발표 당일




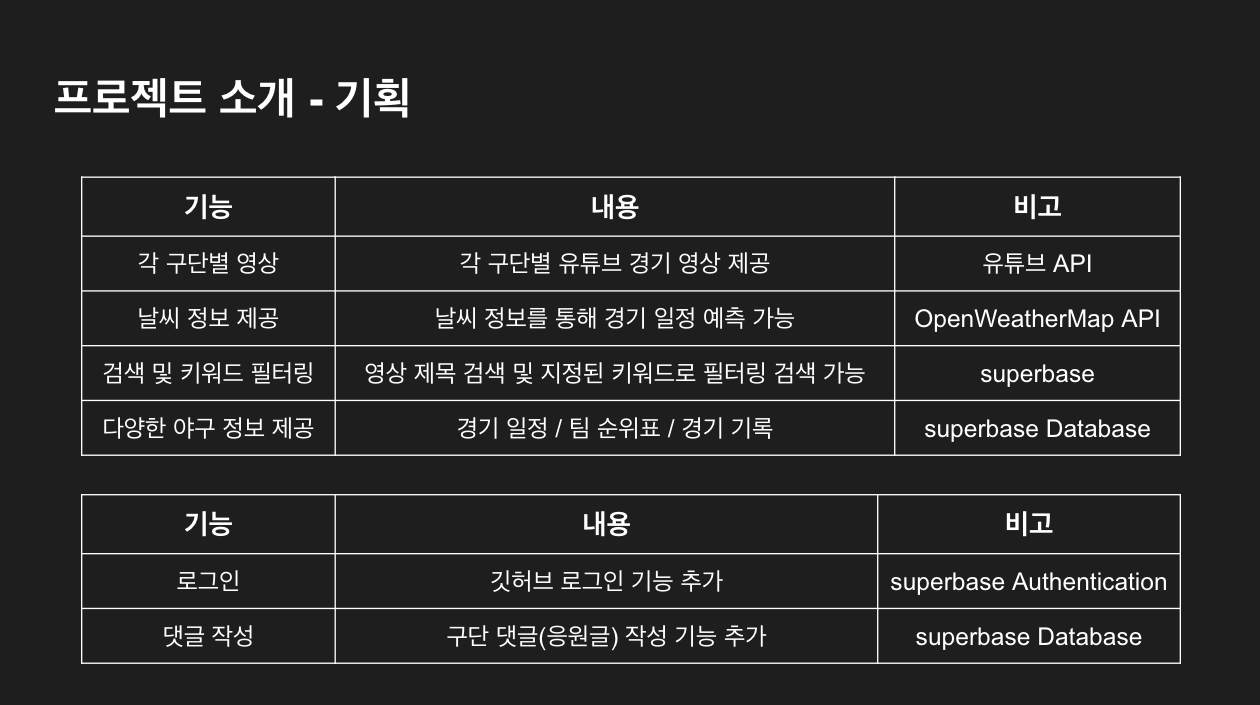

- 저희가 프로젝트를 진행하면서 가장 크게 막혔던 부분은 크롤링 작업중에 생긴 문제였습니다
- 기획상으로 크롤링 작업은 보이시는 세 파일에서 필요했지만, 다음과 같은 문제가 발생하여
다른 방안으로 대체 했습니다.

일단 저희가 생각한 기본 로직은…
크롤링을 할 웹사이트를 열어 필요한 데이터의 태그나 클래스 등을 선택하여 데이터를 추출하고,
추출한 json데이터를 csv형식으로 변환시킵니다.
변환한 csv파일을 ../csv 폴더 안에 생성하는데 이때 ../csv 폴더가 없으면 해당 폴더를 생성하고 변환한 csv파일을 저장합니다
최종적으로는 크롤링한 데이터를 사용자가 접속했을때 보여주고,
만약 사용자가 최신 데이터를 가져오기 위해 새로고침을 하면,최신 데이터를 크롤링하고,
supabase에 있는 데이터들도 자동으로 클롤링된 데이터로 업데이트 시켜주는 것을 생각했습니다.그래서 저희는 필요한 정보를 크롤링 해오는 것 까지는 성공을 했었는데
마지막으로 크롤링한 데이터를 가져오는 부분에서 express와 같은 서버를 이용하여 만들어야 한다는 것을 알게되었고,
저희가 배우지 않은 부분이라 한계가 있었습니다.그래서 현재는 csv파일을 supabase에서 import csv를 통해 직접 업로드하고 있고
추후에 next.js를 배우고 구현을 시도하기로 마무리 되었습니다저희는 이 프로젝트를 진행하며 다양한 기술을 사용해볼 수 있어 좋았습니다.
그리고 협업 시에
깃허브를 어떻게 사용해야 하는지,
소통은 어떤식으로 해야하는지에 대해 많이 배우게 되었던 것 같습니다!


웹 프론트엔드