집계함수
강의에서 소개한 집계함수로는 다음과 같다.
COUNT
SUM
AVG
MIN
MAX
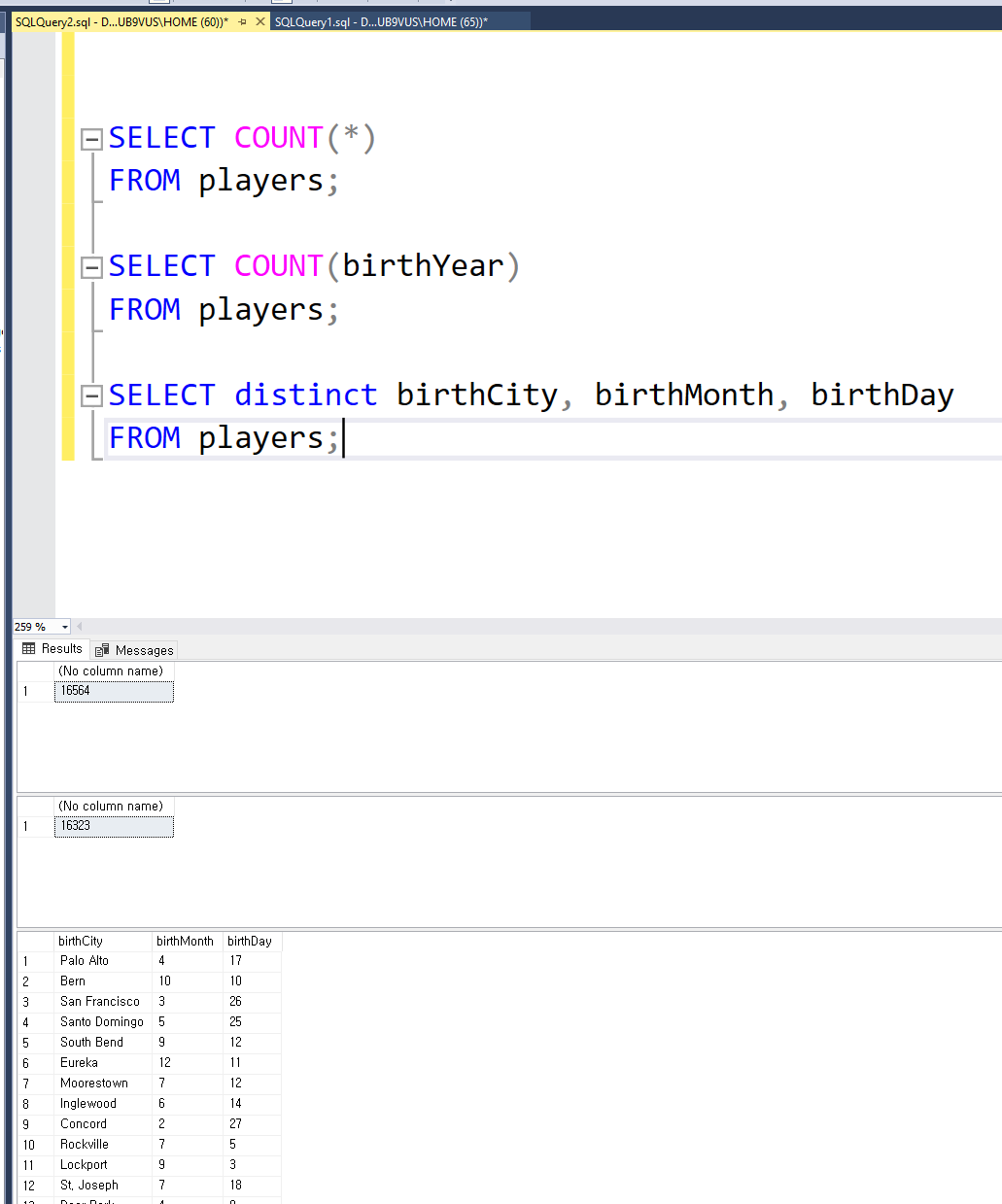
위 사진에서 알 수 있는 사실은
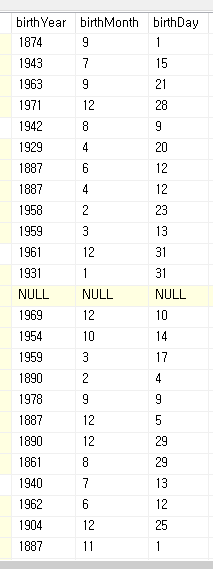
집계함수의 특징 중 하나는 NULL값을 무시한다는 것이다.
COUNT(*)를 한 개수와 COUNT(birthYear)를 한 개수가 다른데, 이는 birthYear의 값이 NULL로 저장이 된 경우가 있어서 그렇다.
두번째 사실은 SELECT할때 DISTINCT 키워드를 붙이면 중복된 값을 제외하고 가져오게 되는데, distinct birthCity, birthMonth, birthDay 이렇게 되어 있으면 저 세 열의 값을 한뭉텅이로 보고 중복을 제외한다는 것이다.
GROUP BY
GROUP BY를 사용하면 열에서 같은 값을 하나로 묶어버리기 때문에 그룹으로 묶인 각 열들의 다른 행의 값들은 소실된다.
즉,
birthYear | birthMonth
2001 5
2001 6
2001 7
2002 8
2002 9
GROUP BY birthYear로 하면
birthYear
2001
2002
이렇게 묶이게 될 것이고 birthYear가 2001이었던 birthMonth의 5, 6, 7은 2001 하나의 행에 할당될 수 없으므로 잊혀지게 될 것이다.
따라서 집계함수를 사용할때 GROUP BY를 사용하고 GROUP으로 묶어준 열만 SELECT할 수 있다.
GROUP BY teamID, yearID 로 한 경우
BOS 2004
BOS 2004
BOS 2005
BOS 2005
BOS 2006
이렇게 있을떄
GROUP BY teamID
BOS
GROUP BY yearID
2004
2005
2006
GROUP BY teamID, yearID
BOS 2004
BOS 2005
BOS 2006
작성순서
SELECT teamID, SUM(HR) AS homeRuns
FROM batting
WHERE yearID = 2004
GROUP BY teamID
HAVING SUM(HR) >= 200
ORDER BY homeRuns DESC;실행순서
- FROM : batting 테이블에서
- WHERE : yearID가 2004인 것만
- GROUP BY : teamID의 값을 분류하고
- HAVING : 분류한 다음 팀 내에서 날린 홈런의 수가 200이상인 팀만
- SELECT : 갖고와서
- ORDER BY : homeRuns을 내림차순으로 나열하자.
예제
- 입력된 태어난 도시의 종류를 가져오자
SELECT COUNT(DISTINCT birthCity) FROM players;- 플레이어의 평균 몸무게를 출력해보자 (단, 몸무게가 NULL이면 0으로)
SELECT AVG(CASE WHEN weight IS NULL THEN 0 ELSE weight END) FROM players;- 2004년도에 가장 많은 홈런을 날린 팀은?
SELECT TOP 1 teamID, COUNT(teamID) AS playerCount, SUM(HR) AS homeRuns
FROM batting
WHERE yearID = 2004
GROUP BY teamID
ORDER BY homeRuns DESC;- 2004 년도에 200 홈런 이상을 날린 팀의 목록은?
SELECT teamID, SUM(HR) AS homeRuns
FROM batting
WHERE yearID = 2004
GROUP BY teamID
HAVING SUM(HR) >= 200
ORDER BY homeRuns DESC;- 당해 가장 많은 홈런을 날린 팀은?
SELECT teamID, yearID, SUM(HR) AS homeRuns
FROM batting
GROUP BY teamID, yearID
ORDER BY homeRuns DESC;