🎯 필자는
Plating의 소프트웨어 엔지니어로 근무 중 (2019년 작성) 사내 커뮤니케이션 툴로telegram을 이용한다. 저희 고객사는 미리 제공된 페이지를 통해 매일 메뉴를 선택하고 주문을 한다. 마감시간이 되면 페이지에 접근해 오늘의 주문수량을 확인하여 음식을 준비한다. 미리 만들어진telegram bot을 통해 약속된 명령어로 원하는 정보를 간편하게 받아 볼 수 있다면 더욱 효율적일 것이라고 생각한다. 본 포스팅에서 언급된 솔류션에 주 역할을 한 기술을 소개하려 한다.
🤔 왜 Puppeteer 선택했나?
가장 간단한 이유는 플레이팅에서는 고객사에게 제공한 주문 페이지가 SPA이기 때문이다. React.js로 구현된 페이지는 동적으로 render 함수가 JSX(더 자세히) 코드를 반환하여 DOM이 그려지는 특징이 있다. 원활한 스크래핑을 하려면 페이지가 전부 render 된 후에 진행되어야 DOM의 element를 선택하는데 오차가 발생하지 않을 것이다. 즉, 브라우저가 페이지를 접근한 후에 결과값에 접근하고자 한다.
🤓 다른 Use case, 다른 option 추천
리서치 중 굉장히 퍼포먼스가 괜찮은 Js 스크래퍼(a.k.a Parser)들을 발견했다.
독자 중, SPA가 아닌, 즉, 브라우저가 접근한 후의 결과를 스크래핑 하는 것이 아닌 유즈 케이스라면 아래 옵션을 추천한다:
-
👆 Cheerio
Cheerio는 마크업를 파싱하고 결과 데이터를 조작하기 위한 API를 제공한다. 웹 브라우저의 결과를 해석하지 않는다. 구체적으로는 시각적 렌더링이나, CSS 적용이나, 외부 자원을 로딩하거나, 자바스크립트를 실행하지 않는다. 단점으로는 jQuery 라이브러리를 활용해 디펜던시의 용량이 조금 나간다.
-
✌ osmosis
Osmosis은 검색도 빠르고 파싱하는 속도가 상당하다. 장점 중, 스스로 Cheerio랑 비교해 용량이 가볍다고 자랑한다.
🤨 Puppeteer는 뭐지?
아무리 간편한 프로그램을 구현하더라도 뛰어들기 전에 사용하는 기술이 무엇이고 왜 존재하는지를 이해하는 것이 중요하다.
Puppeteer는 구글 크롬의 DevTools Protocol을 통해 Chrome 또는 Chromium을 제어하기 위한 API를 제공하는 node.js 모듈이다. 다양한 기능이 있지만 가장 큰 특징은 Headless browser라는 점 입니다.
Headless browser 📌
Puppeteer는 Chromium이 포함되어 있고, 기본적으로 "Head가 없는" 상태로 실행된다. "머리 없는 브라우저"란? 쉽게 말해 Headless browser는 UI 없이 간편하게 백그라운드에서 실행되는 브라우저다. 실제로 브라우저 창을 띄우지 않고 백그라운드에서 가상으로 진행되며 특정 페이지에 접속하고 렌더링 되는 과정 후 수행하고자 하는 코드를 수행하는데 용이하다. (예를 들어 GUI가 없는 Ubuntu 서버환경에서 용이할 수 있을 것이다.)
API 📌
Headless browser라는 것은 훌륭하고 용이하여 좋지만, 때로는 사용하기에는 어려움이 많을 때도 있다. Puppeteer는 생각보다 유용한 문제를 해결하기 위해 꽤 좋은 괜찮은 기능들을 제공하는 API다.
🏆 Puppeteer: 주요 기능
기본적인 웹 스크래핑/크롤링 업무 이외에 꽤 유용할 것 같은 기능을 제공한다:
- 웹 페이지에서 자동화된 테스트를 실행. JavaScript 테스트를 최신 버전의 Chrome에서 직접 수행할 수 있습니다.
- 사이트의 timeline trace 를 기록하여 성능 문제를 진단할 수 있습니다.
- Chrome Extensions을 테스트 할 수 있습니다.
- PDF 생성
- 스크린샷 찍기
- 지루한 작업 자동화. Form Submit, UI 테스트, 키보드 입력 등을 자동화 합니다.
- 웹 사이트에서 데이터를 가져와 저장
SPA(Single-Page Application)를 크롤링하고 미리 렌더링된 컨텐츠 (SSR- Server Side Rendering)를 생성 할 수 있습니다.
🎖 Puppeter: 간단한 예제 (exampleScrapper.js)
📝 프로젝트: Setup
- 폴더 만들기(원하는 이름으로)
- 터미널/명령 프롬프트에서 폴더 열기
- 터미널 실행에서
npm init -y패키지를 생성한다. 프로젝트 dependency 관리를 위한package.json파일을 생성할 것이다. - 터미널에서
npm i puppeteer실행하여 Puppeteer 설치. (Chromium을 포함한 버전이다, 용량이 조금 나갈수 있다. Chromium 불포함 버전:npm i puppeteer-core) - 마지막으로 좋아하는 코드 편집기에서 폴더를 열고
예제1:exampleScrapper.js파일을 생성한다. 포스팅의 예제를 정확히 따른다면:Docs폴더도 생성한다.예제2:grabData.js파일을 생성한다.
⌨ 프로젝트: Code
이제 설정이 작동하고 있는지 확인하기 위해 간단하게 코드를 작성하고 테스트를 시도해 보자.
🙋♂️ 예제1: exampleScrapper.js
작성할 프로그램은 이렇다:
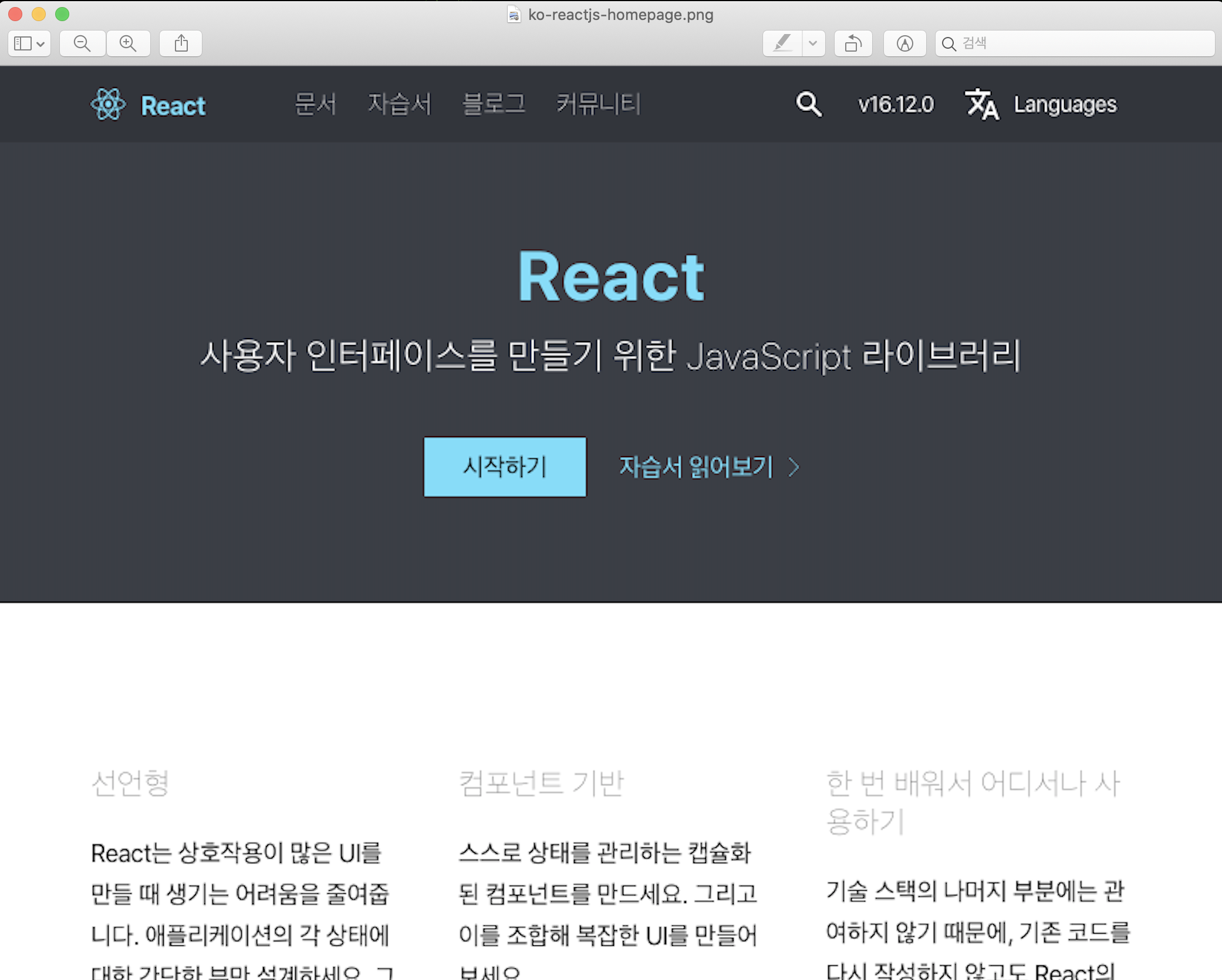
1. https://ko.reactjs.org/ URL에 접속
2. ko-reactjs-homepage.png 스크린샷을 캡처 하여 Docs 폴더에 저장
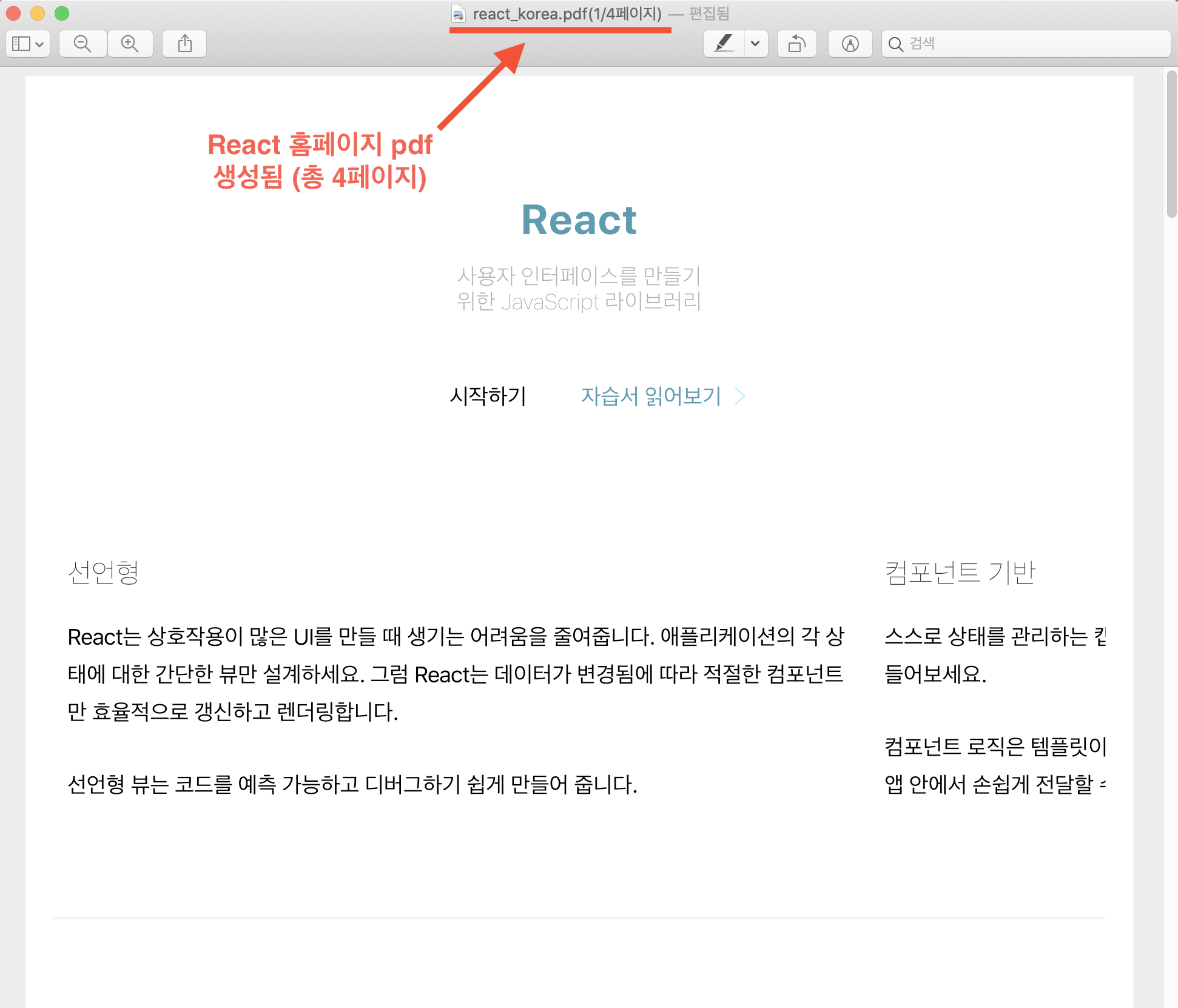
3. react_korea.pdf pdf 파일을 생성하여 Docs 폴더에 저장
코드가 생각보다 간결하다, 놀라지 마라 :)
// 설치된 puppeteer 모듈
const puppeteer = require("puppeteer");
(async () => {
// headless 브라우저 실행
const browser = await puppeteer.launch();
// 새로운 페이지 열기
const page = await browser.newPage();
// `https://ko.reactjs.org/` URL에 접속
await page.goto("https://ko.reactjs.org/");
// `ko-reactjs-homepage.png` 스크린샷을 캡처 하여 Docs 폴더에 저장
await page.screenshot({ path: "./Docs/ko-reactjs-homepage.png" });
// `react_korea.pdf` pdf 파일을 생성하여 Docs 폴더에 저장
await page.pdf({ path: "./Docs/react_korea.pdf", format: "A4" });
/****************
* 원하는 작업 수행 *
****************/
// 모든 스크래핑 작업을 마치고 브라우저 닫기
await browser.close();
})();터미널에서 실행:
node exampleScrapper.js
🙆♂️ 결과1: ./Docs/
- 스크린샷:
ko-reactjs-homepage.png
- pdf파일:
react_korea.pdf
🙋♀️ 예제2: grabData.js
작성할 프로그램은 이렇다:
1. https://en.wikipedia.org/wiki/React_(web_framework) URL에 접속
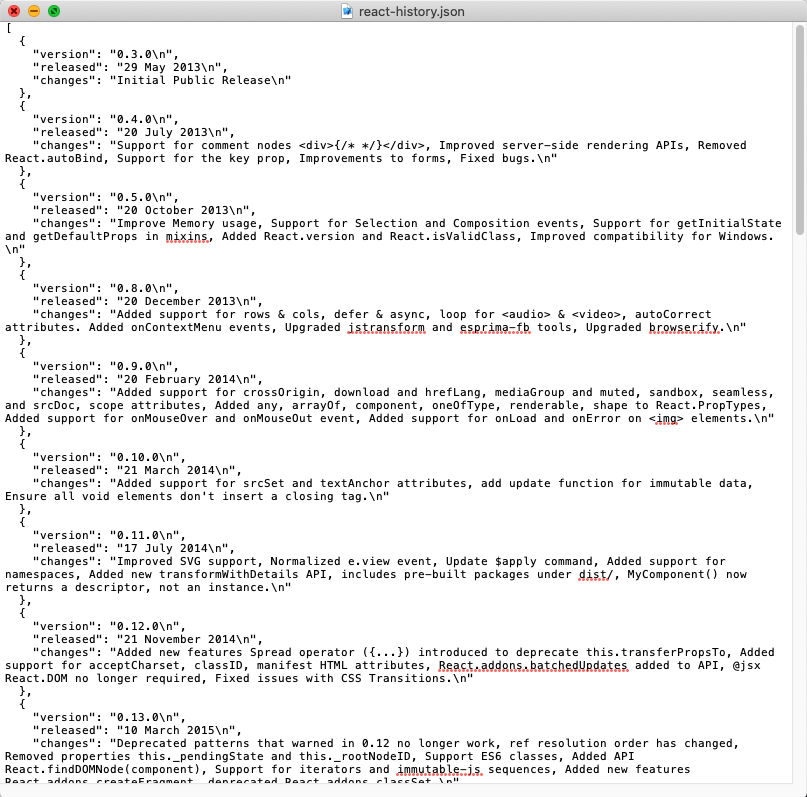
2. 페이지 중간쯤 'History' 관련 테이블의 데이터를 스크래핑하여 json 파일로 저장:
1. 사전에 페이지에 접속하여 개발자 모드(맥:cmd+option+I 윈도우:ctrl+alt+I)를 키고 접근할 element를 확인한다
2. DOM selector로 원하는 정보 element의 자식 노드를 받아서 반복문을 통해 선언된 빈 객체에 push한다.
3. 스크래핑 및 반복문의 결과값을 reactHistory 변수에 할당하고 file system 모듈로 json 형식으로 파일을 생성한다
이번에도 놀라지 마라 :)
페이지 로딩 후 evaluate() 함수는 javascript 코드를 DOM 컨텍스트에서 실행 가능하게 하고 변수 전달도 가능하다
const puppeteer = require("puppeteer"); // 설치된 puppeteer 모듈
(async () => {
const browser = await puppeteer.launch(); // headless 브라우저 실행
const page = await browser.newPage(); // 새로운 페이지 열기
// `https://en.wikipedia.org/wiki/React_(web_framework)` URL에 접속
await page.goto("https://en.wikipedia.org/wiki/react_(web_framework)");
// evaluate() 함수를 이용해 History table을 선택하고 반복문으로 내용을 빈배열에 추가한다
const reactHistory = await page.evaluate(() => {
let scrappedData = []; // 스크래핑 내용 담을 빈 배열
const tbodyChilds = document.querySelector(".wikitable").childNodes[3].children; // history 테이블의 <tbody> 내용
// 반복문으로 <tbody> 내용 객체 형식으로 빈 배열에 추가
for (let i = 1; i < tbodyChilds.length; i++) {
scrappedData.push({
version: tbodyChilds[i].children[0].textContent,
released: tbodyChilds[i].children[1].textContent,
changes: tbodyChilds[i].children[2].textContent
});
}
return scrappedData;
});
const fs = require("fs"); // 내장된 `file system` 모듈
// 스크래핑된 내용 json 파일로 원하는 경로에 생성
fs.writeFile("./Docs/react-history.json",
JSON.stringify(reactHistory, null, 2),
err =>
err? console.error("!!Failed writing file", err)
: console.log("Successfuly file created!")
);
// 모든 스크래핑 작업을 마치고 브라우저 닫기
await browser.close();
})();터미널에서 실행:
node grabData.js
🙆♀️ 결과2: ./Docs/
- json 파일:
react-history.json
본 포스팅에서
Puppeteer해더리스 스크래퍼의 기본적인 기능들이였다
이외에 활용할 수 있는 부분이 많기에 공식 문서를 참고하길 바란다
🙏 긴 글 읽어주셔서 감사합니다!
오타, 잘못된 개념, 의견공유 언제든 환영입니다 🖖

감사합니다. 해보려고 계획 중이였는데 공유 감사합니다 ㅎㅎ