해당 글은 강화 학습의 개념 전반에 대해 순차적으로 다룰 예정입니다.
이번 포스팅에서는 주어진 환경을 알 때 최적 정책을 도출해내는 Dynamic Programming 방법에 대해 다뤄볼 것입니다.
Prediction & Control
Prediction
- Prediction은 정책 가 주어질 때, 각 상태 별로 해당 정책에 대한 평가(가치 측정)를 수행하는 것이다.
Control
- Control은 Prediction을 통한 평가에서 그치지 않고, 해당 결과를 기반으로 업데이트를 반복하여 최적 정책 를 찾아내는 것이다.
따라서 주어진 MDP 모델에 대한 Prediction과 Control을 수행하여 최적 정책을 찾는 것이 Dynamic Programming의 목적이라고 할 수 있다.
Dynamic Programming (Planning)
Dynamic Programming은 이하의 성질들을 만족하는 문제에서 사용하기 좋은 방법이다.
- Optimal Substructure
- 주어진 문제를 substructure 단위로 나눠서 찾은 최적해가 기존의 전체 문제에서도 성립한다.
- 일반적인 재귀 함수의 형태를 생각하면 된다.
- Operlapping Subproblems
- Optimal Substructure 성질을 만족하는 문제들의 중복 연산을 방지한다.
- fibonacci 수열에서는 단순 재귀 함수를 사용하는 경우 동일한 연산을 반복하는 문제가 발생한다.
(다행스럽게도) MDP는 이러한 Dynamic Programming을 위한 두 가지 성질을 모두 만족하기 때문에, MDP를 알고 있는 환경에서는 Dynamic Programming을 통해 문제를 해결(최적 정책을 계산) 할 수 있다.
Iterative Policy Evaluation (Prediction)
Iterative Policy Evaluation은 주어진 정책 를 기반으로 각 상태의 가치를 계산하고, 해당 결과를 업데이트한 후 다시 가치를 계산하는 과정을 반복하는 방법이다.
따라서, Iterative Policy Evaulation을 통해 우리는 ~까지의 가치 함수를 순차적인 백업을 통해 계산하는 것이다. 이 때, 각 상태의 가치를 계산하는 방식은 벨만 기대 방정식을 따른다. 또한, 이 반복적인 백업은 synchronous(동기식) 백업 방식을 사용한다.
Synchronous Backup은 특정 단계에서 계산한 가치 함수의 업데이트를 해당 단계의 모든 상태에서의 가치 계산이 끝난 후에 수행한다는 것이다. 예를 들어, 각 상태의 가치를 0으로 초기화 한 직후 가치 함수 을 계산하는 첫 번째 단계에서 상태의 가치를 계산한 결과가 -1인 상황을 고려해 보자. 그 직후 의 가치를 계산하는데 의 가치를 사용한다고 했을 때, 이 연산에서 사용하는 의 가치는 직전에 계산한 -1이 아닌, 첫 번째 단계를 시작하기 전에 초기화되었던 0이 된다는 것이다. 그리고 이렇게 계산된 상태의 가치 -1은 첫 번째 단계의 모든 상태의 가치를 계산한 후, 두 번째 단계가 시작되기 전에 업데이트 되는 것이다. 이러한 방식을 Synchronous Backup이라고 한다.
이러한 과정을 통해 최적 가치 함수 를 찾을 수 있는 이유는, 가치 함수의 계산에 사용된 벨만 기대 방정식에 이전 단계의 가치 함수를 사용하는 항이 포함되어 있는 재귀 함수의 형태를 띄고 있으며, ‘정확한 값’으로 판단할 수 있는 보상 가 포함되어 있기 때문이다.
벨만 기대 방정식의 가치 함수 계산식을 Iterative Policy Evaluation에 맞게 수정하면 아래와 같이 표현할 수 있다.
또한, 해당 식을 간략하게 표현하면 아래와 같이 나타낼 수 있다.
즉, 특정 단계의 가치 함수를 계산할 때, 이전 단계에 계산하고 업데이트한 가치 함수를 사용하게 되는 것이다. 이 사실이 중요한 이유는 앞에 있는 의 존재 때문이다. 는 특정 상태 에서 다음 상태 로 이동할 때 획득한 보상으로, MDP의 환경이 제공하는 ‘정확한 값’이다. 반면, 맨 처음 임의의 값으로 초기화 한 (편의상 이렇게 표기하겠다.)의 경우, 말그대로 임의로 정한 부정확한 값이기 때문에 은 최적 가치 함수 와는 동떨어진 ‘부정확한 값’일 수밖에 없다. 하지만 단계를 거치며 ‘정확한 값’인 보상 가 ‘부정확한 값’인 가치 함수의 업데이트에 사용되면서 점차 정확해지는 것이다.
Example of Iterative Policy Evaluation
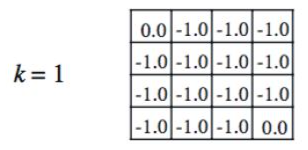
위 그림처럼 구성되어 있는 grid map을 고려해보자. 이 grid map은 이하 조건들을 만족하는 MDP이다.
"이 grid의 방향에 위치한 grid인 경우" "가 map 가장자리의 grid이고 가 바깥 방향일 때 인 경우"
회색 grid는 terminal로, terminal에 도달하면 action을 중지한다고 하자.
앞의 상황에서, 각 상태의 가치를 전부 0으로 초기화한 후 각 상태의 가치를 계산하는 동작을 수행하면 아래와 같이 모든 상태의 가치가 -1이 된다는 사실을 알 수 있다. Terminal의 경우는 예외적으로 해당 grid에 도착한 이후의 동작이 없기 때문에 가치가 0으로 고정된다.


그럼 이제 첫 번째 단계의 가치 함수 를 알 수 있기 때문에, 해당 결과를 백업한 후에 두 번째 단계의 가치 함수를 계산하는 것이다. 그 결과 아래와 같이 2단계의 가치 함수 를 계산할 수 있다.

위 결과를 보면, terminal과의 위치 관계에 따라 각 상태에서의 가치가 점점 달라진다는 사실을 알 수 있다. 각 상태에서 선택한 action의 보상이 가치 함수에 점점 반영되기 시작한 것이다.
따라서 이러한 과정을 통해 점차 단계를 반복하다보면 어느 시점에서 더이상 단계를 반복해도 가치 함수가 변하지 않는 상태에 도달하게 된다. 이 때 주의해야할 점은 이 시점의 가치 함수가 최적 가치 함수가 아니라는 점이다. 그 이유는 해당 가치 함수를 계산하기 위해 사용한 정책이 최적 정책 가 아니기 때문이다.

Greedy Improvement
지금까지의 과정은 앞서 말했던 Prediction에 해당하는 Iterative Policy Evaluation의 과정이기 때문에, 이제 최적 정책을 찾기 위한 정책의 업데이트 과정이 필요한 시점이다. 이 때 사용하는 방식이 Greedy Improvement 방식이다.
Greedy Improvement는 최적 정책으로 가는 action의 확률이 커지도록 정책을 수정하는 방식이다. 즉, 특정 상태 에서 다음 상태 로 넘어가는 action을 선택할 때 가치 함수가 가장 큰 을 선택하는 action을 선택할 확률만 남도록 정책을 수정하는 것이다.
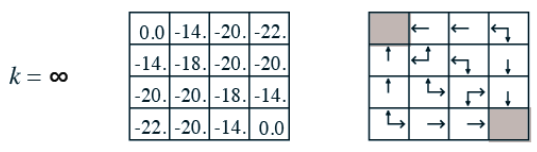
위 그림의 왼쪽 grid map은 각 grid의 가치 함수를 나타내는 그림이고, 오른쪽은 Greedy Improvement를 통해 수정한 정책을 화살표를 통해 표현한 것이다. 그림을 보면 다음 상태에서의 가치가 가장 큰 방향으로 action을 취할 수 있도록 정책이 수정되었다는 사실을 확인할 수 있다. 따라서 이렇게 수정된 정책을 MDP에서 사용할 정책으로 업데이트하는 것을 Greedy Improvement라고 하는 것이다. 이렇게 수정된 정책은 최적 정책은 아닐 수 있지만, 최소한 기존의 정책보다는 더 좋은 정책이 된다. 이 때 주의해야할 점은 Greedy Improvement를 통한 정책의 업데이트는 Iterative Policy Evaluation을 진행하면서 더이상 가치 함수가 변하지 않는 임계점에 도달한 후에 진행해야 한다는 점이다. (이는 Iterative Policy Evaluation이 Synchronous Backup 방식을 사용용하는 것과, 어차피 이후 설명할 Policy Iteration을 통해 동작을 무수히 반복하면 최적 정책이 같은 값으로 수렴한다는 사실 때문이다.)
Policy Iteration
Policy Iteration은 Iterative Policy Evaluation과 Greedy Improvement 과정을 반복하여 최종적으로 최적 정책을 구하는 방식이다.
다시 한 번 정리하면 Iterative Policy Evaluation 과정에서는 처음에 주어진 policy에 대한 가치 함수를 평가할 수 있고, Greedy Improvement 과정에서는 이렇게 평가된 가치 함수를 기반으로 더 좋은 정책을 추론할 수 있다. 따라서 이하 두 과정을 순차적으로 진행하게 되면 주어진 정책보다 더 좋은 새로운 정책을 획득하게 되는 것이다. 그리고 그렇게 얻은 새 정책을 사용해 다시 Iterative Policy Evaluation과 Greedy Improvement를 진행하면 더 좋은 정책을 획득할 수 있게 된다. 결국, 이렇게 Iterative Policy Evaluation과 Greedy Improvement를 반복하다보면 어느 순간 정책이 최적 정책으로 수렴하게 된다는 것이 Policy Iteration의 아이디어이다.
Value Iteration
Value Iteration은 Bellman Optimal Equation과 동일하게, 특정 상태에서 가장 가치가 높은 상태로 가는 액션만을 사용해서 해당 상태의 가치를 업데이트하는 방식이다.
Policy Iteration을 할 때의 가장 큰 의문은 정책이 최적 정책으로 수렴할 때까지 Iterative Policy Evaluation과 Greedy Improvement를 반복해야 하는 것인가일 것이다. 특정 환경에서는 간단히 끝날 수 있지만, 어떤 환경에서는 수십, 수백 번을 반복하더라도 수렴하지 않을 수 있는 것이다. 결국, 이러한 측면에서의 문제점을 해결하기 위해 제시된 것이 바로 Value Iteration이다.
Bellman Optimal Equation에서는 각 상태에서 액션 가치 함수값이 가장 큰 액션을 선택하는 액션을 선택하는 에피소드의 정책을 최적 정책이라고 한다. 이를 동일하게 사용하여 가치 함수를 계산, 업데이트 하는 것이 Value Iteration이다. 아래의 그리드 맵을 보면, 각각의 상태와 이웃한 상태의 가치값만을 사용해서 해당 상태의 가치를 업데이트하는 것을 확인할 수 있다.
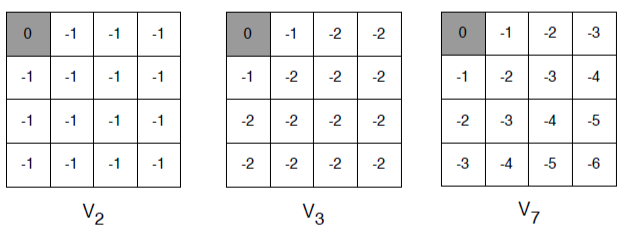
Value Iteration에서 주의해야 할 점은 iteration의 과정에서 정책의 사용 및 업데이트에 대한 동작을 사용하지 않는다는 점이다. 앞서 말했듯 Value Iteration은 Bellman Optimal Equation을 사용했으니, 해당 내용을 다룬 포스팅에서 식을 하나 가져와보자.
바로 이 식이다. 이 식에 따르면 Bellman Optimal Equation에서의 최적 정책은 각 상태에서 액션 가치 함수가 최대가 되는 액션의 확률이 1이고, 아닌 경우 0이 되는 정책이다. 즉, 이 경우의 최적 정책은 미리 주어져 있는 것이 아닌, 주어진 환경에서의 가치를 사용해 계산할 수 있는 것이다. 이 사고방식을 그대로 가져와서 사용하는 것이 바로 Value Iteration이다. 결국 특정 상태에서 갈 수 있는 다음 상태 중에서 가장 가치가 높은 상태를 선택하여 가치를 업데이트 한다는 것이다. 이러한 과정으로 가치 함수를 업데이트 하면 Policy Iteration 마냥 매번 정책을 업데이트할 필요도 없을 뿐더러, 가치 함수를 업데이트 하는 횟수 역시 비약적으로 줄어들게 된다. 뭐, 우리가 궁극적으로 원하는 최적 정책 은 가치 함수가 더이상 업데이트되지 않는 시점에서의 정책을 마찬가지로 Bellman Optimal Equation을 기반으로 계산하면 될 것이다. 물론 이 경우도 최적 정책을 획득하기 위해서는 가치 함수가 수렴해야 한다는 전제 조건이 있지만, 그래도 Policy Iteration과 비교했을 때 연산량이 절대적으로 적다는 것은 부정할 수 없는 사실이다.
