동기
import time
def sync_task():
print("🟢 작업 시작")
time.sleep(3) # 3초 동안 대기 (작업 처리 중)
print("✅ 작업 완료")
sync_task()
print("🎉 다음 작업 실행") # 작업이 끝난 후 실행됨
결과
🟢 작업 시작
✅ 작업 완료 (3초 후)
🎉 다음 작업 실행
요청된 작업이 끝나야 다음 작업이 실행되는 방식. CPU가 요청을 기다리는 동안 아무 작업도 하지 못함.
비동기
[시작]
↓
[작업 요청]
↓
[작업 백그라운드 실행]
───▶ (작업 완료?)
│ ┌───────┐
│ │ 아니오 │ → 다른 작업 수행 → (다시 확인)
│ └───────┘
│
▼ (예)
[결과 반환 및 콜백 실행]
↓
[프로그램 종료]
1️⃣ 작업 요청 → CPU가 특정 작업(예: 네트워크 요청, 파일 읽기 등)을 요청
2️⃣ 작업 수행 (백그라운드 처리) → 요청된 작업은 별도의 스레드나 이벤트 루프에서 실행됨
3️⃣ 다른 작업 수행 가능 → CPU는 해당 작업이 끝날 때까지 기다리지 않고 다른 작업을 실행
4️⃣ 작업 완료 후 알림 → 작업이 완료되면 콜백(callback) 함수나 이벤트 핸들러를 통해 CPU가 처리
import asyncio
async def task():
print("작업 시작")
await asyncio.sleep(3) # 3초 기다리지만, 다른 작업 수행 가능 (논블로킹)
print("작업 완료")
async def main():
print("프로그램 시작")
await task() # 비동기적으로 실행
print("프로그램 종료")
asyncio.run(main())
- await asyncio.sleep(3)을 사용하면 CPU가 3초 동안 다른 작업을 수행할 수 있습니다. 프로그램이 블로킹되지 않고 계속 진행됩니다.
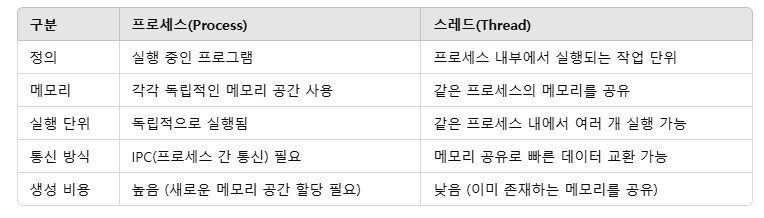
스레드
스레드는 같은 프로세스의 메모리를 공유하지만, 독립적인 실행 흐름을 가짐
[프로세스]
├── [코드(Code) 영역] → 실행 코드 저장 (공유됨)
├── [데이터(Data) 영역] → 전역 변수 저장 (공유됨)
├── [힙(Heap) 영역] → 동적 메모리 할당 (공유됨)
├── [스택(Stack) 영역] → 개별 스레드마다 별도 할당 (개별)
├── [스레드 1] → 개별 실행 흐름
├── [스레드 2] → 개별 실행 흐름
├── [스레드 3] → 개별 실행 흐름
- 스택(Stack): 각 스레드가 독립적으로 사용 (함수 호출, 지역 변수 저장)
- 코드(Code), 데이터(Data), 힙(Heap): 모든 스레드가 공유
프로세스 vs 스레드
스레드의 데이터 충돌 문제
import threading
counter = 0 # 공유 변수
def worker():
global counter
for _ in range(1000000): # 100만 번 증가
counter += 1
# 2개의 스레드를 생성하여 실행
threads = []
for _ in range(2):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
# 모든 스레드가 종료될 때까지 대기
for t in threads:
t.join()
print("최종 counter 값:", counter) # 이 값이 200만이 아닐 수도 있음!
counter += 1은 실제로 3개의 명령어로 실행됨
1️⃣ counter 값을 읽음 (LOAD)
2️⃣ 1 증가 (INCREMENT)
3️⃣ 다시 저장 (STORE)
만약 두 개의 스레드가 동시에 같은 값을 읽고 증가시키면, 하나의 증가가 덮어씌워질 수 있음.
결과
최종 counter 값: 1782345 (예상: 2000000)
- counter가 200만이 아니라 더 작은 값이 출력됨 → 데이터 손실 발생!
- 두 개의 스레드가 counter += 1을 동시에 수행하면서 값이 덮어씌워짐
스레드의 필요성
멀티 태스킹
스레드를 사용하면 한 개의 프로그램 내에서 여러 작업을 동시에 실행할 수 있습니다.
메인 스레드 → UI 화면을 업데이트
백그라운드 스레드 → 웹페이지 데이터를 다운로드
또 다른 스레드 → 오디오/비디오 스트리밍 실행
병렬 처리
싱글 스레드 프로그램은 한 개의 CPU 코어만 사용
멀티 스레드 프로그램은 여러 개의 코어를 동시에 활용 → 성능 향상.
예시: 이미지/영상 처리 프로그램
스레드 1 → 이미지 로드
스레드 2 → 필터 적용
스레드 3 → 결과 저장
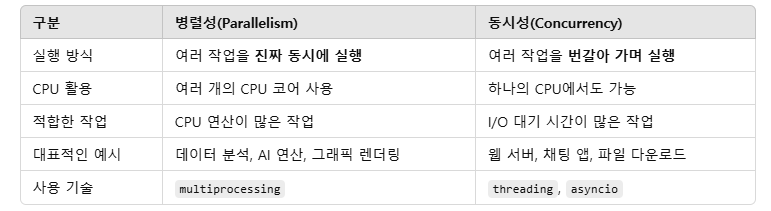
병렬성과 동시성
병렬성
여러 개의 작업을 물리적으로 동시에 실행하는 것을 의미합니다.
[시작]
↓
[데이터를 여러 개로 분할]
↓
[각 CPU 코어에서 동시에 실행]
┌──▶ [작업 1] ▶ 완료
├──▶ [작업 2] ▶ 완료
├──▶ [작업 3] ▶ 완료
└──▶ [작업 4] ▶ 완료
↓
[모든 결과를 병합]
↓
[처리 완료]
- 데이터를 여러 개의 부분으로 나눠서 동시에 처리
- 여러 개의 CPU 코어를 활용하여 성능을 극대화
- 모든 작업이 완료되면 결과를 병합
동시성
동시성은 CPU가 여러 개의 작업을 빠르게 번갈아 가면서 실행하는 것을 의미합니다.
[시작]
↓
[작업 1 요청] ──▶ [작업 1 실행] ─┐
↓ │
[작업 2 요청] ──▶ [작업 2 실행] ─┼▶ (작업 전환)
↓ │
[작업 3 요청] ──▶ [작업 3 실행] ─┘
↓
[작업 1 재개] ▶ 완료
↓
[작업 2 재개] ▶ 완료
↓
[작업 3 재개] ▶ 완료
↓
[처리 완료]
- CPU가 작업을 번갈아 가면서 실행 (즉시 완료되지 않음)
- 하나의 작업이 대기할 때 다른 작업이 실행됨
- 주로 네트워크 요청, 파일 I/O, 데이터베이스 처리 등에서 활용됨