재고 시스템을 통해 동시성 문제를 알아보고, 이를 해결해보겠다.
동시성 문제란, 동일한 하나의 데이터에 2 이상의 스레드, 혹은 세션에서 가변 데이터를 동시에 제어할 때 나타는 문제로,
하나의 세션이 데이터를 수정 중일때, 다른 세션에서 수정 전의 데이터를 조회해 로직을 처리함으로써 데이터의 정합성이 깨지는 문제를 말합니다.
아래와 같이 재고 시스템을 만들어서 동시성 문제를 제어해보겠다.
- Stock
@Entity
@Getter
@NoArgsConstructor
public class Stock {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
public Stock(Long productId, Long quantity) {
this.productId = productId;
this.quantity = quantity;
}
public void decrease(Long quantity) {
if (this.quantity - quantity < 0) {
throw new RuntimeException("재고 부족");
}
this.quantity = this.quantity - quantity;
}
}- StockRepository
public interface StockRepository extends JpaRepository<Stock, Long> {
}- StockService
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository stockRepository;
/**
* 재고 감소
*/
@Transactional
public void decrease(final Long id, final Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}일반적인 재고 감소 로직이다.
동시성 문제 발생
- StockServiceTest - 멀티 스레드 환경
@SpringBootTest
class StockServiceTest {
@Autowired
private StockService stockService;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void stock_decrease() {
stockService.decrease(1L, 1L);
Stock stock = stockRepository.findById(1L).orElseThrow();
assertThat(stock.getQuantity()).isEqualTo(99L);
}
@Test
@DisplayName("동시에_100개의_요청")
public void requests_100_AtTheSameTime() throws InterruptedException {
int threadCount = 100;
//멀티스레드 이용 ExecutorService : 비동기를 단순하게 처리할 수 있또록 해주는 java api
ExecutorService executorService = Executors.newFixedThreadPool(32);
//다른 스레드에서 수행이 완료될 때 까지 대기할 수 있도록 도와주는 API - 요청이 끝날때 까지 기다림
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
}
finally {
latch.countDown();
}
});
}
latch.await();//다른 쓰레드에서 수행중인 작업이 완료될때까지 기다려줌
Stock stock = stockRepository.findById(1L).orElseThrow();
//100 - (1*100) = 0
//race condition 이 발생함 동시에 변경하려고 할때 발생하는 문제
//하나의 쓰레드의 작업이 완료되기 이전에 쓰레드가 공유 자원에 접근하였기 떄문에 값이 공유 자원의 값이 다르다.
assertThat(stock.getQuantity()).isEqualTo(0L);
}
}<코드 설명>
- ExecutorService
- 병렬 작업시 여러개의 작업을 효율적으로 처리하기 위한 라이브러리
- 쉽게 ThreadPool을 구성하고 Task 실행
- Executors를 통해 ExecutorService 생성 및 스레드 풀의 개수 및 종류 지정
- CountDownLatch
- 특정 스레드가 작업이 완료될 때까지 기다리게 해주는 클래스
- 멀티 스레드가 100번의 작업이 모두 완료한 후, 테스트를 하도록 기다리게 함
- stockService.decrease(1L, 1L)
- 100개의 스레드가 재고를 1개씩 감소 시키는 decrease()를 병행 수행
- 결과적으로 Stock의 수량은 0
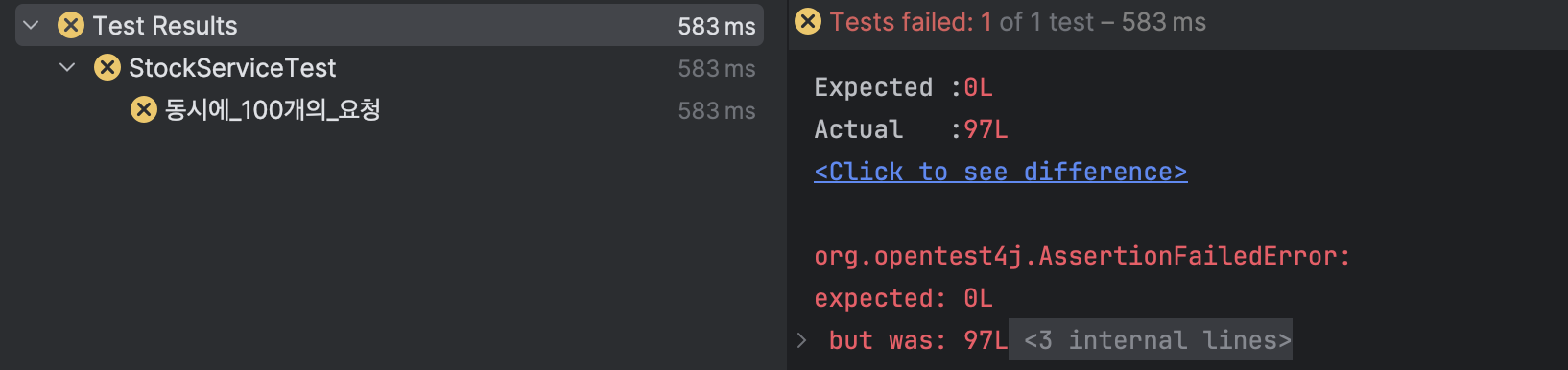
그러나 테스트는 실패한다.
<실패 원인>
- Race Condition(경쟁 상태) 발생
- 공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
- 여기서는 여러 스레드가 공유 데이터에 접근하여 변경하면서 발생한 문제
멀티 스레드 처리 시 Race Condition 발생 이유
<예상 작업 순서>
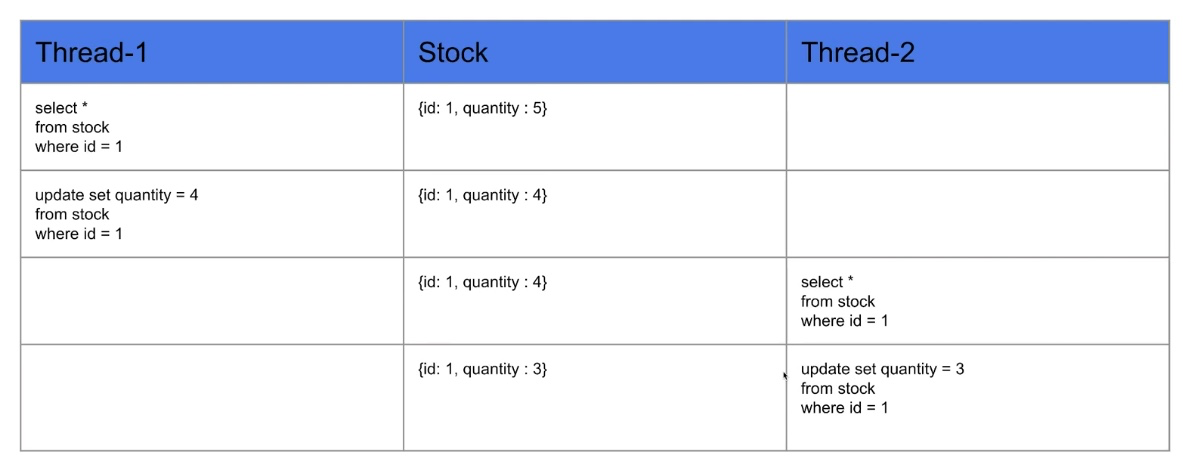
- 1번 스레드에서 재고 감소 후, 2번 스레드에서 조회 및 재고 감소
- 따라서 재고는 3이 됨
<본 테스트에서의 작업 순서>
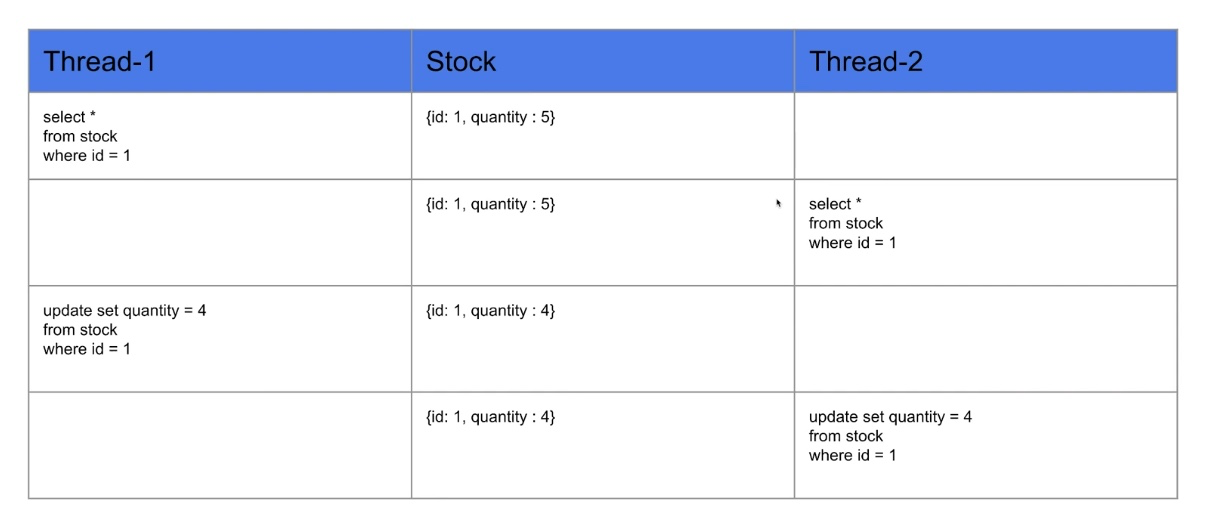
- 1번 스레드에서 조회
- 이어서 2번 스레드에서 조회
- 1번 스레드는 2번이 조회된 후에 재고 감소 -> 재고 4
- 2번 스레드가 재고 감소, 이때 조회해온 재고는 5이므로, 재고 감소시 4
- 결과는 스레드가 두번 재고 감소를 일으키지만 재고는 4가 됨
- 즉, 하나의 작업이 누락됨
Race Condition 해결 방법
Race Condition을 해결하기 위해서는 하나의 스레드가 작업을 완료한 후에, 다른 스레드가 공유된 자원에 접근 가능하도록 해야 한다.
따라서, 이를 해결하기 위해 3가지 해결방법을 적용해본다
1. Java sychronized 동기화
2. DB Lock
- Pesimistic Lock
- Optimistic Lock
- Named Lock
- Redis Lock
- Lettuce Lock
- Redisson Lock
1) Synchronized 이용
Synchronized?
- 스레드 동기화를 위해 자바에서 지원하는 기술
- 하나의 공유자원에 동시에 접근하지 못하도록 막음
- 공유되는 데이터의 Thread-safe를 위해, synchronized 로 스레드간 동기화를 시켜 thread-safe 하게 만들어줌
- @Transactional을 같이 사용하는 경우 동기화 문제가 그대러 발생될 수 있음
- synchronized와 @transactional을 같이 쓰면 안되는 이유
https://kdhyo98.tistory.com/59
- synchronized와 @transactional을 같이 쓰면 안되는 이유
따라서 synchronized는, 현제 데이터를 사용하고 있는 해당 스레드를 제외하고 나머지 스레드들은 데이터 접근을 막아 순차적으로 데이터에 접근할 수 있도록 해준다.
코드는 아래와 같이 수정한다.
- SynchronizedStockService
@Service
@RequiredArgsConstructor
public class SynchronizedStockService {
private final StockRepository stockRepository;
/**
* 재고 감소
*/
public synchronized void decrease(final Long id, final Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}- SynchronizedStockServiceTest
@SpringBootTest
class SynchronizedStockServiceTest{
@Autowired
private SynchronizedStockService synchronizedStockService;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void stock_decrease() {
synchronizedStockService.decrease(1L, 1L);
Stock stock = stockRepository.findById(1L).orElseThrow();
assertThat(stock.getQuantity()).isEqualTo(99L);
}
@Test
@DisplayName("동시에_100개의_요청")
public void requests_100_AtTheSameTime() throws InterruptedException {
int threadCount = 100;
//멀티스레드 이용 ExecutorService : 비동기를 단순하게 처리할 수 있또록 해주는 java api
ExecutorService executorService = Executors.newFixedThreadPool(32);
//다른 스레드에서 수행이 완료될 때 까지 대기할 수 있도록 도와주는 API - 요청이 끝날때 까지 기다림
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
synchronizedStockService.decrease(1L, 1L);
}
finally {
latch.countDown();
}
});
}
latch.await();//다른 쓰레드에서 수행중인 작업이 완료될때까지 기다려줌
Stock stock = stockRepository.findById(1L).orElseThrow();
assertThat(stock.getQuantity()).isEqualTo(0L);
}
}기존 코드에서 @Transactional 제거와 synchornized 키워드만을 수정해주면, 테스트 코드는 그대로 두어도 정상 수행이 된다,

synchronized의 문제점
- 자바의 Sychronized는 하나의 프로세스 안에서만 보장이 됨
- 따라서, 여러 서버에서 해당 공유 자원에 접근시 Sychronized는 원활하게 동작하지 않을 수 있음
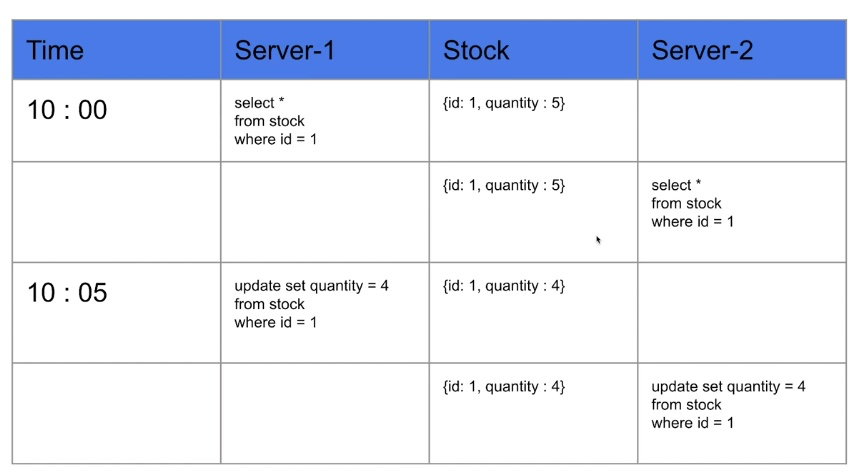
- 위와 같이 서버 1에서 공유자원에 접근하고, 그 이후 서버 2에서 접근하게 되면 이전과 동일하게 Race Condition이 발생한다.
2) DB Lock 이용
1. Pessimistic Lock 사용 하기
Pessimistic Lock(비관적 락) 이란?
- 모든 트랜잭션은 충돌이 발생한다 가정하고 Lock을 거는 방법
- exclusive lock(베타적 잠금)을 걸게되면 다른 트랜잭션에서는 lock 이 해제되기전에 데이터를 가져갈 수 없음.
- 추가적인 트랜잭션과 격리성에 대해(https://sabarada.tistory.com/117)
따라서 Pessimistic Lock을 사용하면
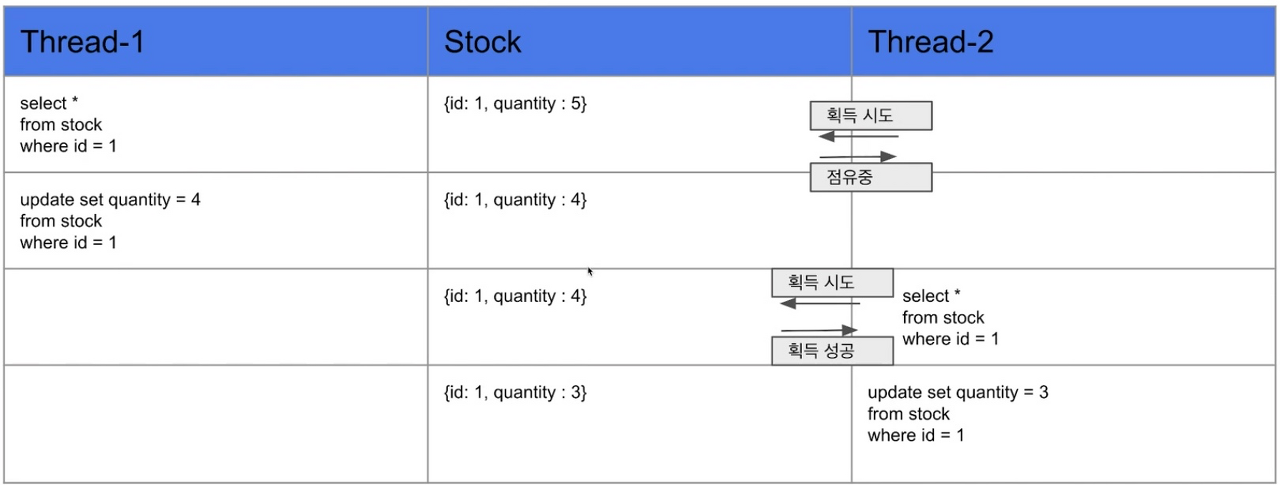
위와 같이 정합성이 맞춰진다.
- PessimisticLockStockService
@Service
@RequiredArgsConstructor
public class PessimisticLockStockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(final Long id, final Long quantity) {
Stock stock = stockRepository.findByWithPessimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}- StockRepository
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByWithPessimisticLock(final Long id);
}- StockService
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(final Long id, final Long quantity) {
Stock stock = stockRepository.findByWithPessimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}- PessimisticLockStockServiceTest
@SpringBootTest
class PessimisticLockStockServiceTest {
@Autowired
private PessimisticLockStockService stockService;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
@DisplayName("Pessimistic LOCK 동시에_100개의_요청")
public void Pessimistic_requests_100_AtTheSameTime() throws InterruptedException {
int threadCount = 100;
//멀티스레드 이용 ExecutorService : 비동기를 단순하게 처리할 수 있또록 해주는 java api
ExecutorService executorService = Executors.newFixedThreadPool(32);
//다른 스레드에서 수행이 완료될 때 까지 대기할 수 있도록 도와주는 API - 요청이 끝날때 까지 기다림
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
}
finally {
latch.countDown();
}
}
);
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
//100 - (1*100) = 0
assertThat(stock.getQuantity()).isEqualTo(0L);
}
}
위와 같이 성공하는 모습을 볼 수 있다.
Pessimistic Lock의 장단점
-
장점
- 충돌이 빈번하게 일어난다면 롤백의 횟수를 줄일 수 있기 때문에, Optimistic Lock 보다는 성능이 좋을 수 있음.
- 비관적 락을 통해 데이터를 제어하기 때문에 데이터 정합성을 보장할 수 있음.
-
단점
- 데이터 자체에 별도의 락을 잡기때문에 동시성이 떨어져 성능저하가 발생할 수 있음
- 특히 읽기가 많이 이루어지는 데이터베이스의 경우에는 손해가 더 큼
- 서로 자원이 필요한 경우, 락이 걸려있으므로 데드락이 일어날 수 있음
(ex: Pessimistic 데드락 예시)
2. Optimistic Lock 사용 하기
Optimistic Lock(낙관적 락) 이란?
- DB Lock을 사용하지 않고, Version 관리를 통해 어플리케이션 레벨에서 처리함
- 대부분의 트랜잭션이 충돌하지 않는다고 가정하는 방법
- JPA가 제공하는 버전 관리기능을 사용
- 트랜잭션 커밋 전에는 트랜잭션 충돌을 알 수 없다.
- 먼저 데이터를 읽은 후에 update를 수행할 때 현재 내가 읽은 버전이 맞는지 확인하며 업데이트
- 자원에 락을 걸어서 선점하지 않고, 동시성 문제가 발생하면 그때가서 처리하는 것
<Optimistic Lock 과정>
1) 서버 1이 version1 임을 조건절에 명시하면서 업데이트 쿼리를 날림
2) version1 쿼리가 업데이트 되어서 디비는 version2가 됨
3) 서버 2가 version1로 업데이트 쿼리를 날리면 버전이 맞지 않아 실패
4) 쿼리가 실패하면 서버2에서 다시 조회하여 버전을 맞춘 후 업데이트 쿼리를 날리는 과정을 거침
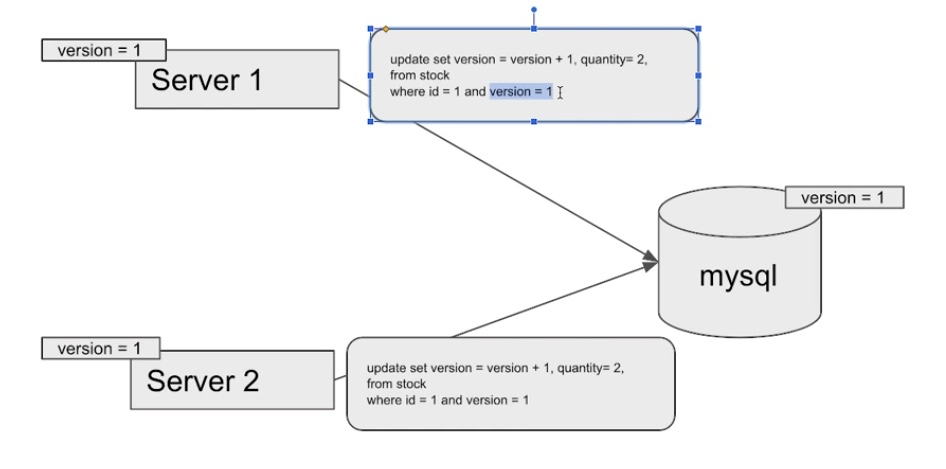
1~2 과정
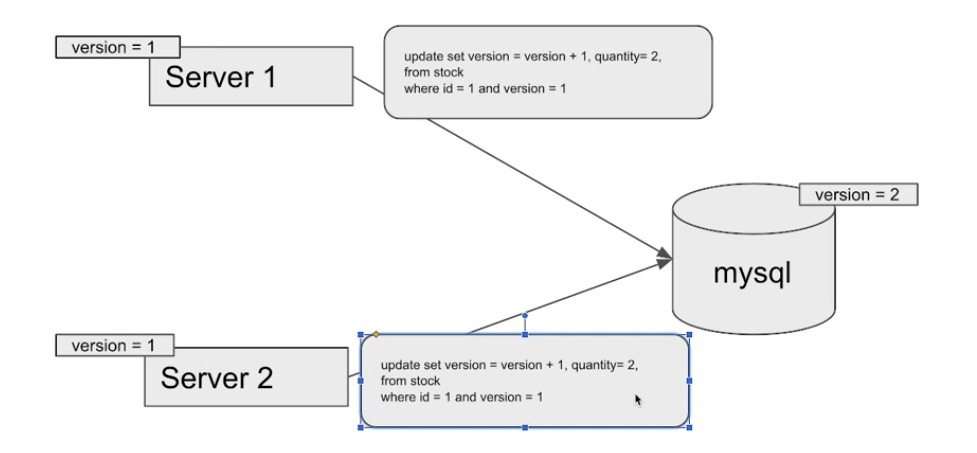
3~4 과정
<Optimistic Lock 점유 과정>

코드에 Optimistic Lock을 적용해보면
- Stock
@Entity
@Getter
@NoArgsConstructor
public class Stock {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
@Version
private Long version;
public Stock(Long productId, Long quantity) {
this.productId = productId;
this.quantity = quantity;
}
public void decrease(Long quantity) {
if (this.quantity - quantity < 0) {
throw new RuntimeException("재고 부족");
}
this.quantity = this.quantity - quantity;
}
}- StockRepository
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByWithPessimisticLock(Long id);
@Lock(value = LockModeType.OPTIMISTIC)
@Query("select s from Stock s where s.id = :id")
Stock findByWithOptimisticLock(Long id);
}- OptimisticLockStockService
@Service
@RequiredArgsConstructor
public class OptimisticLockStockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findByWithOptimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}- OptimisticLockStockFacade
@Service
@RequiredArgsConstructor
public class OptimisticLockStockFacade {
private final OptimisticLockStockService optimisticLockStockService;
public void decrease(Long id, Long quantity) throws InterruptedException {
while (true) {
try {
optimisticLockStockService.decrease(id, quantity);
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}해당 클래스는 여러 스레드가 동시에 접근 시 version 정보가 맞지 않아 exception 이 발생할 경우 재 요청을 하기 위해 존재하는 서비스 클래스이다.
즉, Lock을 어플리케이션 단계에서 해결한다는 의미이다.
기존과 동일하게 테스트 코드를 작성하고 진행시켜보면
- OptimisticLockStockFacadeTest
@DisplayName("낙관적락 재고 선점 테스트")
@SpringBootTest
public class OptimisticLockStockFacadeTest {
@Autowired
private OptimisticLockStockFacade optimisticLockStockFacade;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
void OptimisticLock_동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);//비동기로 실행하는 작업을 단순화하여 사용
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
optimisticLockStockFacade.decrease(1L, 1L);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown();;
}
});
}
latch.await();//다른 쓰레드에서 수행중인 작업이 완료될때까지 기다려줌
Stock stock = stockRepository.findById(1L).orElseThrow();
assertEquals(0L, stock.getQuantity());
}
}
위와 같이 버전 정보를 포함해서 쿼리가 나가고 정상 작동한다.
Optimistic Lock의 장단점
- 장점
- 충돌이 안난다는 가정하에, 별도의 락을 잡지 않으므로 Pessimistic Lock보다 성능이 좋을 수 있다
- 단점
- 업데이트 실패시, 롤백 로직을 개발자가 직접 개발해야함
- 충돌이 빈번하게 일어나면, 롤백처리로 인해 Pessimistic Lock 보다 성능이 안좋을 수도 있음
3. Named Lock 사용 하기
Named Lock 이란?
- 이름을 가진 metadata locking으로, 이름을 가진 lock 을 획득한 후 해제할 때 까지 다른 세션은 이 lock 을 획득할 수 없도록 함
- 트랜잭션이 종료될 때, Lock이 자동 해제되지 않기 때문에 별도의 명령이 필요
📌 Named Lock은 Passimistic Lock 과 유사하지만, Passimistic Lock 은 row 나 table 단위로 락을 걸지만, Named Lock 은 metadata 단위로 락을 건다는 차이점이 존재
<Named Lock 점유 과정>
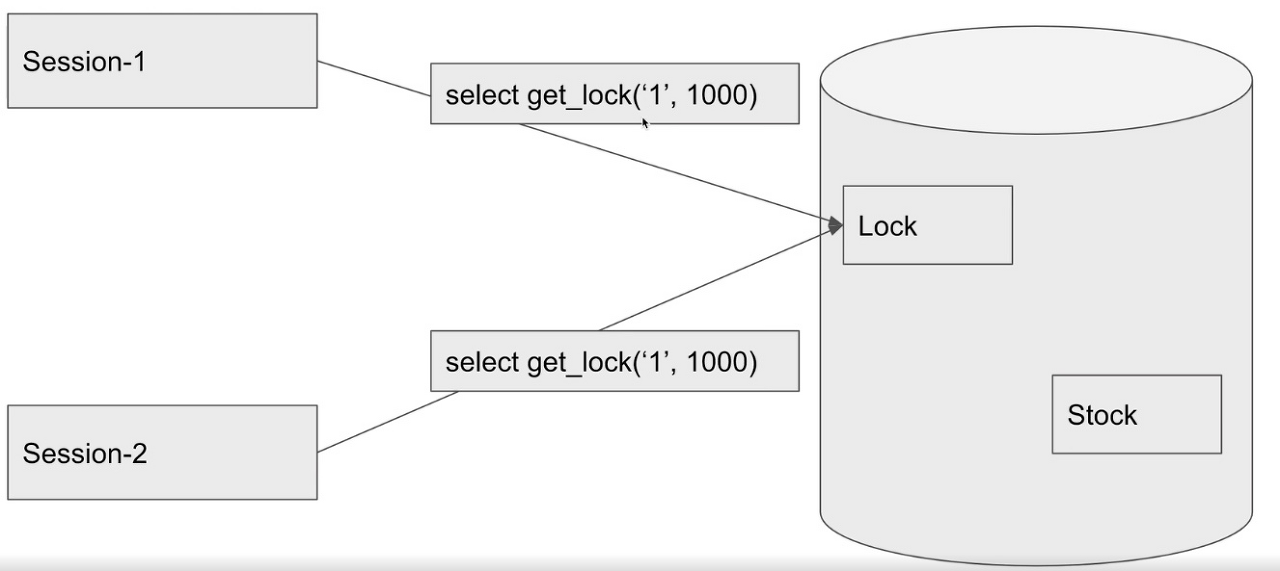
1. Named Lock은 Stock에 락을 걸지 않고, 별도의 공간에 락을 건다
2. session-1 이 1이라는 이름으로 락을 건다면, session 1 이 1을 해지한 후에 락을 얻을 수 있습니다.
- LockRepository
public interface LockRepository extends JpaRepository<Stock, Long> {
@Query(value = "select get_lock(:key, 3000)", nativeQuery = true)
void getLock(String key);
@Query(value = "select release_lock(:key)", nativeQuery = true)
void releaseLock(String key);
}-
예제에서는 편의성을 위해서 Stock 엔티티를 사용하지만, 실무에서는 별도의 JDBC 를 사용해야 한다.
-
NamedLockFacade
@Component
@RequiredArgsConstructor
public class NamedLockFacade {
private final LockRepository lockRepository;
private final NamedLockStockService stockService;
@Transactional
public void decrease(final Long id, final Long quantity) {
try {
lockRepository.getLock(id.toString());
stockService.decrease(id, quantity);
}finally {
//락의 해제
lockRepository.releaseLock(id.toString());
}
}
}실제 로직 실행 전 후로 getLock 과 releaseLock을 수행해야 하기 때문에 Facade 클래스를 생성한다.
lockRepository.getLock(id.toString());을 통해 해당 id의 Named Lock을 획득한다.
lockRepository.releaseLock(id.toString());을 통해 락을 해제한다.
- NamedLockStockService
@Service
@RequiredArgsConstructor
public class NamedLockStockService {
private final StockRepository stockRepository;
/**
* 재고 감소
*/
//부모의 트랜잭션과 별도로 실행되기 위해서 propagation을 수정함
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}- applicaiton.yml
spring:
jpa:
hibernate:
ddl-auto: create
show-sql: true
properties:
hibernate:
# show_sql: true
# format_sql: true
dialect: org.hibernate.dialect.MySQL8Dialect
datasource:
# url: jdbc:h2:tcp://localhost/~/test
# username: sa
# password:
# driver-class-name: org.h2.Driver
url: jdbc:mysql://localhost:3306/concurrent?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul
username: root
password: ch122411
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 40DataSource 를 사용해주어야하기 때문에 커넥션 풀 수를 늘려주어야 한다
이제 테스트 코드 작성하고 실행해보겠다.
- NamedLockStockFacadeTest
@SpringBootTest
class NamedLockStockFacadeTest {
@Autowired
private NamedLockFacade namedLockFacade;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void 동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
namedLockFacade.decrease(1L, 1L);
System.out.println("남은 재고 : " + stockRepository.findById(1L).orElseThrow().getQuantity());
} finally {
{
latch.countDown();
}
}
});
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
// 100 - (1 * 100) = 0
assertEquals(0L, stock.getQuantity());
}
쿼리문을 보면 lock을 얻고, 해제하는 과정을 반복한다.
Named Lock의 장단점
- 장점
- NamedLock 은 주로 분산락을 구현할 때 사용
- Pessimistic 락은 time out을 구현하기 굉장히 힘들지만, Named Lock은 비교적 손쉽게 구현할 수 있음
- 단점
- Naemd Lock 은 트랜잭션 종료 시에, 락 해제와 세션관리를 해야함
- 실제 사용할 때는 구현방법이, 복잡할 수 있음
3) Redis 사용하기
1. Lettuce
Lettuce 란?
- Setnx 명령어를 활용하여 분산락을 구현 (Set if not Exist - key:value를 Set 할 떄. 기존의 값이 없을 때만 Set 하는 명령어)
- Setnx 는 Spin Lock방식이므로 retry 로직을 개발자가 작성해야함
- Spin Lock 이란, Lock 을 획득하려는 스레드가 Lock을 획득할 수 있는지 확인하면서 반복적으로 시도하는 방법
<Spin Lock 과정>
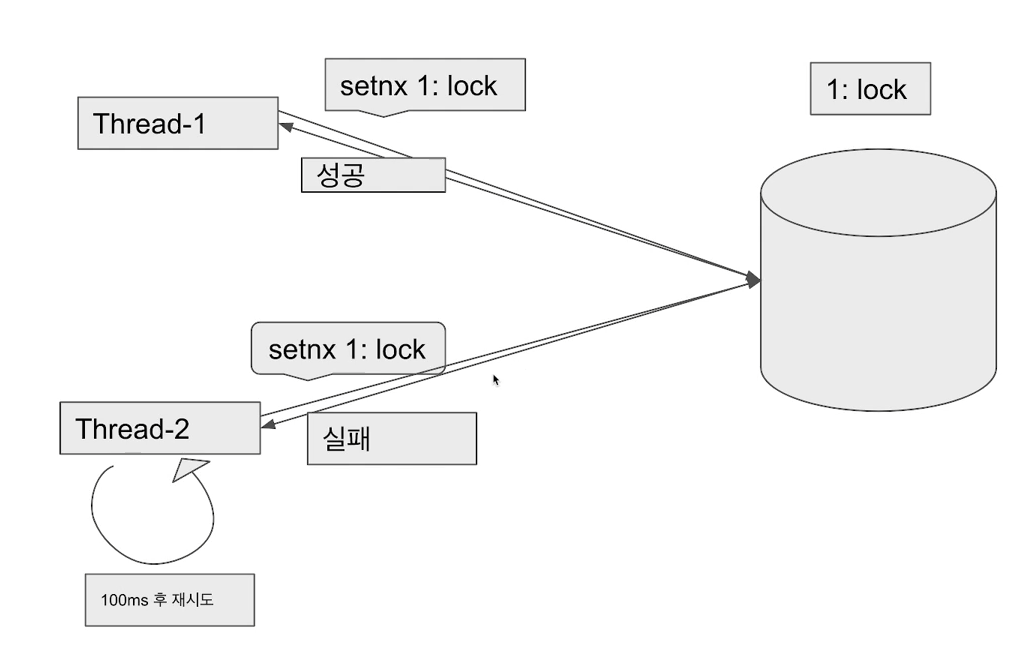
1. 쓰레드1이 키가 1인 데이터를 레디스에 set하면 처음엔 1이 없으므로 성공한다.
2. 쓰레드2가 키가 1인 데이터를 set하려 하면 1이 이미 있으므로 실패한다.
3. 성공을 위해 100ms마다 재시도하는 로직을 작성해서 성공할 때 까지 시도한다.
이제 Lettuce로 락을 구현해보자
우선 Redis 의존성을 설치한다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'- RedisLockRepository
@Component
public class RedisLockRepository {
private RedisTemplate<String, String> redisTemplate;
public RedisLockRepository(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public Boolean lock(Long key) {
return redisTemplate
.opsForValue()
.setIfAbsent(generateKey(key), "lock", Duration.ofMillis(3_000));
}
public Boolean unlock(Long key) {
return redisTemplate.delete(generateKey(key));
}
public String generateKey(Long key) {
return key.toString();
}
}- LettuceLockStockFacade
@Component
public class LettuceLockStockFacade {
private RedisLockRepository redisLockRepository;
private StockService stockService;
public LettuceLockStockFacade(RedisLockRepository redisLockRepository, StockService stockService) {
this.redisLockRepository = redisLockRepository;
this.stockService = stockService;
}
public void decrease(Long key, Long quantity) throws InterruptedException {
while (!redisLockRepository.lock(key)) {
Thread.sleep(100);
}
try {
stockService.decrease(key, quantity);
} finally {
redisLockRepository.unlock(key);
}
}
}로직 실행 전 후로 Lock 획득과 해제를 수행해야 하므로 Facade 클래스를 추가한다.
1. SpinLock 방식으로 락을 얻기를 시도하고,
2. 락을 얻은 후, 재고 감소 비지니스 로직을 처리합니다.
3. 그 후, 락을 해제해준다.
- LettuceLockStockFacadeTest
@SpringBootTest
class LettuceLockStockFacadeTest {
@Autowired
private LettuceLockStockFacade lettuceLockStockFacade;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void 동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
lettuceLockStockFacade.decrease(1L, 1L);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
{
latch.countDown();
}
}
});
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
// 100 - (1 * 100) = 0
assertEquals(0L, stock.getQuantity());
}
}구현이 간단하다는 장점이 있지만, Spin Lock 방식이, Lock 을 얻을 때까지 Lock 얻기를 시도하기 떄문에, 계속해서 Redis 에 접근해서 Redis에 부하를 줄 수 있다는 단점이 존재한다.
2. Redisson 사용하기
Redission 이란?
- Pub-sub 기반으로 Lock 구현 제공
- Pub-Sub 방식이란, 채널을 하나 만들고, 락을 점유중인 스레드가, 락을 해제했음을, 대기중인 스레드에게 알려주면 대기중인 스레드가 락 점유를 시도하는 방식
- 이 방식은, Lettuce와 다르게 대부분 별도의 Retry 방식을 작성하지 않아도 됨
<Pub-Sub 과정>

- Redisson 라이브러리 설치
implementation 'org.redisson:redisson-spring-boot-starter:3.17.4'redisson은 lock 관련 클래스를 제공해주기 때문에 repository는 필요없다.
하지만 lock 획득, 해제는 직접 작성해야 하므로 facade 클래스를 생성한다.
- RedissonLockStockFacade
@Component
@RequiredArgsConstructor
public class RedissonLockStockFacade {
private RedissonClient redissonClient;
private StockService stockService;
public RedissonLockStockFacade(RedissonClient redissonClient, StockService stockService) {
this.redissonClient = redissonClient;
this.stockService = stockService;
}
public void decrease(Long key, Long quantity) {
RLock lock = redissonClient.getLock(key.toString());
try {
boolean available = lock.tryLock(20, 1, TimeUnit.SECONDS);
if (!available) {
System.out.println("lock 획득 실패!");
return;
}
stockService.decrease(key, quantity);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
}- RedissonLockStockFacadeTest
@SpringBootTest
class RedissonLockStockFacadeTest {
@Autowired
private RedissonLockStockFacade redissonLockStockFacade;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void after() {
stockRepository.deleteAll();
}
@Test
public void 동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
redissonLockStockFacade.decrease(1L, 1L);
} finally {
{
latch.countDown();
}
}
});
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
// 100 - (1 * 100) = 0
assertEquals(0L, stock.getQuantity());
}
}Lettuce와 Redisson의 비교
- Lettuce
구현이 간단하다
spring data redis를 이용하면 lettuce가 기본이기 때문에 별도의 라이브러리를 사용하지 않아도 된다.
spin lock 방식이기 때문에 동시에 많은 스레드가 lock 획득 대기 상태라면 redis에 부하가 갈 수 있다.
- Redisson
lock 획득 재시도를 기본으로 제공한다.
pub-sub방식으로 구현되어 있기 때문에 lettuce 대비 redis에 부하가 덜 간다.
별도 라이브러리를 사용해야 한다.
lock을 라이브러리 차원에서 제공하기 때문에 사용법을 공부해야한다.
실무에서는
-
재시도가 필요하지 않은 lock은 lettuce활용
-
재시도가 필요한 경우에는 redisson 활용
Mysql과 Redis 비교
- Mysql
이미 Mysql을 사용하고 있다면 별도의 비용없이 사용 가능하다.
어느정도의 트래픽까지는 문제 없이 활용이 가능하다.
Redis보다 성능이 좋지 않다
- Redis
활용중인 Redis가 없다면 별도의 구축비용과 인프라 관리비용이 발생한다.
Mysql보다 성능이 좋다.
참고
https://devhooney.tistory.com/110
https://thalals.tistory.com/370#google_vignette
https://everydayyy.tistory.com/167
https://velog.io/@hyojhand/named-lock-distributed-lock-with-redis(Named Lock, Redis)
https://dkswnkk.tistory.com/681
