추천시스템의 종류
1. Collaborative Filtering
□ 메모리 기반 접근 (Neighborhood-based)
□ 모델 기반 접근 Explicit
□ 모델 기반 접근 Implicit, MF-based
□ 모델 기반 접근 Implicit, Metric / Deep learning-based
2. Side Information-based Recommendation
□ 컨텐츠 기반 추천
☑ 컨텐츠 기반 Collaborative Filtering
CF와 Content-based의 결합
지금까지 사용자간의 데이터를 사용하는 CF와, 사용자 외의 아이템 정보를 활용하는 CB에 대해 알아보았다. CF와 CB모델들은 각각 장점과 단점을 지니고 있다.
| Collaborative Filtering | Content-based | |
|---|---|---|
| 장점 | 도메인과 관계 없이 적용 가능 | 새로 등록한아이템도 추천 할 수 있음 |
| 사용자간의 상호작용을 기반으로 새로운 추천 확률 높음 | 기존 데이터를 기반으로 하기 때문에 생뚱맞은 추천 확률 적음 | |
| 단점 | 새로운 유저에 대한 정보가 부족해 Cold Start 문제가 있음 | 새로운 장르의 아이템 추천이 어려움 |
이처럼 CF와 CB는 상호 보완적인 특성을 지닌다. CF가 새로운 추천을 할 수 있는 반면, Cold Start에 취약하다면. CB는 새로운 추천에는 약하지만, Cold Start에는 강하다. 이 두 방법의 장점을 모두 취하고자 이 두가지를 함께 활용하는 방법들이 존재한다.
Side Information : Tabular Feature Data
CF는 유저별 아이템 평점 데이터를 인풋으로 받았고, CB는 아이템별 속성을 인풋으로 받았다. CB와 CF를 동시에 고려한 모델은 적어도 이 두 가지 정보를 포괄하는 Context를 인풋으로 받는다; time, location, social information, text, image 등등.
다음부터 설명할 Factorization Machine에서는 다음과 같이 Side Information을 정의한다. 이전에 본 데이터들과 달리 최종 평점을 목표변수 로 두고 있다는 특징이 있다. 열 속성들은 차례대로 : 유저, 평가한 영화, 전체 영화 평점, 평가 시점, 이전에 본 영화 .. etc를 포괄하여 맥락을 표현하고 있다.
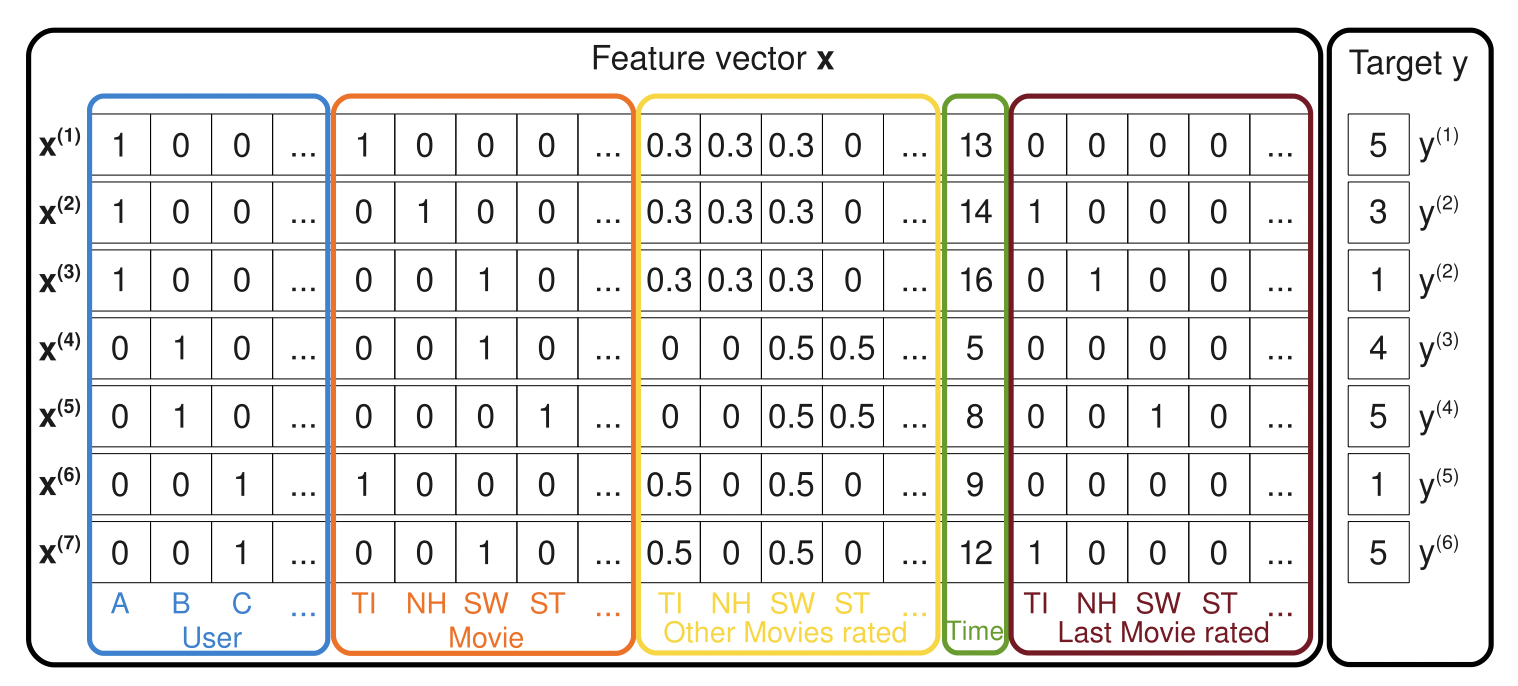
[Rendle, S. (2010, December). Factorization machines. In 2010 IEEE International conference on data mining (pp. 995-1000). IEEE.]<\span>
1. FM
표에서 보여지는 각각의 user-item 데이터는 결과적으로 특정 시간에 아이템 에 대한 유저 의 평점인 에 특정한 가중치로 반영 될 것이기에 선형회귀로 표현될 수 있다.
그런데 위 데이터의 특성상, 매우 sparse한 고차원 행렬이기 때문에 다중선형회귀로 이 데이터를 설명하는 데 한계가 존재한다. 이 한계를 보완하면서 유저와 아이템간의 잠재적 관계를 모델링 하기 위해 다음과 같은 다항회귀식을 추가할 수 있다. 유저 와 유저 의 weight를 곱해 유저간의 관계를 파악하는 식이다.
하지만 이 식의 문제는, 다항회귀식의 곱셈은 파라미터 수가 기하급수적으로 증가하기 때문에 연산량에 문제가 발생하게 된다. 이를 개선하기 위해 를 두개의 벡터 로 분해할 수 있다. 벡터간의 내적으로 연산을 진행하면 시간복잡도가 으로 감축된다.
이것이 Side Information을 감안한 추천알고리즘인 Factorization Machine이다.
[Rendle, S. (2010, December). Factorization machines. In 2010 IEEE International conference on data mining (pp. 995-1000). IEEE.]
2. Wide & Deep
Wide & Deep Model은 위에서 다룬 Factorization Model을 DNN에 적용한 사례다. 실제로 구글에서 많이 쓰였다고 한다. 다음 그림에서 Sparse Features의 노란색은 유저가 아이템을 구매&호감 표시를 했을 때이고, 회색은 유저와 아이템간의 교류가 아예 없는 경우이다. Wide&Deep Model은 이러한 모든 구매&호감 데이터를 인풋으로 받는다. 가령 유저 의 어플리케이션 구매 패턴을 예로 들면:
- Market : A, B, C
- Like : A,
B, C - Intsall : A,
B,C
| Install | Like | Install x Like | Notation |
|---|---|---|---|
| A | A | 1 | |
| A | B | 0 | |
| A | C | 1 |
왼쪽의 Wide Model(Generalized Linear Model)은 모든 경우의 수, 전체 인풋을 받으며, 오른쪽의 Deep Model은 그 가운데 실제 유저 인터랙션이 있었던 인풋만을 받는다. 서로 다른 이 모델을 결합한 가운데 그림이 Wide&Deep Model이다.
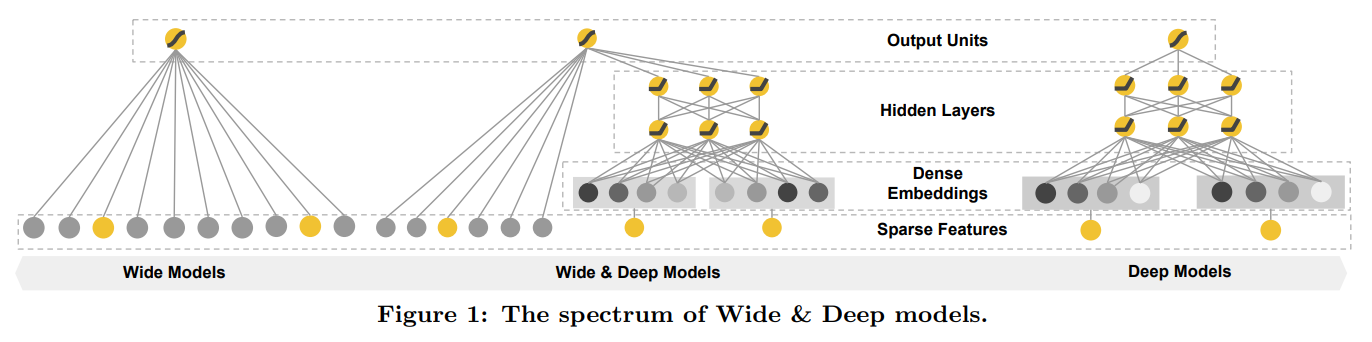
Wide Model의 역할은 Memorization으로, 단순한 선형/로지스틱 회귀를 통해 효율적으로 각 요소별 중요도를 파악한다. 반면 Deep Model의 역할은 Generalization으로, 낮은 차원의 Dense Embedding을 통해 보지 못했던 속성을 파악하는 것이다. 이 두 특성을 반영할 수 있게끔 만든 것이 Wide&Deep Model이다.
Wide Model :
Deep Model :
Wide&Deep Model :
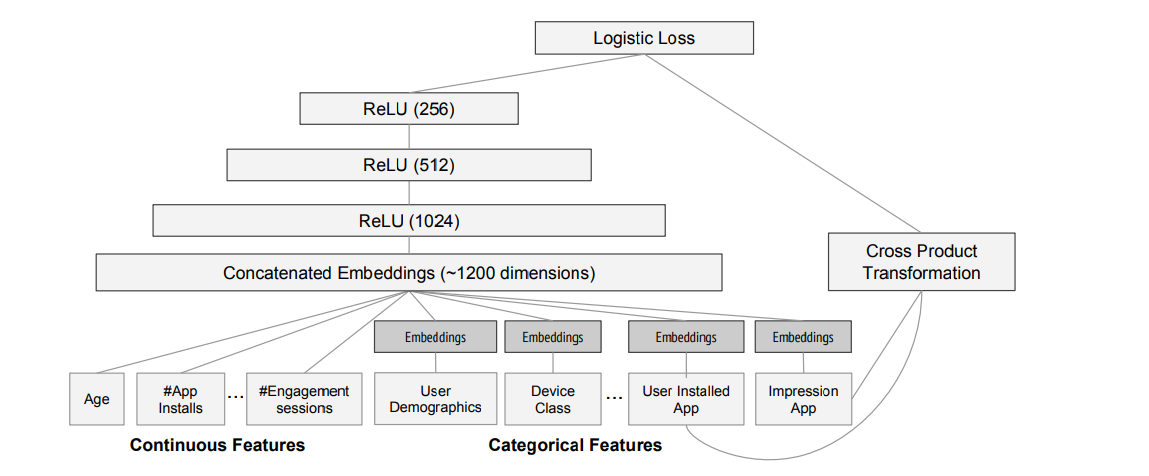
[Cheng, H. T., Koc, L., Harmsen, J., Shaked, T., Chandra, T., Aradhye, H., ... & Shah, H. (2016, September). Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems (pp. 7-10).]
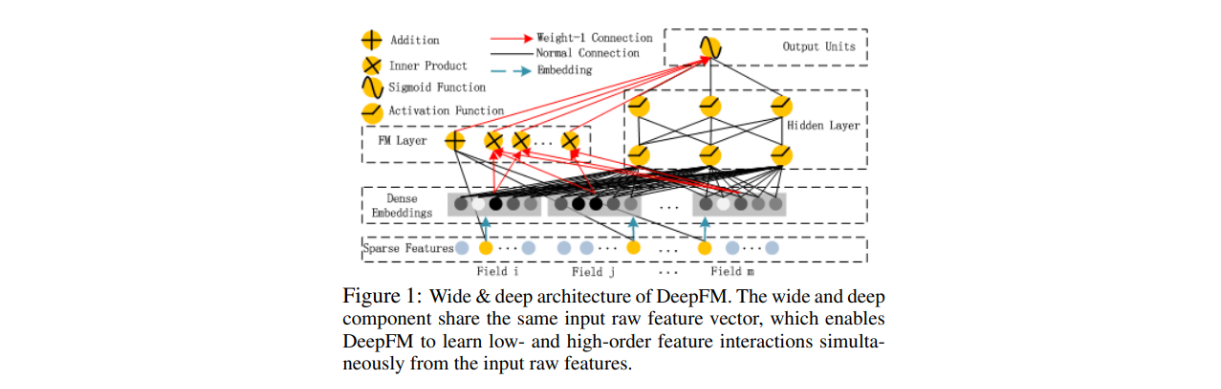
3. Deep FM
Deep FM도 FM 모델에 딥러닝을 결합했다는 점에서 Wide&Deep 모델과 같은 취지를 가지고 있다. 우선 DNN과 FM의 구조를 살펴보자.
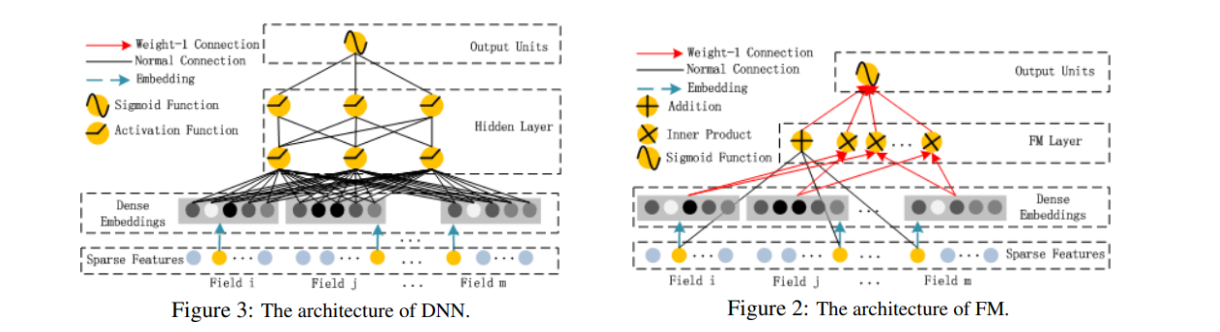
그림에서 보이는 DNN과 FM을 결합한 것이 Deep FM이다. 차이점이 있다면, Wide&Deep Model은 각각 Wide와 Deep에 들어가는 인풋의 모양이 달라 Feature Engineering을 해줘야 했다면, Deep FM은 그럴 필요가 없다는 점이다. 즉, 서로 다른 두 모델이 인풋을 공유한다는 점이다.
Reference
CF와 CB의 결합, 지그시 블로그
