
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)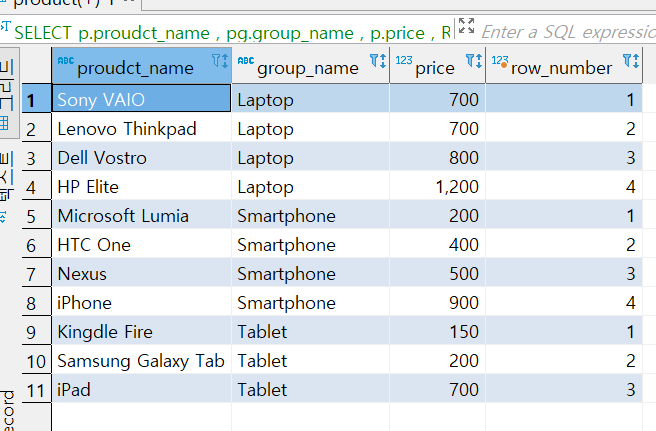
결과를 보면 group_name끼리 그룹별 순위를 매기어 그것을 순위로 나타낸것이다. 오름차순으로 정렬된 결과 값들 순으로 순위가 정해진것을 알수 있다,
Sony VAIO와 Lenovo Thinkpad의 가격은 같지만 순위가 다른것을 알수 있다. 이는 ROW_NUMBER의 특성이다.
ROW_NUMBER는 같은 순위가 있어도 무조건 순차적으로 순위를 매긴다.
그렇다면 같은 순위에 따라 같은 순위를 주는 함수도 있지 않을까?
RANK함수!
RANK 함수 실습 - 같은 순위면 같은 순위면서 다음 순위 건넘뜀 1, 1, 3 ,4
SELECT p.proudct_name
, pg.group_name
, p.price
, RANK () OVER
( PARTITION BY pg.group_name ORDER BY p.price)
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)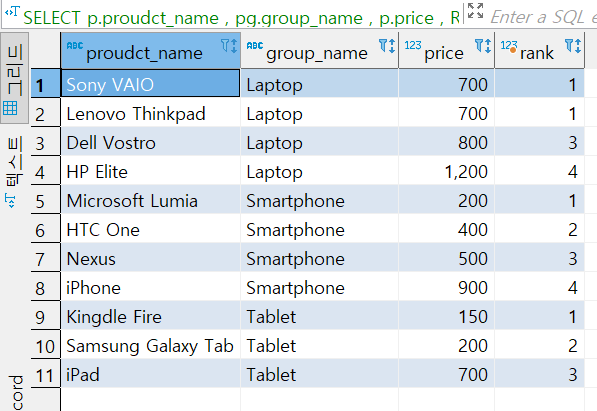
RANK는 같은 순위가 있으면 동일 순위로 매기고 그 다음 순위로 건너뛴다.
다음 순위로 넘어가지 않는 순위로 넘어가는 함수 또한 있다.
DENSE_RANK 함수
SELECT p.proudct_name
, pg.group_name
, p.price
, DENSE_RANK () OVER
( PARTITION BY pg.group_name ORDER BY p.price)
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)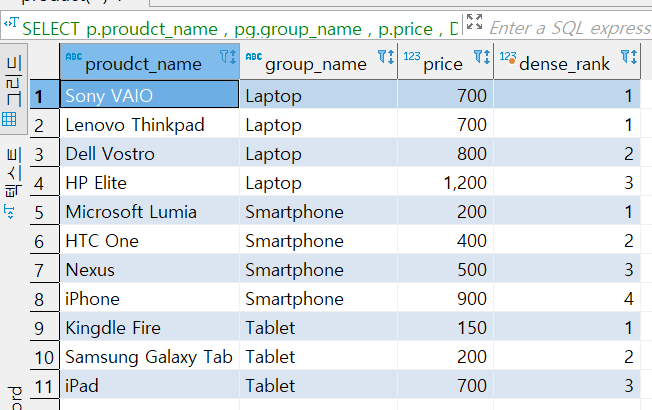
DENSE_RANK는 같은 순위가 있으면 동일 순위로 매기고 그 다음 순위를 건너뛰지 않는다.
FIRST_VALUE, LAST_VALUE 함수
특정 집합 내에서 결과 건수의 변화 없이 해당 집합안에엇 특정 컬럼의 첫번째 값 혹은 마지막 값을 구하는 함수이다.
FIRST_VALUE
가장 첫 번째 값을 구하는 것이다.
그룹 별로 가장 가격이 적은 물품의 가격을 같이 출력하라
SELECT p.proudct_name, pg.group_name, p.price
, FIRST_VALUE (p.price) OVER
(PARTITION BY pg.group_name ORDER BY p.price
)
AS LOWEST_PRICE_PER_GROUP
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)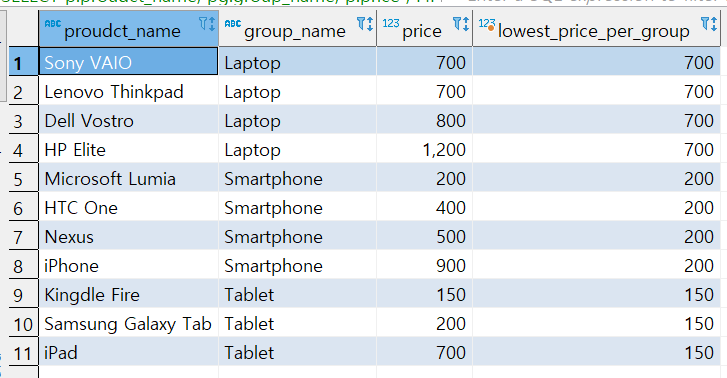
그룹 별 가장 작은 값을 맨 오른쪽에 적어 넣고 있다.
LAST_VALUE
가장 마지막 값을 구하는 것이다.
그룹 별로 가장 가격이 많이 나가는 물품의 값을 같이 출력하라
SELECT p.proudct_name, pg.group_name, p.price
, LAST_VALUE (p.price) OVER
(PARTITION BY pg.group_name ORDER BY p.price
RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
AS HIGHEST_PRICE_PER_GROUP
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)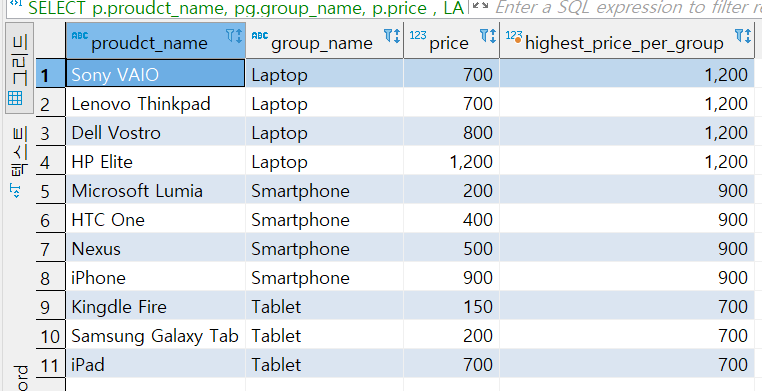
FIRST_VALUE와 다르게 LAST_VALUE는 범위를 적어줘야 한다.
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUND FOLLOWINGS
그룹의 첫벗째 값에서 마지막 값을 범위로 한다라는 뜻을 가지고 있다.
만약 범위를 적지 않는다면 어떻게 될까?
SELECT p.proudct_name, pg.group_name, p.price
, LAST_VALUE (p.price) OVER
(PARTITION BY pg.group_name ORDER BY p.price
)
AS HIGHEST_PRICE_PER_GROUP
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)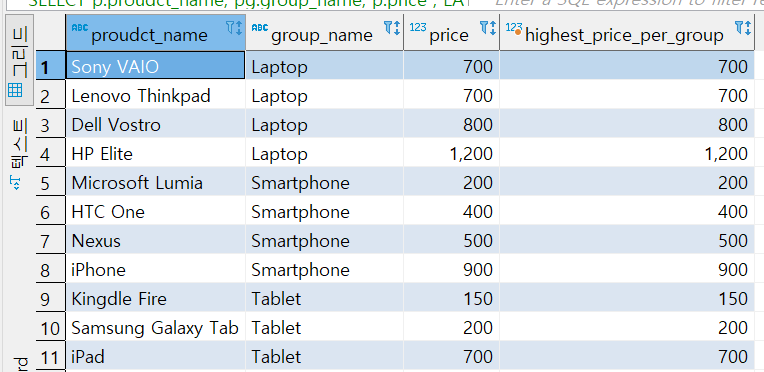
그룹별 마지막 값이 아닌 자기의 값을 한다.
이 이유는 LAST_VALUE의 기본 값이 CURRENT_ROW이기 때문이다.
즉 저 위의 코드는 이것과 같다.
SELECT p.proudct_name, pg.group_name, p.price
, LAST_VALUE (p.price) OVER
(PARTITION BY pg.group_name ORDER BY p.price
RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
)
AS HIGHEST_PRICE_PER_GROUP
FROM product p
INNER JOIN product_group pg
ON (p.group_id = pg.group_id)
현재의 줄까지만 범위를 지정하기 때문에 그것의 가장 마지막 값은 현재 값이다.
LAST_VALUE일 경우
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNF FOLLOWING을 명시 해줘야 한다.
