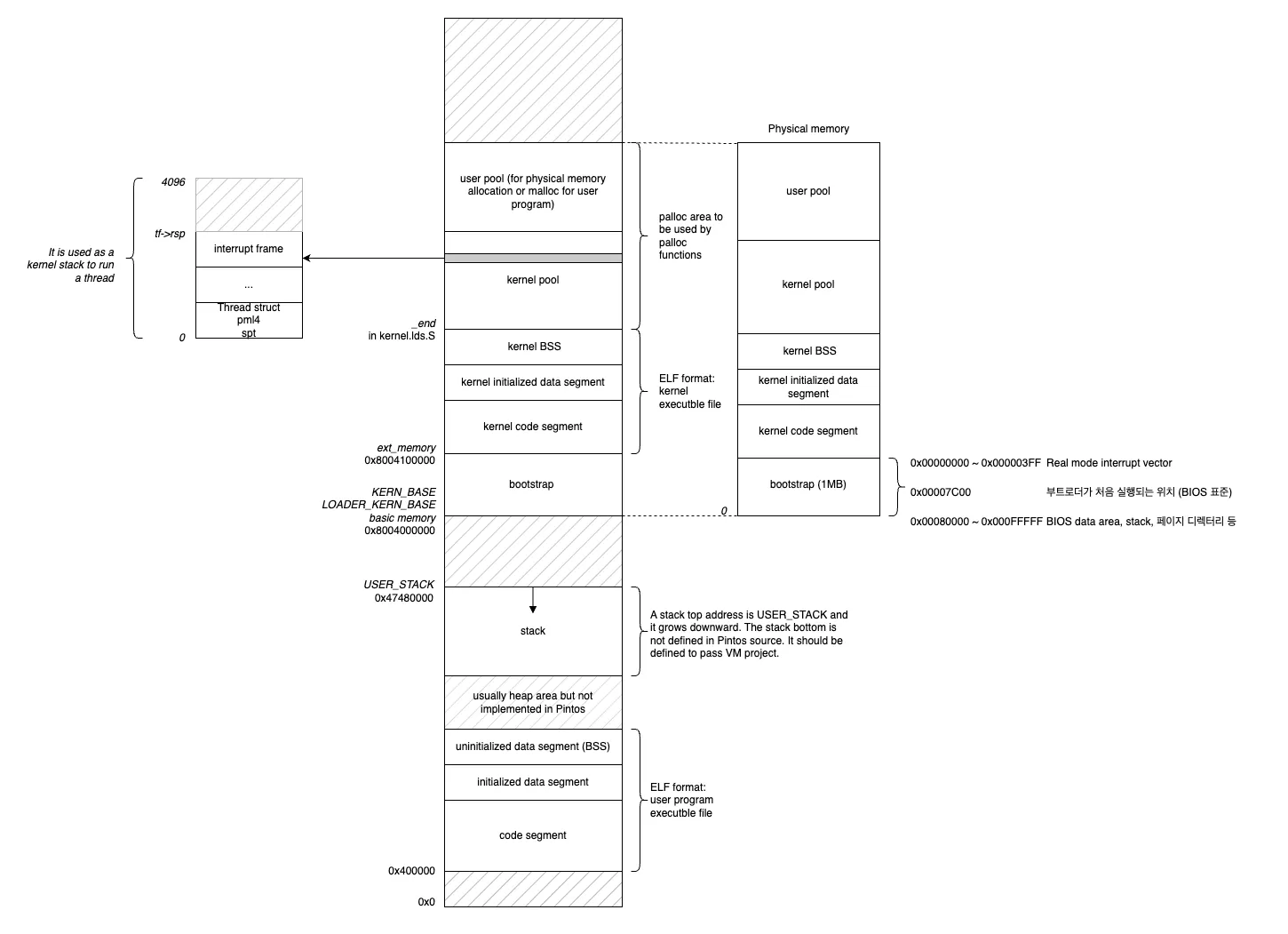
실제 메모리까지 그려놓은 메모리 레이아웃이다. 그림을 보면 kernel 가상 메모리와 실제 메모리가 1대1로 매핑되어 있는 모습을 볼 수 있다.
일단 메모리 영역의 top부터 아래로 내려오자면 kernel pool과 user pool 공간이 있다. 구현을 할 때 이 공간들이 많이 쓰인다. 스레드 구조체를 생성하면 kernel pool에 공간에 할당되고 스레드가 가지고 있는 VA를 통해서 실제 물리 메모리로 접근을 할 수 있게 된다. 물리 메모리를 할당하기 위해서는 물리 메모리의 주소를 가리키고 있는 가상 주소를 알아야 하는데 구현된 함수 중에 pml4함수가 존재한다. 이 함수는 물리 메모리와 가상 메모리를 매핑해 주는 함수로 매핑 전에 가상 메모리에 할당 공간을 만들어주기 위해 palloc을 쓰는 것으로 알고 있다(이 부분은 정확하지 않다…). 이번 과제 같은 경우 palloc을 사용해야 되는 경우와 malloc을 사용해야 되는 경우가 존재하는데 보통 실제 메모리의 공간을 할당하지 않는 uninit이나 anony page 같은 경우 가상 메모리에서만 공간을 할당해주므로 malloc을 써야 되는 것으로 알고 있다.
커널 공간에 user pool이 존재하는 이유가 궁금하지 않은가? 형의 도움으로 알게 되었는데 원래는 user heap 공간이 존재하지만 pintos 환경에서는 heap 공간이 존재하지 않기 때문에 user pool 공간에 메모리를 할당한다고 한다. 또한 kernel pool과 user pool은 커널 공간의 대부분의 공간을 차지한다. 이유는 대부분의 일을 이 공간에서 처리하기 때문이다.
밑으로 좀 더 내려가면 .bss → .data → .rodata → .text 공간이 존재한다. 중요한 것은 그 밑의 kernel base 가상 주소이다. 보면 0x8004000000이라고 되어 있으면 이 주소를 기준으로 위는 커널 공간, 아래는 유저 공간임을 알 수 있기 때문이다.
커널 base와 user stack은 바로 이어져있지 않고, 빈 공간이 존재한다. 아마 user stack 영역에 침범하는 것을 방지하기 위함이 아닐까? user stack 시작 주소는 0x47480000이며, 커널 베이스부터 user stack 시작 주소까지의 주소 값에 모르고 메모리를 할당해버리면 어떻게 될까? 어떻게 되는 지는 나도 잘은 모르겠지만 디버깅을 찍어봤을 때 해당 주소 범위에 할당하지 않기 위해서는 접근하지 못하도록 메모리 범위를 지정해줘야 할 것이다.
그림에서 또 한 가지 알 수 있는 것은 컴퓨터 시스템에서 배웠던 힙 영역이 존재하지 않는다. 따라서 스택이 힙 영역까지 내려올 수 있는데 힙 영역이 있다고 가정을 하고, 최대로 사용할 수 있는 영역을 지정해줘야 할 것이다.
spt_find_page 디버깅
/* 유효성 검사를 통해 PAGE를 spt에 삽입합니다. */
bool spt_insert_page(struct supplemental_page_table *spt,
struct page *page)
{
int succ = false;
dprintfa("[spt_insert_page] routine started. inserting page->va: %p\n", page->va);
if (spt == NULL || page == NULL) // 좋았어.
{
dprintfa("[spt_insert_page] validation failed\n");
return false;
}
if (hash_insert(&spt->hash, &page->hash_elem) == NULL) // null이면 삽입 성공
{
dprintfa("[spt_insert_page] insert success\n");
succ = true;
}
else // 실패
{
dprintfa("[spt_insert_page] insert fail");
succ = false;
}
return succ;
}/* spt에서 VA를 찾아서 페이지를 반환합니다. 실패 시 NULL을 반환합니다. */
struct page *
spt_find_page(struct supplemental_page_table *spt, void *va)
{
dprintfa("[spt_find_page] va: %p\n", va);
struct page *page = NULL;
// - 가상 주소 `va`에 해당하는 페이지를 supplemental page table에서 찾습니다.
// - 찾지 못하면 `NULL`을 반환합니다.
/*
* DEBUG: palloc으로 페이지를 따로 할당하고 free하는 식으로 검색용 페이지를 썼으나 탐색 실패. 왜 실패했는지는 모르겠음.
* 스택 변수로 바꾼 후 탐색 성공^^.
*/
struct page input_page ;
dprintfa("[spt_find_page] input_page malloc\n");
struct hash_elem *e;
dprintfa("[spt_find_page] routine started\n");
input_page.va = pg_round_down(va);
dprintfa("[spt_find_page] va value: %p -round_down-> %p\n", va, input_page.va);
e = hash_find(&spt->hash, &input_page.hash_elem); // hash_find는 hash 구조체와 hash_elem을 인수로 받음.
if (e != NULL)
{
dprintfa("[spt_find_page] found va from spt\n");
return hash_entry(e, struct page, hash_elem);
}
else
{
dprintfa("[spt_find_page] not found_page\n");
return NULL;
}
}디버깅을 찍어봤을 때 spt hast table에 제대로 hash값들이 삽입이 되는 것을 확인했지만 hash_find(&spt->hash, &input_page.hash_elem);함수가 제대로 찾지를 못하는 오류를 확인. 처음에는 page를 palloc으로 공간을 만들어줬지만 어떤 이유로 오류가 나는 관계로 stack확장 방식으로 변경했습니다.
/* spt에서 VA를 찾아서 페이지를 반환합니다. 실패 시 NULL을 반환합니다. */
struct page *
spt_find_page(struct supplemental_page_table *spt, void *va)
{
dprintfa("[spt_find_page] va: %p\n", va);
struct page *page = NULL;
// - 가상 주소 `va`에 해당하는 페이지를 supplemental page table에서 찾습니다.
// - 찾지 못하면 `NULL`을 반환합니다.
/*
* DEBUG: palloc으로 페이지를 따로 할당하고 free하는 식으로 검색용 페이지를 썼으나 탐색 실패. 왜 실패했는지는 모르겠음.
* 스택 변수로 바꾼 후 탐색 성공^^.
*/
struct page input_page;
memset(&input_page, 0, sizeof(input_page)); // 전체 초기화
dprintfa("[spt_find_page] input_page malloc\n");
struct hash_elem *e;
dprintfa("[spt_find_page] routine started\n");
input_page.va = pg_round_down(va);
dprintfa("[spt_find_page] va value: %p -round_down-> %p\n", va, input_page.va);
struct hash_iterator hi;
hash_first(&hi, &thread_current()->spt.hash);
while(hi.elem){
struct page *tmp_page = hash_entry(hi.elem, struct page, hash_elem);
dprintf("[setup_stack] iterating spt hash. %p\n", tmp_page->va);
uint64_t hash1 = page_hash(&input_page.hash_elem, NULL);
uint64_t hash2 = page_hash(&(*tmp_page).hash_elem, NULL);
dprintf("page 값: %p, 안에 있는 거 %p\n", input_page.va, tmp_page->va);
dprintf("시바 여기 있잖아. 찾는 거: %ld, 안에 있는 거 %ld\n", hash1, hash2);
hash_next(&hi);
}
e = hash_find(&spt->hash, &input_page.hash_elem); // hash_find는 hash 구조체와 hash_elem을 인수로 받음.
if (e != NULL)
{
dprintfa("[spt_find_page] found va from spt\n");
return hash_entry(e, struct page, hash_elem);
}
else
{
dprintfa("[spt_find_page] not found_page\n");
return NULL;
}
}struct page *tmp_page = hash_entry(hi.elem, struct page, hash_elem);
uint64_t hash1 = page_hash(&input_page.hash_elem, NULL);
uint64_t hash2 = page_hash(&(*tmp_page).hash_elem, NULL);
dprintf("page 값: %p, 안에 있는 거 %p\n", input_page.va, tmp_page->va); 이부분을 찍어봤을 때 hash2 값이 쓰레기 값이 들어가는 걸 확인함. 그러면 왜 쓰레기 값이 들어가는 걸까? 이걸 찾아야 한다...
