- 구조 분해를 사용하면 복합적인 값을 분해해서 별도의 여러 지역 변수를 한꺼번에 초기화할 수 있음
사용 방법
fun main() {
val p = Point(10, 20)
val (x, y) = p // p의 여러 컴포넌트로 초기화
println(x)
// 10
println(y)
// 20
}- 일반 변수 선언과 비슷해 보이지만 = 왼쪽에 여러 변수를 괄호로 묶음
- 구조 분해 선언은 관례를 사용함 → componenN 이라는 함수를 호출
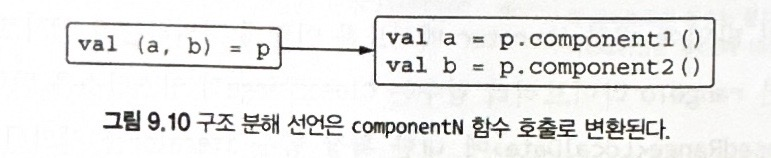
- data 클래스의 주 생성자에 들어있는 프로퍼티 → 컴파일러가 자동으로 componentN 함수를 만들어줌
class Person(val x: Int, val y: Int) {
operator fun component1() = x
operator fun component2() = y
}예시
data class NameComponent(val name: String, val extension: String)
fun splitFilename(fullName: String): NameComponent {
val (name, extension) = fullName.split('.', limit = 2)
return NameComponent(name, extension)
}
fun main() {
val (name, ext) = splitFilename("example.txt")
println(name)
// example
println(ext)
// txt
}- componentN을 무한히 선언할 수는 없음
- 코틀린 표준 라이브러리에서는 맨 앞의 다섯 원소에 대한 componentN을 제공
구조 분해 선언과 루프
- 변수 선언이 들어갈 수 있는 모든 곳에 구조 분해 선언을 사용할 수 있음
fun printEntries(map: Map<String, String>) {
for((key, value) in map) {
println("$key -> $value")
}
}
fun main() {
val map = mapOf("Oracle" to "Java", "JetBrains" to "Kotlin")
printEntries(map)
// Oracle -> Java
// JetBrains -> Kotlin
}-
위 예제는 2가지의 관례를 사용함
- 이터레이션 관례
- 코틀린 표준 라이브러리 → map에 대한 확장함수로 iteration이 들어있음
- 맵 항목에 대한 이터레이터를 반환
- 구조 분해 선언
- 코틀린 라이브러리 → map.Entry에 대한 확장함수로 component1, component2를 제공
- 이터레이션 관례
-
람다가 data class나 map 같은 복합적인 파라미터로 받을 때도 구조 분해 선언을 쓸 수 있음
map.forEach { (key, value) ->
println("$key -> $value")
}_ 문자를 사용해 구조 분해 값 무시
- 컴포넌트가 여럿 있는 객체에 대한 구조 분해 선언 중 일부 필요하지 않은 컴포넌트를 무시
data class Person(
val firstName: String,
val lastName: String,
val age: Int,
val city: String
)
fun introducePerson(p: Person) {
val (firstName, _, age) = p
println("This is $firstName, aged $age")
}
fun main() {
val me = Person("yoo", "wuseon", 26, "ganwondo")
introducePerson(me)
// This is yoo, aged 26
}코틀린 구조 분해의 한계
- 구조 분해 연산의 결과 → 인자의 위치에 따라 결정됨
- 코드를 리펙터링 할 때 클래스 프로퍼티의 순서를 바꾸면 미묘한 문제가 발생할 수 있음
- 이 문제를 해결하기 위해 이름 기반 구조 분해가 개발되고 있는 중임
