Best practices for creating training data | AutoML Tables | Google Cloud
Q13. Strategies to prevent Overfitting
You have trained a
deep neural network model on Google Cloud. The model haslow loss on the training data, but is performing worse on the validation data. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- ❌ A. Apply a dropout parameter of 0.2, and
decrease the learning rate by a factor of 10.
→ Decrease the lr might training process slower and force the model to go though more epochs than necessary thus memorizing (overfitting) and not generalizing- ❌ B. Apply a L2 regularization parameter of 0.4, and
decrease the learning rate by a factor of 10.- ⭕ C. Run a hyperparameter tuning job on AI Platform to optimize for the L2 regularization and dropout parameters.
- ❌ D. Run a hyperparameter tuning job on AI Platform to optimize for the learning rate, and
increase the number of neurons by a factor of 2.
→ Increasing the num of neurons model larger and converge faster but easily start overfitting
→ TO RESOLVE THE OVERFITTING PROBLEM, BETTER TO REDUCE THE CAPACITY OF THE NETWORK : SMALLER NETWORK
| Regularization |
|---|
| 정규화 없이도 모델이 예측할 수 있는 지 확인한 후, 과적합 문제가 확인되는 경우에만 Regularization 정규화한다. 선형 모델과 비선형 모델은 정규화 방법이 다르다. |
| (1) linear model 선형모델 정규화 |
→ 모델의 size 크기를 줄이기 위해 : L1 regularization |
→ 모델의 stability 안정성을 높이기 위해 : L2 regularization (model's stability makes your model training more reproducible) |
| → regularization rate starting from 1e-5 적절한 값을 찾는다. |
(2) Deep neural network model 정규화 : Dropout regularization 고정된 비율의 뉴런 랜덤으로 삭제 removes a random selection of a fixed percentage of the neurons in a network layer for a single gradient step. Dropout has a similar effect to L2 regularization. |
| → Dropout rate : between 10% and 50% |
| Strategies to prevent overfitting |
|---|
| Get more training data. (The best) 더 많은 데이터에서 학습한 모델이 일반화 성능이 더 좋다. |
| Reduce the capacity of the network. ⇒ Start with a small model = with a small number of learnable parameters determined by the number of layers and the number of units per layer (The simplest) 모델 규모를 축소 = 학습 가능한 파라미터 수를 줄인다. model's capacity⇒memorization capacity 모델의 파라미터는 nn의 경우 LAYER의 수와 LAYER UNIT의 개수에 의해 결정되고, |
→ (1) 모델의 복잡도 (Tiny < Small < Medium < Large)에 따른 Loss 변화 차이 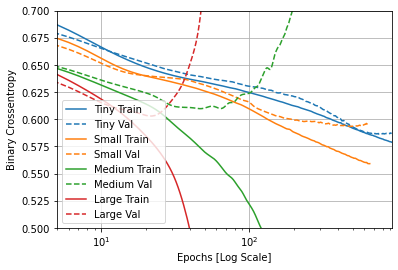 Large 첫 번째 에포크 이후 과대적합 시작, 큰 모델일수록 더 빠르게 Loss를 감소시키며 훈련 세트를 학습시킬 수 있지만 쉽게 과적함됨을 확인할 수 있다. (Large Train vs Large Val) Large 첫 번째 에포크 이후 과대적합 시작, 큰 모델일수록 더 빠르게 Loss를 감소시키며 훈련 세트를 학습시킬 수 있지만 쉽게 과적함됨을 확인할 수 있다. (Large Train vs Large Val) |
| Add weight regularization : Placing constraints on the quantity and type of information your model can store. 정규화는 모델이 저장하는 정보의 양과 유형에 제약을 부과함으로써, 모델이 적은 수의 패턴을 기억해 최적화 과정동안 일반화 가능성이 높은 중요한 패턴에 초점 두고 학습하도록 만든다. |
| Add dropout. |
| Appropriate number of epochs 모델을 너무 오래 훈련하면 과적합될 수 있다. |
| Batch normalization |
| Learning Rate : Since the learning rate is the speed with which we move down the loss gradient, decreasing it will make this rate slower and force the model to go though more epochs than necessary thus memorizing (overfitting) and not generalizing. |
For me answer A is only partially correct. Although, while dropout layers come to mind when talking about overfitting, decreasing the learning rate by a factor of 10 is
1) too much of an increase for one single change, having in mind learning rates are between 0.01 and 0.0001 and
2) we might actually have to increase the learning rate and not decrease it.
Since the learning rate is the speed with which we move down the loss gradient, decreasing it will make this rate slower and force the model to go though more epochs than necessary thus memorizing (overfitting) and not generalizing.
Another thing that points me to answer C is the fact dropout layers are not the ultimate solution. We might be happy with the predictive power of all our features (thus we dont need to drop neurons and features) and want to minimize the effect of some features with L2 (whilst keeping all the features ).
Should be A.
1. It's a DNN, so there are more than 2 layers. An overfit with more layers usually means many layers of it is not necessary.
2. Dropout works brilliantly in most case.
3. L2 regularization is fine, but the parameter of it shouldn't be something to optimize with.
4. Same goes with the learning rate. The question didn't mention anything about if the model is converging fast or slow, so learning rate shouldn't be considered here.
To sum up, I choose A since it's the only one I'm sure would work in some extent.
How do you know dropout rate =0.2 and learning rate / 10 will work though? You can't know the optimal values in advance so you have to try different values using an hyperparameter tuning job, so C is correct
increasing the size of the network will make the overfitting situation worse
Q14,
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial, because the production model is required to keep up with market changes. Since being deployed to production, the model hasn't changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady decline in model accuracy?
- ❌ A. Poor data quality
- ⭕ B. Lack of model retraining
→ Retraining is needed as the market is changing.- C. Too few layers in the model for capturing information
- ❌ D. Incorrect data split ratio during model training, evaluation, validation, and test
B. .
I also think it is B - who is giving the "correct" answers to the questions? I feel like 4 out of 5 of them are incorrect.
B
examtopics says D.Please add annotation why its D ?
Certain that is B
B, obviously.
Q15 Input Image data pipeline - low latency & not fit in memory problem
You have been asked to develop an input pipeline for an ML training model that processes images from disparate sources at a low latency. You discover that your input data does not fit in memory. How should you create a dataset following Google-recommended best practices?
- A. Create a
tf.data.Dataset.prefetchtransformation.- ❌ B. Convert the images to
tf.Tensorobjects, and then runDataset.from_tensor_slices().
→ tf.data.Dataset` is for IN-MEMORY- ❌ C. Convert the images to
tf.Tensorobjects, and then runtf.data.Dataset.from_tensors().
→ tf.data.Dataset` is for IN-MEMORY- ⭕ D. Convert the images into
TFRecords, store the images inCloud Storage, and then use thetf.dataAPI to read the images for training.
-
tf.data.Datasetis for data in memory. -
tf.data.TFRecordDatasetis for data in non-memory storage.
Summary of the best practices for designing performant TensorFlow input pipelines
- Use the
prefetchtransformation to overlap the work of a producer and consumer - Parallelize the data reading transformation using the
interleavetransformation - Parallelize the
maptransformation by setting thenum_parallel_callsargument - Use the
cachetransformation to cache data in memory during the first epoch - Vectorize user-defined functions passed in to the
maptransformation - Reduce memory usage when applying the
interleave,prefetch, andshuffletransformations
Q 16. Difference between CNNs and RNNs
You are an ML engineer at a large grocery retailer with stores in multiple regions. You have been asked to create an inventory prediction model. Your model's features include
region, location, historical demand, and seasonal popularity. You want the algorithm to learn from new inventory data on a daily basis. Which algorithms should you use to build the model?
- ❌ A. Classification
- ❌ B. Reinforcement Learning
→ Reinforcement Learning is basically agent - task problems.- ⭕ C. Recurrent Neural Networks (RNN)
→ RNN is the "Preferred algorithm for sequential data like time series, speech, text, financial data, audio, video, weather and much more" since "It learns over time what information is important and what is not" because they "can remember important things about the input they received, which allows them to be very precise in predicting what’s coming next".- ❌ D. Convolutional Neural Networks (CNN)
[EXAMTOPIC Q17-Q20](EXAMTOPIC Q17-Q20
Q17.
You are building a real-time prediction engine that streams files which may contain Personally Identifiable Information (PII) to Google Cloud. You want to use the Cloud Data Loss Prevention (DLP) API to scan the files. How should you ensure that the PII is not accessible by unauthorized individuals?
- ❌ A. Stream all files to Google Cloud, and then write the data to BigQuery. Periodically conduct a bulk scan of the table using the
DLP API.- ❌ B. Stream all files to Google Cloud, and write batches of the data to BigQuery. While the data is being written to BigQuery, conduct a bulk scan of the data using the
DLP API.- ❌ C. Create two buckets of data: Sensitive and Non-sensitive. Write all data to the Non-sensitive bucket. Periodically conduct a bulk scan of that bucket using the
DLP API, and move the sensitive data to the Sensitive bucket.
→ To ensure that the PII is not accessible by unauthorized individuals, _REQUIREQuarantine bucket,Sensitive bucket: Limited access policy.
→ _WRITING ALL THE DATA toNon-sensitive bucket- ANYONE CAN HAVE ACCESS to it : Risky- ⭕ D. Create three buckets of data: Quarantine, Sensitive, and Non-sensitive. Write all data to the Quarantine bucket. Periodically conduct a bulk scan of that bucket using the
DLP API, and move the data to either the Sensitive or Non-Sensitive bucket.
| Data classification and management - Data loss prevention |
|---|
Cloud DLP for a powerful data inspection, classification, and de-identification platform : SCAN DATA & CREATES DATA CATALOG TAGS to identify sensitive data. |
| ✔ Used on existing BigQuery tables, Cloud Storage buckets, or on data streams. |
| ✔ Over one hundred predefined detectors to identify patterns, formats, and checksums. |
| ✔ Can create custom detectors using a dictionary or a regular expression or can add 'Hotword' rules to increase the accuracy of findings and set exclusion rules to reduce the number of false positives. |
| ✔ Provides a set of tools to de-identify your data, including masking, tokenization, pseudonymization, date shifting, and more. |
Using Cloud DLP leads to better data governance by helping you to classify your data and give the right access to the right people. |
| Ingest data into a quarantine bucket ( 1 of the 3 BUCKETS) |
→ Write all data to the [QUARANTINE_BUCKET] |
Run Cloud DLP to identify PII. (Done by scanning the entire dataset or by sampling the data.) : DLP API called from the transform steps of pipeline or from stand alone scripts Cloud Functions. |
→ Periodically conduct a bulk scan of that bucket using the DLP API |
| Move the data to the warehouse. |
→ either [SENSITIVE_DATA_BUCKET] or [NON_SENSITIVE_DATA_BUCKET] |
Q18.
You work for a large hotel chain and have been asked to assist the marketing team in gathering predictions for a targeted marketing strategy. You need to make predictions about user lifetime value (LTV) over the next 20 days so that marketing can be adjusted accordingly. The customer dataset is in
BigQuery, and you are preparing the tabular data for training withAutoML Tables. This data has a time signal that is spread across multiple columns. How should you ensure thatAutoMLfits the best model to your data?
- ❌ A.
Manually combine all columns that contain a time signal into an array. Allow AutoML to interpret this array appropriately. Choose an automatic data split across the training, validation, and testing sets.
→ NOT ARRAY, DATA TYPE SHOULD BE TIMESTAMP- ❌ B. Submit the data for training without performing any manual transformations. Allow AutoML to handle the appropriate transformations. Choose an automatic data split across the training, validation, and testing sets.
→ TO USE TIME COLUMN APPROACH FOR SPLITING DATA, SHOULD SELECT APPROPRIATE COLUMNS FOR TIME & ENSURE THAT APPROPRIATE DATATYPE & ENOUGH UNIQUE VALUES- C. Submit the data for training
without performing any manual transformations, and indicate an appropriate column as the Time column. Allow AutoML to split your data based on the time signal provided, and reserve the more recent data for the validation and testing sets.- ⭕ D. Submit the data for training without performing any manual transformations. Use the columns that have a time signal to manually split your data. Ensure that the data in your validation set is from 30 days after the data in your training set and that the data in your testing sets from 30 days after your validation set.
→ PROVIDING A TIME SIGNAL : If the time information is not contained in a single column, you can use a manual data split to use the most recent data as the test data, and the earliest data as the training data.
| Training-serving skew |
|---|
| (1) Training-serving skew can also occur based on your data distribution in your training, validation, and testing data splits. : the difference in production data versus training data. |
| (1) - e.g, In production, a model may be applied on an entirely different population of users than those seen during training, or the model may be used to make predictions 30 days after the final training data was recorded. |
(1) → For best results, ensure that the distribution of the data splits used to create your model accurately reflects the difference between the training data set, and the data that you will be making predictions on in your production environment. AutoML Tables could produce non-monotonic predictions, and if the production data is sampled from a very different distribution than the training data, non-monotonic predictions are not very reliable. |
| (2) Furthermore, the difference in production data versus training data must be reflected in the difference between the validation data split and the training data split, and between the testing data split and the validation data split. |
| (2) - e.g 1, Predictions about user lifetime value (LTV) over the next 30 days : MAKE SURE THAT Data in your validation data split is from 30 days after the data in your training data split, and that the data in your testing data split is from 30 days after your validation data split. |
(2) - e.g 2, Model to be tuned to make generalized predictions about new users : MAKE SURE THAT data from a specific user is only contained in a single split of your training data. For example, all of the rows that pertain to user1 are in the training data split, all of the rows that pertain to user2 are in the validation data split, and all of the rows that pertain to user3 are in the testing data split. |
- Provide a time signal
If the underlying pattern in your data is likely to shift over time (it is not randomly distributed in time), make sure you provide that information to AutoML Tables. You can provide a time signal in several ways:
- If each row of data has a timestamp, make sure that column is included, has a data type of
Timestamp, and is set as the Time column when you create your dataset. This ordering is used to split the data, with the most recent data as the test data, and the earliest data as the training data. Learn more.
- If your time column does not have many distinct values, you should use a manual split instead of using the Time column to split your data. Otherwise, you might not get enough rows in each dataset, which can cause training to fail.
- If the time information is not contained in a single column, you can use a manual data split to use the most recent data as the test data, and the earliest data as the training data.
Preparing your training data for AUTOML - About controlling data split |
|---|
| By default, AutoML Tables randomly selects 80% of your data rows for training, 10% for validation, and 10% for testing. |
| - For datasets that do not change over time, are relatively balanced, and that reflect the distribution of the data that will be used for predictions in production, the random selection algorithm is usually sufficient. |
| The key goal : to ensure that your test set accurately represents the data the model will see in production, ensuring that the evaluation metrics provide an accurate signal on how the model will perform on real world data. |
|
Provide a time signal
If the underlying pattern in your data is likely to shift over time (it is not randomly distributed in time), make sure you provide that information to AutoML Tables. You can provide a time signal in several ways:
If each row of data has a timestamp, make sure that column is included, has a data type of Timestamp, and is set as the Time column when you create your dataset. This ordering is used to split the data, with the most recent data as the test data, and the earliest data as the training data. Learn more.
If your time column does not have many distinct values, you should use a manual split instead of using the Time column to split your data. Otherwise, you might not get enough rows in each dataset, which can cause training to fail.
If the time information is not contained in a single column, you can use a manual data split to use the most recent data as the test data, and the earliest data as the training data.
Control what rows are selected for which split using 2 approaches
Time columnto tell AutoML Tables that time matters- Specify the Time column →
AutoML Tablesuses the earliest 80% of the rows for training, the next 10% of rows for validation, and the latest 10% of rows for testing. AutoML Tablestreats each row as an independent and identically distributed training example; setting the Time column does not change this. The Time column is used only to split the data set.- You must include a value for the Time column for every row in your dataset.
- Make sure that the Time column has enough distinct values, so that the evaluation and test sets are non-empty.
- Usually, having at least 20 distinct values should be sufficient.
- Time column data type :
Timestamp - Select this column as the Time column :
timeColumnSpecId- Possible only If you have not specified the data split column (
mlUseColumnSpecId): - Used to split rows into TRAIN, VALIDATE and TEST sets such that oldest rows go to TRAIN set, newest to TEST, and those in between to VALIDATE.
- If
timeColumnSpecId&ml_use_columnnot set → then ML use of all rows will be assigned by AutoML. - Updates of this field will instantly affect any other users concurrently working with the dataset.
- Possible only If you have not specified the data split column (
- If you have a time-related column but not useto split your data, set the data type for that column to
Timestampbut do not set it as the Time column.
- Specify the Time column →
Correct Answer: D
Should be D. As time signal that is spread across multiple columns so manual split is required.
Also think it is D, since it mentioned that the time signal is spread across multiple columns.
Correct answer is C - AutoML handles training, validation, test splits automatically for you when you specify a Time column. There is no requirement to do this manually.
Correct answer is D. It clearly says the time signal data is spread across different columns. If it weren't then C would be correct and your point would be valid. However, in this case the answer is D 100%.
https://cloud.google.com/automl-tables/docs/data-best-practices#time
upvoted 1 times
A. you need timestamp column, not array
B. You need timestamp column, so this wont work - AutoML will not automatically create a timestamp colument
C. You do not have a timestamp column, so this won't work
D. Seems the only one viable
Anyone wants to discuss all the questions in slack?
sure, we can do that. what is your slack?C
You use the Time column to tell AutoML Tables that time matters for your data; it is not randomly distributed over time. When you specify the Time column, AutoML Tables use the earliest 80% of the rows for training, the next 10% of rows for validation, and the latest 10% of rows for testing.
AutoML Tables treats each row as an independent and identically distributed training example; setting the Time column does not change this. The Time column is used only to split the data set.
You must include a value for the Time column for every row in your dataset. Make sure that the Time column has enough distinct values, so that the evaluation and test sets are non-empty. Usually, having at least 20 distinct values should be sufficient.
https://cloud.google.com/automl-tables/docs/prepare#time
upvoted 3 times
salsabilsf 3 months, 3 weeks ago
From the link you provided, I think it's A :
The Time column must have a data type of Timestamp.
During schema review, you select this column as the Time column. (In the API, you use the timeColumnSpecId field.) This selection takes effect only if you have not specified the data split column.
If you have a time-related column that you do not want to use to split your data, set the data type for that column to Timestamp but do not set it as the Time column.
upvoted 1 times
gcp2021go 4 months, 3 weeks ago
it should be C, since Automl tables give you the option of indicate the time column. But in practice, D could work.
--
Q19.
You have written unit tests for a Kubeflow Pipeline that require custom libraries. You want to automate the execution of unit tests with each new push to your development branch in Cloud Source Repositories. What should you do?
- ❌ A. Write a script that sequentially performs the push to your development branch and executes the unit tests on
Cloud Run.
→Cloud Run: Serverless for containerized applications- ⭕ B. Using
Cloud Build, set an automated trigger to execute the unit tests when changes are pushed to your development branch.
→Cloud Build: tool for CI/CD, GCP recommends to use Cloud Build when building KubeFlow Pipelines- ❌ C. Set up a
Cloud Loggingsink to aPub/Subtopic that captures interactions with Cloud Source Repositories. Configure aPub/Subtrigger forCloud Run, and execute the unit tests onCloud Run.
→Cloud Logging: Centralized logging- ❌ D. Set up a
Cloud Loggingsink to aPub/Subtopic that captures interactions with Cloud Source Repositories. Execute the unit tests using aCloud Functionthat is triggered when messages are sent to thePub/Subtopic.
| Architecture of CI/CD for ML pipeline using Kubeflow Pipelines |
|---|
At the heart of this architecture is Cloud Build, infrastructure.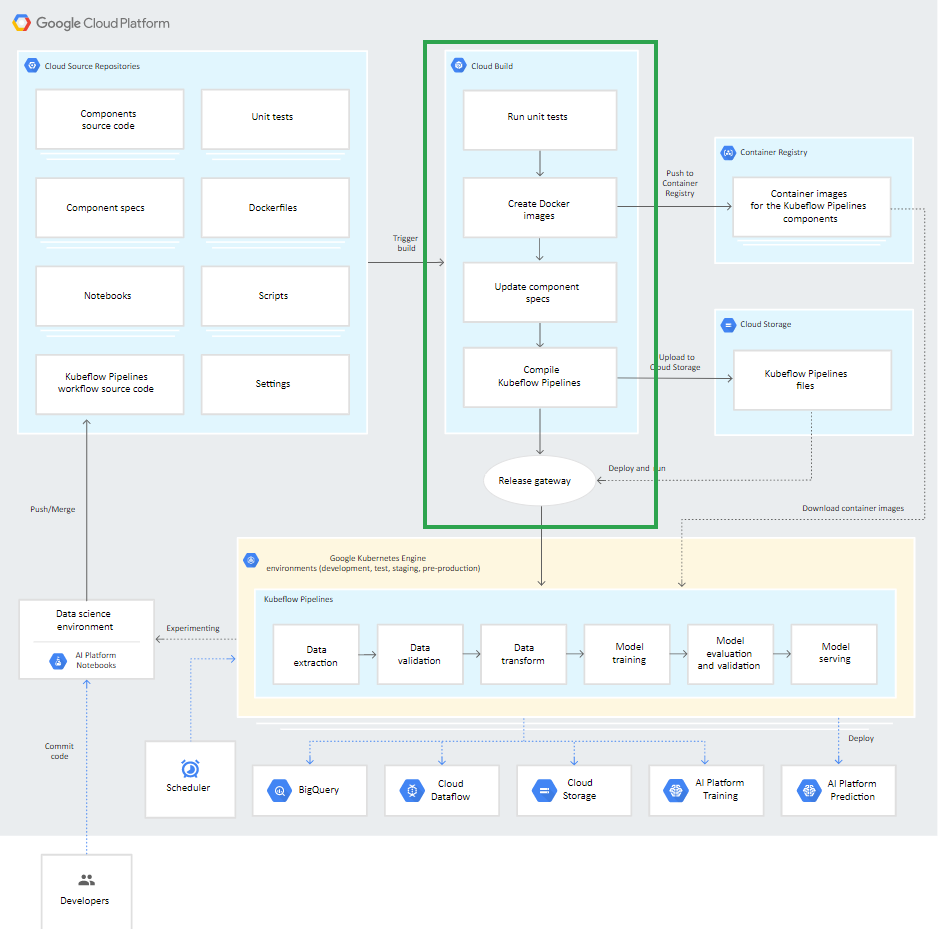 |
Cloud Build : a service that executes your builds on Google Cloud Platform infrastructure. |
✔ Can import source code from Cloud Storage, Cloud Source Repositories, GitHub, or Bitbucket, execute a build to your specifications, and produce artifacts such as Docker containers or Java archives. |
✔ Executes your build as a series of build steps, where each build step is run in a Docker container. : Defined in a build configuration file - cloudbuild.yaml |
→ Each build step is run in a Docker container irrespective of the environment. (for task : use the supported build steps provided by Cloud Build or write your own build steps.) |
| ✔ The Cloud Build process (CI/CD for your ML system) can be executed either manually or through automated build triggers. |
Q20.
You are training an LSTM-based model on AI Platform to summarize text using the following job submission script: gcloud ai-platform jobs submit training $JOB_NAME \
--package-path $TRAINER_PACKAGE_PATH \
--module-name $MAIN_TRAINER_MODULE \
--job-dir $JOB_DIR \
--region $REGION \
--scale-tier basic \
-- \
--epochs 20 \
--batch_size=32 \
--learning_rate=0.001 \
You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
- ❌ A. Modify the epochs parameter.
- ⭕ B. Modify the scale-tier parameter.
→_Epochs,Batch size,learning rateall are hyperparameters that might impact model accuracy.
→ Changing thescale tierdoes not impact performance–only speeds up training time_.- ❌ C. Modify the batch size parameter.
- ❌ D. Modify the learning rate parameter.
scale tiers = a set of cluster specifications |
|---|
| (1) When running a training job on AI Platform Training you must specify the number and types of machines. |
(2) To make the process easier, pick scale tires from a set of predefined cluster specifications OR choose a custom tier and specify the machine types yourself. |
| Options for configuration of the scale tiers |
| Using GPUs for training models in the cloud - Requesting GPU-enabled machines |
