MongoDB는 NoSQL 중 Document-Oriented Database에 속한다.
MongoDB는 효율적인 query의 수행을 위해 Index를 지원한다.
만약, Index를 사용하지 않는다면, query 수행을 위해 collection에 있는 모든 document를 scan해야 한다.
따라서 MongoDB에서 적절한 Index를 활용하면 scan해야 되는 document의 수를 줄일 수 있다.
Index를 통해 query 성능을 개선할 수 있지만, Index를 설정한 field에 영향을 주는 Insert 작업을 수행할 때마다 해당 field에 대한 모든 Index를 Update하기 때문에 Index를 추가하는 것은 write operation에 안좋은 영향을 미친다.
MongoDB의 경우 Index는 어떻게 적용하고 동작하는지 알아보자
MongoDB의 Index
MongoDB의 Index는 B-tree 자료구조를 이용함
Index에 특정한 필드나 필드 집합의 값을 저장하고 그 값을 바탕으로 정렬한다.
MongoDB는 Default Index로 _id 필드를 가지며 해당 필드는 unique index로 설정된다.
Index의 이름은 기본적으로 index key의 이름과 정렬 방향으로 설정된다.
MongoDB Index의 제약사항은 아래와 같다.
- 하나의 Collection은 최대 64개의 Index를 가질 수 있음
- Compound Index는 최대 32개의 필드를 가질 수 있음
- Multikey Index는 array field에 대한 query를 처리할 수 없음
MongoDB Index의 종류
MongoDB에는 다양한 Index가 존재한다.
Single Field Index
단일 필드에 Index를 설정하는 방법이다.
특정 field에 반복적으로 query를 수행하는 경우 적용하는 것이 좋다.
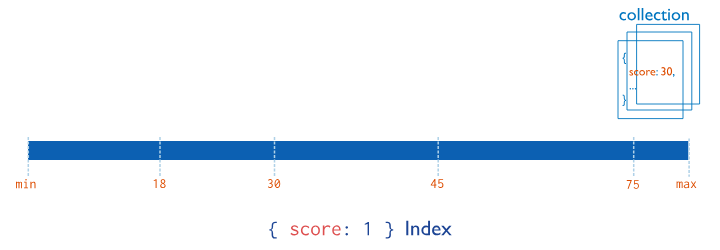
- Top-level document field에 적용
- index가 해당 필드를 포함하는 query를 지원한다.
- Embedded document에 적용
- embedded document를 하나로 보고 index를 설정한다.
- index가 해당 embedded document 통째를 포함하는 query를 지원한다.
- Embedded document에 있는 field에 적용
- embedded document의 특정 field에 index를 설정한다.
- index가 embedded document의 해당 필드를 포함하는 query를 지원한다.
Compound Index
두 가지 이상의 필드에 Index를 설정하는 방법이다.
Data가 각 필드에 대해 순서대로 grouping 된다.
여러 field를 포함한 query를 반복적으로 사용하는 경우 적용하는 것이 좋다.
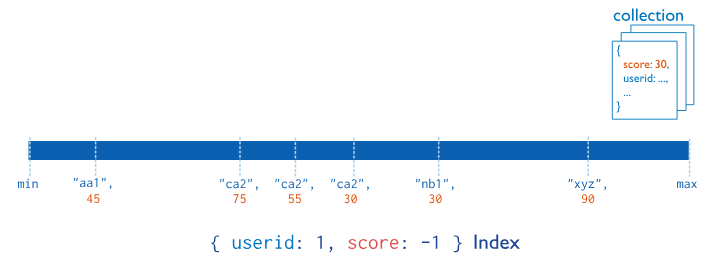
Compound Index는 index에 포함한 field들의 order에 따라 reference를 보유하므로, order에 성능이 영향을 받는다.
=> 효과적으로 생성하기 위해서는 ESR(Equality, Sort, Range) rule을 따라야 한다.
Equality: single value와 정확히 일치하는 field를 앞에 배치하라
Sort: result의 order를 결정하는 sort가 index를 활용하도록 sort key 앞에 있는 모든 prefix key들이 eqaulity condition을 포함해야 함
Range: scan한 field를 filtering한 결과에 index sort를 수행하지 않으므로 맨 뒤에 배치해야 함
Compound Index의 경우 index prefix를 포함한 query를 지원한다.
ex) {item: 1, location: 1, stock: 1}인 경우
다음과 같은 field를 대상으로 하는 query에 index가 적용된다.
itemitem, locationitem, stockitem, location, stock
Compound Index의 경우 sort order에 따라 index가 sort를 지원할지를 결정함
=> index의 sort order와 query의 sort order가 일치하면 query 성능이 향상됨
=> index의 sort order와 query의 sort order가 완전히 반대여도 index가 적용됨
ex) index가 {score: 1, username: -1}인 경우
위 두가지 query에 index가 적용됨
db.collection.find().sort({score: 1, username: -1})db.collection.find().sort({score: -1, username: 1})
아래와 같은 경우는 index가 적용되지 않음
db.collection.find().sort({score: 1, username: 1})db.collection.find().sort({username: 1, score: -1})
또한 eqaulity가 index prefix를 만족하면 sort가 index prefix를 만족하지 않아도 index 기능을 지원한다.
Multikey Index
Array field에 대해 index를 설정하는 방법이다.
Scalar value나 Embedded document로 구성된 array에 설정할 수 있다.
Array에 있는 값을 포함한 field를 빈번하게 query하는 경우 적용하는 것이 좋다.
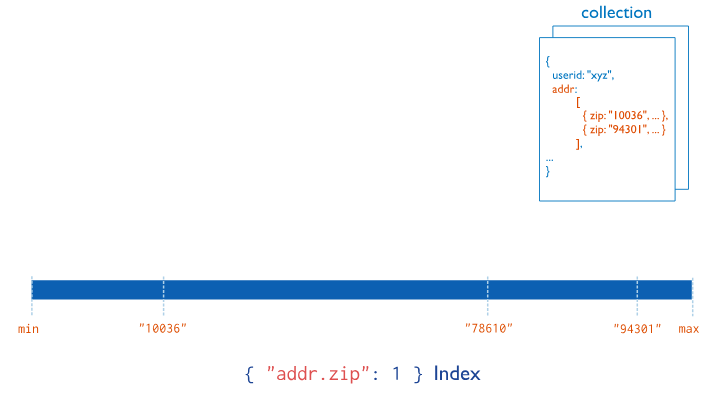
만약 object array에 대해서 sort를 진행하는 경우, document의 해당 array field의 값 중 최소값 또는 최대값을 기준으로 sort를 진행한다.
예를 들어, 내림차순이라면 최대값을 기준으로, 오름차순이라면 최소값을 기준으로 진행
또한 Index Bound를 통해 index 값의 범위를 지정할 수 있음
-
Bound Intersection
-
$elemMatch를 통해 조회 범위의 교집합을 생성할 수 있음
db.students.find( { grades : { $elemMatch: { $gte: 90, $lte: 99 } } } )
grades의 범위가 [90, 99] -
$elemMatch를 사용하지 않으면, 각 범위를 만족하는 원소가 하나라도 있는 array를 찾게 되어 어떤 범위를 선택하는지 보장할 수 없음
db.students.find( { grades: { $gte: 90, $lte: 99 } } )
grades의 범위가 [90, INFINITY] 또는 [-INFINITY, 99]
-
-
Compound Bound
-
Compound Index의 key의 조회 범위를 합치는 것
db.survey.find( { item: "XYZ", ratings: { $gte: 3 } } )
item의 범위는 ["XYZ", "XYZ"]이고 ratings의 범위는 [3, INFINITY] -
교집합이 생기지 않으면, 앞에 있는 key의 범위를 사용함
-
non-array field와 compound하는 경우,
$elemMatch로 명시하지 않는 경우, 어떤 array field와 합쳐질 지 보장할 수 없음
db.survey2.find({item: "XYZ", "ratings.score": { $lte: 5 }, "ratings.by": "anon"})
item의 범위가 ratings.score와 결합하거나
item: ["XYZ", "XYZ"], ratings.score: [-INFINITY, 5], ratings.by: [MinKey, MaxKey]
item의 범위가 ratings.by의 범위와 결합할 수 있음
item: ["XYZ", "XYZ"], ratings.score: [MinKey, MaxKey], ratings.by: ["anon", "anon"] -
$elemMatch를 사용하여 array field끼리 compound할 수 있음
db.survey2.find( { ratings: { $elemMatch: { score: { $lte: 5 }, by: "anon" } } } ) -
공통의 path를 공유하는 field에
$elemMatch를 사용하는 경우
db.survey3.createIndex( { "ratings.scores.q1": 1, "ratings.scores.q2": 1 } )와 같이 index가 생성되었을 때
db.survey3.find( { ratings: { $elemMatch: { 'scores.q1': 2, 'scores.q2': 8 } } } )가 아닌
db.survey3.find( { 'ratings.scores': { $elemMatch: { 'q1': 2, 'q2': 8 } } } )와 같이 사용해야 함
-
Text Index
String 내용을 포함한 필드에 대한 text search query를 지원한다.
String 내용에서 특정 단어나 구절을 찾을 때 query 성능을 개선할 수 있다.
Text Index는 다음을 구분하지 않음
- 대소문자
- 발음 구별 부호
- 구분문자
한 Collection에 한 개의 text index를 가질 수 있지만, 해당 index가 여러 field를 포함할 수 있음
또한 각 field마다 가중치를 다르게 설정하여 query 결과를 가중치로 정렬할 수도 있음
Text Index는 항상 sparse로 설정되어, 존재하거나 새로 생긴 document가 text index field가 부족하면, 해당 document를 text index에 추가하지 않음
하지만, Text Index는 storage requirement와 performance cost가 있음
- 많은 양의 RAM을 필요로 함 + write 성능에 영향을 줌
=> 각 document가 삽입될 때마다 각 index field에서 고유한 형태소마다 index를 생성하기 때문
=> 형태소 분석 기능의 지원을 하는 언어는 제한적임 - text index는 생성하는 데 시간이 오래 걸림
- open file descriptor에 대해 충분한 limit을 설정해야 함
- text index는 비슷한 단어에 대한 정보를 저장하지 않음
Text Index는 온프레미스 환경에서 $text query를 지원하여 사용함
db.blog.createIndex( { "content": "text" } )
db.blog.find({$text: { $search: "coffee" }})
text index를 설정한 content field에 대해서만 text search query를 지원함
wildcard를 이용하여 collection의 모든 field에 index를 설정할 수 있음
db.blog.createIndex( { "$**": "text" } )
wildcard text index의 경우 document가 insert 또는 update되면 모든 string field value에 대한 update를 수행하여 성능에 문제를 유발할 수 있다.
=> index를 사용하려는 field를 모르거나 변할 가능성이 있을때만 사용하는 것이 좋다.
띄어쓰기를 이용하여 or 조건으로 검색이 가능하다.
db.blog.find( { $text: { $search: "poll coffee" } } )
큰따옴표를 이용하여 정확히 일치하는 조건으로 검색이 가능하다.
db.blog.find( { $text: { $search: "\"chocolate ice cream\"" } } )
Wildcard Index
MongoDB는 잘 모르거나 변할 수 있는 field에서 사용할 수 있는 wildcard index를 지원함
db.collection.createIndex( { "$**": <sortOrder> } )와 같이 설정하여 사용할 수 있음
Index 속성 종류
- Case-Insensitive Index: 대소문자 구분을 하지 않는 query를 지원
- Hidden Index: index를 삭제 대신 숨길 수 있는 기능을 지원
- Partial Index: 특정 filter 표현을 만족하는 document에만 index 생성을 지원
- Sparse Index: index field를 보유한 document에만 index를 생성
- TTL Index: 일정 시간이 지나면 자동으로 document를 삭제
- Unique Index: field에 중복 값을 방지하는 index
MongoDB Shell을 이용한 Index 관리
Index 생성
mongosh 명령어를 통해 MongoDB Shell에 접속을 진행한다.
db.collection.createIndex({"key이름": "정렬방향" })
ex) db.user.createIndex({ name: -1 })
user collection의 name field에 대해 single key 내림차순 index를 생성한다.
Single field index의 경우 양방향으로 탐색할 수 있기에 order는 상관이 없다.
db.collection.getIndexes()를 통해 생성된 index를 확인한다.
Index 제거
db.collection.dropIndex("index 이름")
또는 db.collection.dropIndexes("index1 이름", "index2 이름")를 통해 index를 제거할 수 있다.
ex) db.user.dropIndex("name_1")
user collection의 index name이 name_1인 index를 제거한다.
Index 측정
$indexStats를 사용하여 index 사용 통계를 확인할 수 있다.
db.orders.aggregate( [ { $indexStats: { } } ] )
db.collection.~.explain()을 통해 index 사용, scan한 document 수, query 수행에 걸린 시간과 같은 query 수행과 관련된 통계를 얻을 수 있음
db.collection.~.hint()를 통해 사용할 index를 명시할 수 있음
ex)
db.people
.find({ name: "John Doe", zipcode: { $gt: "63000" } })
.hint( { zipcode: 1 } )
.explain("executionStats")Spring Data JPA를 활용한 MongoDB Index
build.gradle에 원하는 버전에 해당하는 dependency를 추가하여 사용할 수 있다.
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb:2.1.5.RELEASE'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa:2.6.7'Spring Data는 다음과 같은 MongoDB Index를 지원한다.
@Indexed: index를 사용할 field를 명시@CompoundIndex: compound index를 사용할 class를 명시@TextIndexed: text index를 사용할 field를 명시@GeoSpacialIndexed: geospacial indexing을 이용할 field를 명시
위와 같은 annotation을 사용하기 위해서는 document class에 @Document이 적용되어야 한다.
@Indexed
db.collection.createIndex({ field: order})와 같은 역할을 수행한다.
다음과 같은 속성을 설정할 수 있다.
- background: index 생성을 background에서 수행하도록 함, 기본값: false
- direction: index의 sort order를 설정함, 기본값: 오름차순
- expireAfterSeconds: TTL index를 설정함, 기본값: -1
- name: index의 이름을 설정함, 기본값: ""
- sparse: index field를 가진 document만 reference하도록 설정함, 기본값: false
- unique: index field에 중복 값이 불가능하도록 설정함, 기본값: false
- useGeneratedName:
name에서 설정한 이름을 무시하도록 함, 기본값: false - partialFilter: filter 조건을 만족한 document만 index되도록 함, 기본값: ""
- expireAfter:
expireAfterSeconds와 비슷한 기능을 수행, 기본값: ""
@CompoundIndex
db.collection.createIndex({ field1: order1, field2: order2})와 같은 역할을 수행
기본적으로 @Indexed와 같은 속성을 제공한다. 차이점은 다음과 같다.
direction을 다른 방식으로 설정하여 속성으로 제공하지 않음- def: index key와 sort order를 설정함, 기본값: ""
한 Collection에 여러 @CompoundIndex를 사용하려면
@CompoundIndexes안에 @CompoundIndex들을 인자로 넣으면 된다.
Spring에서 MongoDB query 수행 확인하기
Spring에서 MongoDB를 사용하기 위한 방법으로
MongoRepository와 MongoTemplate이 있다.
Spring을 이용해서 MongoDB의 query가 수행하는 것을 확인하고 싶다면
application.properties 또는 application.yml에
logging.level.org.springframework.data.mongodb.core.MongoTemplate: DEBUG
logging.level.org.springframework.data.mongodb.repository.query: debug을 추가하면 query 로그를 확인할 수 있다.
또한 해당 query에서 index가 잘 사용되고 있는지 확인하고 싶다면
앞서 언급했던 세 가지 방법 중 하나를 활용해서 확인하면 된다.
예를 들어 db.collection.aggregate( [ { $indexStats: { } } ] )의 결과에서
accesses: { ops: Long("34") } 수치가 query 수행 전후로 변화하는 지와 같이 확인할 수 있다.
참고
https://www.mongodb.com/
https://docs.spring.io/spring-data/mongodb/docs/2.1.5.RELEASE/reference/html/
https://docs.spring.io/spring-data/mongodb/docs/1.2.0.RELEASE/reference/html/mongo.repositories.html
