
현업에서 k8s 환경에 서버를 배포하고 있는데
k8s에 대한 얘기만 나오면 이해를 전혀 못하고 있는 스스로를 보며
내가 배포하는 환경을 쓰면서 모를 수가 있나 싶어...
어떻게 서버를 배포하고 운영하는지 그 흐름을 좀 알아야겠다~ .. 에서 시작된 공부 ...
...
..
근데 또 시간 지나니까 까먹어버렸다ㄷㄷ
그래서 정리와 실습을 동시에 해보려고 함
쿠버네티스 .. 를
정리해보겠다.
🥐 시작하기 전 ...
- 컨테이너 및 도커 개념을 이해하고 있어야 함
- CI/CD 개념에 대해 알고 있어야 함
🟢 쿠버네티스?
쿠버네티스가 뭐냐?
“컨테이너화된 애플리케이션을 배포, 관리, 확장할 때 수반되는 다수의 수동 프로세스를 자동화하는 오픈소스 컨테이너 오케스트레이션 플랫폼”
https://www.redhat.com/ko/topics/containers/what-is-kubernetes
이라고 하는데
내가 이해한대로 말하자면
단순히 테스트용, 개발용으로 컨테이너 하나 띄워서 서버를 사용하는 거라면 문제 없지만 실제 애플리케이션을 서비스로 운영하게 된다면 많은 일이 일어날 수 있다.
1. 서비스 이용률이 많아져서 스케일 아웃을 해야하는 상황
2. 스케일 아웃을 했더니 이용률이 적어져서 스케일 인이 필요한 상황
3. 서버 배포를 했는데 잘 못 올려서 롤백을 해야 하는 상황
4. 어떤 이유로 장애가 발생해서 컨테이너가 죽어서 다시 띄워야 하는 상황등등
근데 이걸 운영자가 계속 모니터링 하면서 컨테이너를 관리한다 ... ? 사실상 어렵다.
그래서 이런 여러 상황에서 컨테이너를 자동으로 관리해주는 오케스트레이션 역할이 필요했던 거고, 그걸 해주는 게 “쿠버네티스(k8s)” 다.
결론 :: 쿠버네티스는 컨테이너 런타임을 이용해서 컨테이너와 그 환경을 관리하는 '오케스트레이션'을 하는 도구
🐳 k8s를 사용했을 때의 장점은?
1. 자동화된 배포 관리가 가능
2. 스케일링
3. 장애 발생 시, 컨테이너 재시작 혹은 스케줄링하여 가용성 유지
4. 롤링 업데이트 및 롤백 - 중단 없이 버전 배포 가능하고 문제 발생 시 이전 버전 롤백 가능
5. 로드밸런싱 - 여러 컨테이너 인스턴스 간에 로드를 분산 시켜 트래픽 균등 유지.
6. 환경 독립적 - 다양한 클라우드 환경 또는 온프레미스에서 동일한 방식으로 관리 가능. 인프라에 종속되지 않는다.
7. 헬스 체크 - 컨테이너가 잘 살아있는지 죽었는지 지속적으로 체크 가능
8. 서비스 디스커버리 및 네트워킹 - 서비스 디스커버리와 기본적인 네트워킹 기능 제공. 애플리케이션 간의 통신 관리따라서, 담당자가 계속 컨테이너가 잘 살아있는지 '계속' 모니터링을 하거나, 큰 부하가 생겼을 때 로드밸런싱 '직접' 처리하거나, 스케일링 작업을을 '직접' 해야하는 수고를 안해도 된다.

짱이잖아.
💂♀️ k8s는 어떻게 구성되어 있을까?
쿠버네티스 클러스터는 크게 노드로 구성되어 있고, 노드는 마스터 노드 와 워커 노드 로 나눌 수 있는데
- 🧙 마스터 노드는 k8s 클러스터 전체를 관리하는 서버 - 팀장님ㄷㄷ
- 🧚 워커 노드는 실제 어플리케이션 컨테이너가 뜨는 서버 - 팀원ㄷㄷ
라고 볼 수 있다.
그리고 마스터 노드는 관리하는 서버답게 워크 노드를 관리하는데, 이 때 컨트롤 플레인인 통해서 관리를 한다.
마스터노드 컨트롤 플레인은 아래와 같이 구성되어 있다.
1. kube-apiserver - 클러스터 외부 및 내부의 모든 요청은 apiserver를 통해서 관리됨.
2. etcd : k8s 클러스터를 구성하는 데이터 저장소
3. kube-scheduler : 파드를 어떤 노드에 배치할 건지 정하는 역할
4. kube-controller-manager : k8s 클러스터 시스템 상태를 관리함
5. kube-dns : 클러스터 내 DNS 역할.
🤔 그럼 마스터 노드는 1대인가? - 아니다. 1대 이상일 수 있고, 클러스터 규모에 따라 설정 가능하다. 2대 이상일 경우에는 서로 통신하면서 리더 선출 방식으로 동작 됨.
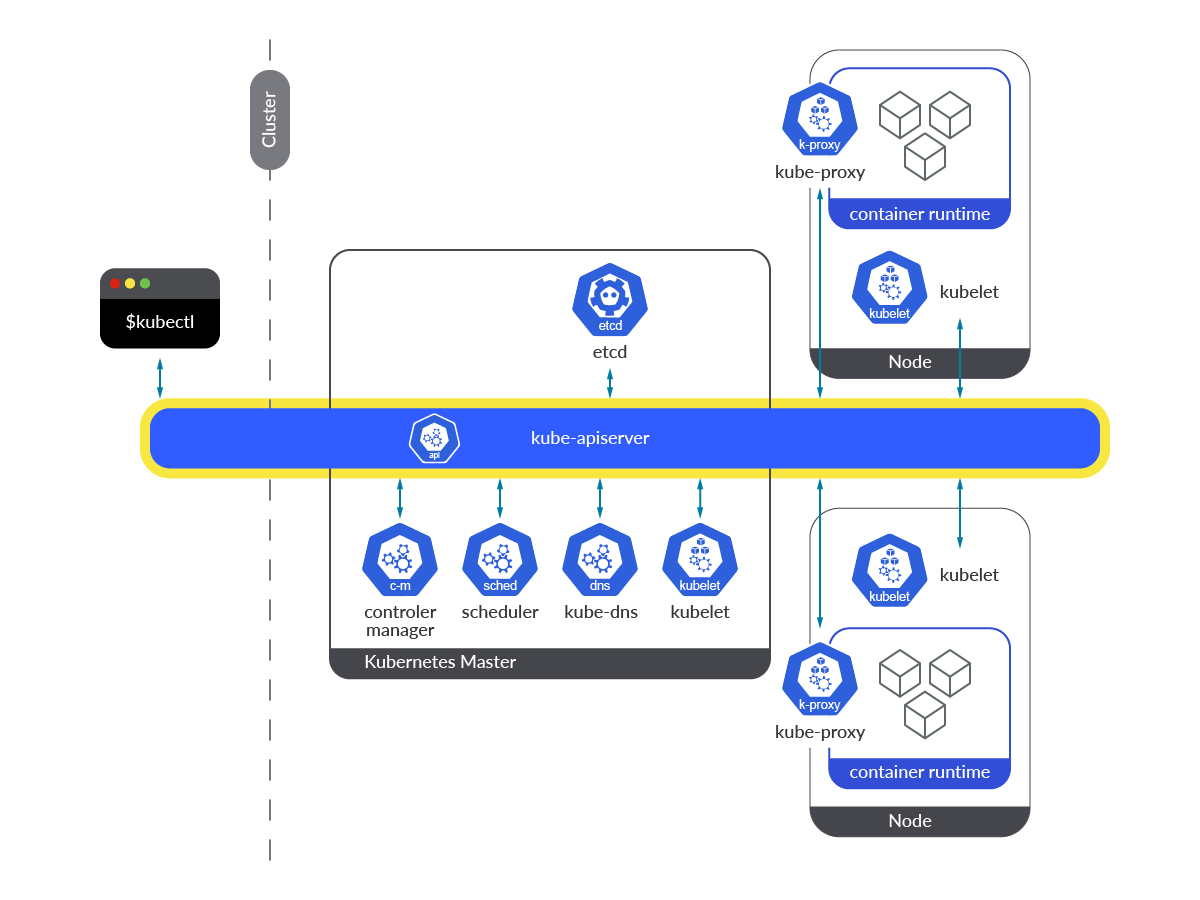
https://sysdig.com/blog/monitor-kubernetes-api-server/?ref=seongjin.me
( 구성 요소마다 다 중요한 역할을 하지만, kube-apiserver가 통신을 하는 데 중요한 역할을 한다는 것을 그림을 통해 알 수 있음 .. )
워커 노드는 아래와 같이 구성되어있다.
1. kubelet - kube-apiserver를 통해 들어오는 신호를 모니터링하고, pod 컨테이너가 잘 동작하는지 확인 함
2. kube-proxy - 클러스터 내부의 네트워크 트래픽을 관리하고, 파드 간 통신 및 외부 트래픽을 파드로 라우팅함
3. container runtime - 실세 컨테이너를 띄우는 곳이기 때문에 런타임이 워커노드에 있다하지만 난 이런 설명을 수 없이 봤으나
그래서 뭐 .. . 어떻게 동작하는데 ,, , , ?
바보 상태로 있다가 한 워커 노드에 파드를 생성, 즉 컨테이너를 띄울 때 동작이 어떻게 이루어지는지 흐름을 보고 나서야 이해할 수 있었ㄷㅏ ...
이 그림을 집중해서 파드를 생성하는 과정을 살펴보면
1. kubectl(쿠버네티스 API를 사용하여 쿠버네티스 클러스터의 컨트롤 플레인과 통신하기 위한 커맨드라인 툴) 에서 파드 생성 명령어 입력.
🥷(운영자) : kubectl야. 파트 생성하라고 전해라
2. kubectl에서 kube-apiserver로 명령어 전달. apiserver는 etcd에 변경사항 업데이트 함.
[kubectl] 파드 생성하셈
[kube-apiserver] ㅇㅋ. @everyone 파드 생성하래!!!!!!!
[etcd] ㅇㅋ 알고있겠음
3. kube-controller-manager는 apiserver로 부터 명령이 떨어진 걸 감지하고, 파드 생성에 필요한 설정을 해둠.
그 후에 다시 apiserver에 업데이트 함.
[kube-controller-manager] 뭐 파드 생성하라고? ㅇㅋ 만들 수 있게 설정해 놓겠음.
4. kube-schedule는 이때, 생성해야하는 파드를 어느 워커 노드에 할당할 지 정함.
리소스 사용량이나 조건등을 확인해서 워커 노드를 선택함.
선택된 워커 노드의 kubelet이 apiserver를 통해 파드 생성 명령을 따름. 컨테이너 런타임을 통해 파드 생성
[kube-schedule] ㅇㅋ 아 근데 이 파드 어디에 생성하냐... (고민) 워커노드 1아.. 너가 담당하셈
[apiserver] 들었지?
[워커노드1 - kubelet] 응... 만들게
* (3), (4) 순서에서 apiserver는 계속 변화를 감시하는 역할을 함.
그래서 스케줄러가 노드를 선택하면 apiserver가 감지하고 이걸 kubelet이 알아차리는 형태
6. 파드 생성되면 워커 노드의 kube-proxy를 통해 사용자는 파드와 통신이 가능하게 됨.
kube-proxy는 클러스터 내부의 네트워크 트래픽을 관리하고, 파드 간 통신 및 외부 트래픽을 파드로 라우팅하는 역할
[워커노드1 - kube-proxy] 파드랑 통신하고 싶음? 내가 해주겠음
이 동작을 통해 컨트롤플레인을 통해서 마스터 노드랑 워커 노드랑 어떻게 통신하는지, 그리고 파드를 생성할 때 각 요소들이 어떻게 자기 역할을 행하는지 이해할 수 있다.
🫥 자꾸 노드... 파드.. 라고 하는데 그게 뭐임?
노드는 어느 정도 설명했으니 알겠지만, k8s를 잘 모르는 사람은 위에서 말한 파드가 뭔지 모를 수가 있다... 그래서 동작 원리는 알았고 쿠버네티스의 리소스에 대해서 정리하고자 함.
위에 파드를 생성할 때 그냥 파트 명령어 하나만 치면 되는 것처럼 보이지만 사실상, 그 밖에 설정할 게 생각보다 많다.
우선 pod(파드) 란 우리가 일반적으로 생각하는 컨테이너다. 애플레케이션을 띄우면 그게 컨테이너인데 그걸 보통 쿠버네티스에서는 파드라고 한다.
그럼 파드를 띄울 때, 하나만 띄울건가 여러 개를 띄울건가? 파드를 하나만 띄우면 어차피 죽었을 때 다시 살아나기야 하지만... 애초에 파드를 두 개 띄워놓는다면? 하나가 죽어도 나머지 하나가 계속 살아있다면 가용성이 보장될 것이다. ( 보통 이걸 리플리카세트라는 걸로 설정해놓는다. )
이런 것처럼 사실 쿠버네티스는 훨씬 복잡한 것 같다.
그리고 파드를 띄웠을 때, 이 파드는 내부적으로만 통신할 지 ... 아니면 외부로 나가게 할지에 대한 설정도 할 수 있다.
이처럼 이러한 설정을 할 수 있게 하는 리소스들이 있는데, 나는 간단하게 설명해놓는 것으로 마무리 한다..
** 각 리소스마다 필요한 매니패스트 파일(= 쿠버네티스의 오브젝트를 생성하기 위한 메타 정보를 YAML이나 JSON으로 기술한 파일) 이 있는데 이 내용은 생략함 ... 내용 너무 길고 .. 힘듦 하하 어차피 구성할 때 사용하게 되니까 그 때 보는 것으로.
🥷 쿠버네티스 리소스 목록
🌟 pod (파드)
컨테이너의 집합 중 가장 작은 단위
하나 이상의 컨테이너를 포함한다.
같은 파드 내 컨테이너들은 동일한 네임스페이스를 공유하고, 서로 통신하거나 볼륨을 공유할 수 있다.
🌟 node (노드)
워커 노드
컨테이너가 배치되는 서버
쿠버네티스 클러스터에서 워커 역할을 하는 물리적 또는 가상 서버다.
각 노드는 여러 개의 파드를 띄울 수 있음.
- 구성 요소 : kube-let, 컨테이너 런타임, kube-proxy
마스터 노드
위에 있으므로 생략한다.
🌟 namespace (네임스페이스)
쿠버네티스 클러스터 안의 가상 클러스터
리소스를 논리적으로 구분할 수 있음.
만약 각각의 여러 프로젝트가 하나의 쿠버네티스 클러스터를 공유한다면 이 네임스페이스로 구분할 수 있음.
쇼핑몰 서비스와 채팅 서비스는 엄연히 다른 서비스이지만, 같은 클러스터 안에서 애플리케이션을 배포할 수 있다는 뜻이다
🌟 replicaset (레플리카 세트)
같은 스펙을 갖는 파드를 여러 개 생성하고 관리하는 역할
특정 수의 파드가 항상 실행되도록 보장하는 리소스
만약에 장애가 나서 파드가 종료되거나 삭제되면 그 수에 맞게 새로운 파드를 자동으로 띄움 = 가용성 보장 됨!
🌟 deployment (디플로이먼트)
애플리케이션 배포와 관련된 설정을 관리하는 리소스
레플리카 세트를 관리
롤링 업데이트, 롤백 등을 수행
새로운 버전의 애플리케이션을 중단 없이 배포하거나, 문제가 발생하면 이전 버전으로 쉽게 롤백할 수 있음
🌟 service (서비스)
파드들 간의 네트워크 통신을 지원하는 리소스
파드가 재배포 되거나 아이피가 변경되어도 서비스를 통해 계속 통신을 지속할 수 있음
- 종류
ClusterIP : 클러스터 내부에서만 접근 가능한 IP를 제공함
NodePort : 각 노드의 고정된 포트를 통해 외부에서 접근할 수 있게 해줌
LoadBalancer : 클라우드 환경에서 로드밸런서를 사용하여 외부 트래픽을 분산시킴
🌟 ingress (인그레스)
HTTP 및 HTTPS 트래픽을 특정 서비스로 라우팅하는 규칙을 정의하는 리소스
서비스를 쿠버네티스 클러스터 외부로 노출 시킴.
즉, 쿠버네티스 클러스터의 애플리케이션에 접근할 수 있도록 해준다.
🌟 configmap (컨피그맵)
애플리케이션의 설정 정보를 저장하는 리소스
컨테이너 이미지와 설정을 분리하여 유연하게 관리할 수 있음
환경 변수, 설정 파일 등을 파드에 전달할 때 사용
🌟 secret (시크릿)
민감한 정보를 저장하는 리소스
비밀번호, API 키, 인증서 등 데이터를 암호화 하여 관리할 수 씨음
컨피그맵과 유사하나, 보안이 강화된 방식으로 처리 됨
🌟 volume (볼륨)
파드 내 컨테이너들이 데이터를 공유하거나 저장할 수 있는 스토리지 리소스 (퍼시스턴스 볼룸, 퍼시스턴스볼륨클레임 등)
종류
- PersistentVolume (PV): 클러스터 내에서 영구적으로 데이터를 저장하는 리소스.
- PersistentVolumeClaim (PVC): Pod가 특정한 영구 스토리지를 요청할 때 사용하는 리소스.
🌟 job (잡)
특정 작업을 한 번 실행하고 종료하는 리소스
🌟 cronjob (크론잡)
정해진 시간에 반복적으로 작업을 실행하는 리소스
🌟 demonset (데몬셋)
클러스터 내의 모든 노드에서 특정 파드가 하나씩 실행되도록 보장하는 리소스
시스템 모니터링, 로그 수집 등의 작업을 각 노드에서 실행할 때 사용함
🌟 statefulset (스테이트풀세트)
상태를 유지해야 하는 애플리케이션을 관리하는 리소스
같은 스펙으로 모두 동일한 파트를 여러 개 생성하고 고나리함
🌟 HPA (Horizontal Pod Autoscaler)
파드의 CPU, 메모리 사용량에 따라 자동으로 스케일링 할 수 있도록 도와주는 리소스
부하에 맞춰서 리소스 사용량 최적화 할 수 잇음

끝.
다음은 애플리케이션 쿠베에 띄워보기다 ...
