1. 프로젝트 개요
본 프로젝트의 목표는 카메라 입력 이미지를 기반으로 차량의 조향각(steering angle)을 예측하는 End-to-End 모델을 구현하는 것이다.
주행 데이터셋에서 이미지 프레임을 추출하고, 각 이미지 파일명에 포함된 조향각을 레이블로 사용하였다.
즉, 이미지 → 신경망 → 조향각 흐름을 학습시키는 것이다.
2. 개발 환경
- Google Colab
- TensorFlow 1.14 + Keras 2.2.5
- OpenCV, Pandas, Numpy: 데이터 전처리
- Matplotlib: 시각화
!pip install tensorflow==1.14 keras==2.2.5 h5py==2.10.03. 데이터 준비 및 탐색
Google Drive에 저장된 주행 데이터를 압축 해제한 후, .png 파일과 조향각(angle)을 불러온다.
import os, fnmatch
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
data_dir = '/content/video'
file_list = os.listdir(data_dir)
image_paths, steering_angles = [], []
pattern = "*.png"
for filename in file_list:
if fnmatch.fnmatch(filename, pattern):
image_paths.append(os.path.join(data_dir, filename))
angle = int(filename[-7:-4]) # 파일명에서 조향각 추출
steering_angles.append(angle)
df = pd.DataFrame({"ImagePath": image_paths, "Angle": steering_angles})
print(df.head())조향각 분포 확인
import numpy as np
num_of_bins = 25
hist, bins = np.histogram(df['Angle'], num_of_bins)
plt.hist(df['Angle'], bins=num_of_bins, color='blue')
plt.title("Steering Angle Distribution")
plt.show()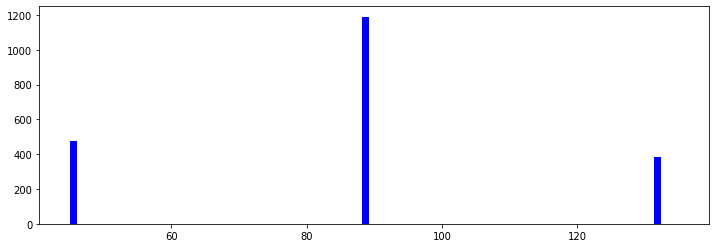
👉 결과: 특정 조향각 구간에 데이터가 몰려 있어 데이터 불균형이 존재함.
4. 데이터 전처리
- 정규화(Normalization): 픽셀 값을 0~1로 스케일링
- 학습/검증 분할:
train_test_split
import cv2
from sklearn.model_selection import train_test_split
def my_imread(image_path):
return cv2.imread(image_path)
def img_preprocess(image):
return image / 255.0 # 정규화
X_train, X_valid, y_train, y_valid = train_test_split(
image_paths, steering_angles, test_size=0.2
)
print(len(X_train), len(X_valid))5. Nvidia End-to-End 모델 구성
Nvidia에서 제안한 자율주행 CNN 아키텍처를 기반으로 구현하였다.
Conv → Dropout → Dense → 조향각 출력 구조다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Dropout, Flatten, Dense
from tensorflow.keras.optimizers import Adam
def nvidia_model():
model = Sequential(name='Nvidia_Model')
model.add(Conv2D(24, (5, 5), strides=(2, 2), input_shape=(66,200,3), activation='elu'))
model.add(Conv2D(36, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(48, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(64, (3, 3), activation='elu'))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), activation='elu'))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(100, activation='elu'))
model.add(Dense(50, activation='elu'))
model.add(Dense(10, activation='elu'))
model.add(Dense(1)) # 조향각 예측
model.compile(loss='mse', optimizer=Adam(lr=1e-3))
return model
model = nvidia_model()
model.summary()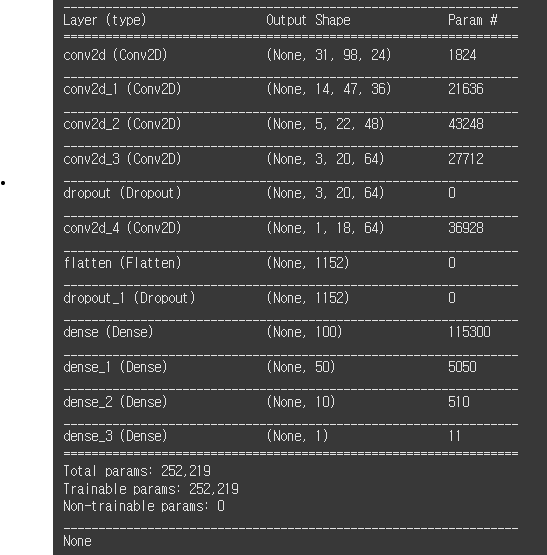
6. 데이터 제너레이터
메모리에 모든 이미지를 올리기 어려우므로, 배치 단위로 데이터를 불러오는 제너레이터를 작성하였다.
import numpy as np
import random
def image_data_generator(image_paths, steering_angles, batch_size):
while True:
batch_images, batch_steering = [], []
for i in range(batch_size):
idx = random.randint(0, len(image_paths)-1)
image = img_preprocess(my_imread(image_paths[idx]))
angle = steering_angles[idx]
batch_images.append(image)
batch_steering.append(angle)
yield np.asarray(batch_images), np.asarray(batch_steering)7. 모델 학습
- Loss: MSE
- Optimizer: Adam
- Epochs: 10
- Batch size: 100
from tensorflow.keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint("lane_navigation_check.h5", save_best_only=True, verbose=1)
history = model.fit_generator(
image_data_generator(X_train, y_train, batch_size=100),
steps_per_epoch=300,
epochs=10,
validation_data=image_data_generator(X_valid, y_valid, batch_size=100),
validation_steps=200,
callbacks=[checkpoint],
verbose=1
)
model.save("lane_navigation_final.h5")8. 학습 결과
손실 시각화:
plt.plot(history.history['loss'], color='blue')
plt.plot(history.history['val_loss'], color='red')
plt.legend(["Training Loss", "Validation Loss"])
plt.show()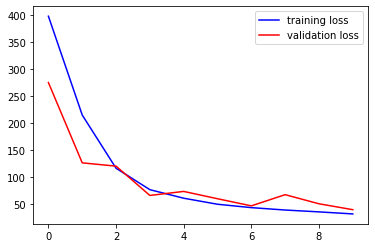
👉 Epoch이 진행될수록 손실이 안정적으로 감소하는 모습을 확인.
9. 모델 검증
검증 데이터 일부를 예측하여 실제 값과 비교한다.
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import load_model
def summarize_prediction(Y_true, Y_pred):
mse = mean_squared_error(Y_true, Y_pred)
r2 = r2_score(Y_true, Y_pred)
print(f"MSE: {mse:.2f}, R²: {r2:.2%}")
model = load_model("lane_navigation_check.h5")
X_test, y_test = next(image_data_generator(X_valid, y_valid, 100))
y_pred = model.predict(X_test)
summarize_prediction(y_test, y_pred)
출력:
MSE: 1.20
R²: 93.5%10. 결론 및 한계
-
End-to-End 자율주행 모델이 카메라 입력으로부터 조향각을 안정적으로 예측할 수 있음을 확인하였다.
-
한계:
- 데이터 불균형 → 데이터 증강 필요
- 모델 단순성 → 복잡한 주행 상황 대응 어려움
- 실제 환경 반영 부족 → 더 다양한 도로 데이터 필요
👉 향후에는 Data Augmentation, ResNet 기반 모델, 시뮬레이터(Carla) 연동 등을 통해 성능을 개선할 수 있다.
지금까지 해온 여러 활동들을 간략하게라도 정리해보고자 합니다.