참고자료
https://os2024.jeju.ai/week04/mlfq.html
https://os2024.jeju.ai/week04/lottery.html
https://os2024.jeju.ai/week04/lab-sched.html
https://os2024.jeju.ai/week04/lab-lottery.html
멀티 레벨 피드백 큐
MLFQ에 대한 이야기가 나온다.
MLFQ(다단계 피드백 큐) 스케줄링 알고리즘은 프로세스의 실행 특성에 따라 동적으로 우선순위를 조정합니다.
프로세스마다 우선순위가 부여되는 것 같고, 아무리 먼저 온 프로세스라도 우선순위가 뒤에 들어온 프로세스보다 낮으면 순위가 조정되는 것 같다.
타임 슬라이스는 각 프로세스에 할당되는 CPU 사용 시간 단위로, 이를 모두 사용하면 선점되고 자발적으로 양보하면 우선순위가 유지됩니다. 이러한 규칙을 통해 I/O를 많이 수행하는 프로세스는 높은 우선순위를 유지하고, CPU를 오래 사용하는 프로세스는 점차 낮은 우선순위로 이동하게 됩니다.
자신의 우선순위를 유지한다는게 프로세스마다 타임 슬라이스와 우선순위를 갖고 있다는 말인 지 궁금했다. 그렇다면 자신이 가지고 있는 타임 슬라이스를 전부 사용했을 경우 큐의 맨 끝에서부터 기다려야하고, 타임 슬라이스를 남겨두고 자동으로 자원을 반납한 프로세스는 자신의 우선 순위에 맞게 배정된다는 걸까?
답변:
- 프로세스는 타임 슬라이스와 우선순위 두 가지 속성을 가짐
- 자신의 타임 슬라이스를 다 쓰기 전에 cpu를 자발적으로 양보하면 현재 우선순위를 유지한다. 하지만 타임 슬라이스를 끝까지 다 사용하면 낮은 우선순위로 보내진다.
- 타임 슬라이스를 다 쓰면 우선순위가 한 단계 떨어지고 떨어진 레벨의 큐 맨 끝에서 기다린다.
- 타임 슬라이스를 남기고 양보하면 우선순위를 그대로 유지하고, 자신의 레벨에서 다음 기회를 얻는다.
결론 :
cpu 사용을 오래하는 프로세스는 후순위로 밀리게 되면서 cpu 사용 시간이 감소하고, 적게 사용하는 프로세스는 cpu 사용 시간이 증가한다.
타임 슬라이스를 끝까지 다 사용하면 낮은 우선순위로 보내진다고 했는데 우선순위를 어떻게 낮춘다는 말일까? 혹시 각 레벨이 존재하고, 각 레벨마다 우선순위 큐가 있는걸까? 그러면 처음에 1레벨에서 돌다가 타임 슬라이스를 전부 소진하면 2레벨로 떨어지는거고? 자동으로 자원을 반납하면 1레벨이 올라가나?
답변 :
- 레벨이 올라가는 경우는 없다.
- 스케줄러는 여러 개의 큐를 준비해 두고, 각 레벨마다 타임 슬라이스 길이도 다르게 정할 수 있다.
- 개별 프로세스에 대한 사전 정보가 전혀 없는 상황에서 이런 스케줄러를 어떻게 만들 수 있을까요?
- 프로세스가 실행되는 동안 그 특성을 파악하고, 이를 토대로 더 나은 스케줄링 결정을 내리려면 어떤 방법을 사용할 수 있을까요?
여기까지만 읽었을 때 실제로 프로세스가 실행되는 시간을 모르는데 어떻게 효율적인 스케줄링을 하지? 라는 의문이 떠오름. 답은 MLFQ이지만 MLFQ는 프로세스의 실행시간을 모르는 상태에서도 타임 슬라이스라는 개념을 두고, cpu를 효과적으로 사용할 수 있도록 관리한다.
MLFQ의 핵심은 바로 이 우선순위를 결정하는 방식에 있습니다. MLFQ는 각 프로세스에 고정된 우선순위를 부여하지 않고, 프로세스의 실행 특성에 따라 동적으로 우선순위를 조정합니다.
MLFQ는 각 프로세스에 고정된 우선순위를 부여하지 않고, 프로세스의 실행 특성에 따라 동적으로 우선순위를 조정한다?
답변 :
고정된 우선순위 값은 존재하지 않음. 오직 큐 레벨이 바뀌는 것임
만약 타임 슬라이스를 모두 사용해서 2레벨로 내려간 뒤에 cpu를 자동 반납했어도 현재 레벨은 유지되지만 큐의 맨 뒤에 삽입된다고 한다.
이렇게 스케줄링을 함으로써 얻는 이득이 뭐지? cpu를 독점하는 프로세스의 우선순위를 낮춰서 cpu 점유를 뒤로 늦춘다면 i/o를 통해서 자주 양보하고 자주 사용하는 프로세스의 반응속도를 높이기 위해서인가??
답변 :
대화형 프로세스의 우선순위를 높게 함으로써 cpu를 요청했을 때 바로 실행될 수 있게 하기 위함.
비례 배분
비례 배분 스케줄링은 각 작업(job)이나 프로세스에게 CPU 시간의 일정 비율을 보장하는 것을 목표로 합니다.
특정한 비율로 CPU 시간을 분배하도록 스케줄러를 어떻게 설계할 수 있을까요? 이를 위해 필요한 핵심 기술은 무엇이고, 그 기술은 얼마나 효과적일까요?
기존 스케줄링 기법은 우선순위를 부여해서 cpu를 점유할 프로세스를 선정하는 것이라면 비례 배분 스케줄링 기법은 cpu를 점유할 확률을 준다. 어떻게 특정 프로세스가 cpu를 점유할 확률을 높이거나 낮출 수 있을까?
내가 생각한 바는 프로세스마다 고유 count를 부여하고 랜덤으로 프로세스를 선정한다. 만약 특정 프로세스가 지급 받은 count를 다 사용할 경우 다른 프로세스에게 점유권이 넘어감으로 비율을 유지할 수 있을 거라고 생각했음...
예를 들어 각 프로세스에 우선순위 값을 부여하고, 그 값에 비례하는 시간 동안 CPU를 할당하는 방식 등이 있겠죠.
위는 비례 배분 스케줄링에 대한 설명이다. 우선순위를 부여한다는 것 자체가 특정 프로세스의 cpu 점유 순서를 높이는 거 아닌가? 만약 B(60)가 A(70)보다 앞에 있어도 A가 먼저 실행될 수 있도록 말이야. 근데 비례 배분은 특정 확률에 비례하여 cpu를 점유할 수 있도록 하는 거잖아. 약간 다르다고 생각하는데?
답변 :
고정 우선순위는 순서를 보장해주는 경우. 하지만 비례 배분은 시간 점유율을 보장한다. 여러 번 반복 실행했을 경우 cpu 사용량이 비율에 맞게 조정함.
만약 cpu 시간이 100ms라면 A에게 70ms를 B에게 30ms를 할당함으로써 여러 번 실행할 경우 비율이 맞도록 설정
추첨권 분배: 시스템은 각 프로세스의 중요도에 비례하여 추첨권을 나눠줍니다. 중요할수록 더 많은 추첨권을 받게 되고, 따라서 CPU 시간을 할당받을 확률도 높아집니다.
프로세스의 중요도는 어떻게 평가하지?
운영체제 설계자나 시스템 관리자가 정한다고 한다.
- 추첨: 스케줄러는 1부터 10까지의 번호 중 하나를 무작위로 선택합니다.
- 1~6이 나오면 프로세스 A가 선택됩니다.
- 7~9가 나오면 프로세스 B가 선택됩니다.
- 10이 나오면 프로세스 C가 선택됩니다.
처음에 1 ~ 10까지의 번호 중 무작위 번호가 뽑히면 해당 숫자가 list에서 빠지는 줄 알았는데 아니였다… 티켓 부여는 프로세스의 우선순위에 따라 부여된 것이고, 각 프로세스는 티켓의 수만큼 cpu를 점유할 수 있는 기회를 얻는다. 전체적으로 60%, 30%, 10% 비율로 cpu를 사용할 수 있게된 것이다.
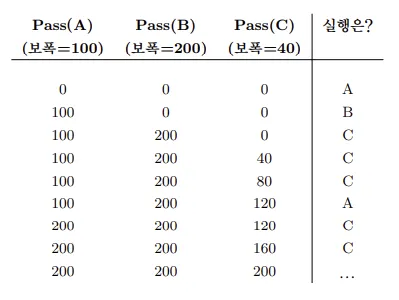
보폭 스케줄링
보폭 스케줄링에서는 각 프로세스마다 고유한 ‘보폭(stride)’ 값을 할당합니다. 프로세스가 CPU를 사용할 때마다 ‘pass’ 변수를 보폭만큼 증가시켜 CPU 사용량을 추적합니다. 스케줄러는 이 pass 값과 보폭을 기준으로 다음에 실행할 프로세스를 결정하게 됩니다.

- 초기화: 각 프로세스에 초기 보폭을 할당합니다. 보폭은 해당 프로세스의 우선순위나 중요도를 나타내는 값이 됩니다.
- 프로세스 선택: 실행 가능한 프로세스 중 가장 작은 pass 값을 가진 프로세스를 선택하여 CPU를 할당합니다.
- Pass 값 업데이트: 선택된 프로세스는 CPU를 사용하는 동안 자신의 pass 값을 보폭만큼 증가시킵니다. 이를 통해 다른 프로세스들도 공정하게 CPU를 사용할 수 있게 됩니다.
- 다른 프로세스 대기: CPU를 사용 중인 프로세스 외의 다른 프로세스들은 자신의 pass 값을 유지하거나 감소시킵니다. Pass 값을 감소시키면 더 빨리 CPU를 받을 수 있고, 유지하면 기존의 순서를 유지하게 됩니다.
- 반복: CPU 사용이 끝나면 위 과정을 반복하여 다음 프로세스를 선택합니다.
스케줄링 알고리즘
각 스케줄링 알고리즘에 따른 작업의 응답 시간, 반환 시간, 대기 시간을 계산하는 방법을 배웁니다.
이걸 왜 알아야 되는 거지?
어떤 스케줄링 기법이 어떤 상황에선 효율적이고, 어떤 상황에서는 비효율적인지 배울 수 있지 않을까?
대기 시간은 알겠는데 응답 시간, 반환 시간은 대체 뭘 의미하는 거지?
반환 시간 :
시스템에 들어와서 끝날 때까지 걸린 총 시간
사용자 관점에서 보면 총 처리 지연 시간이라고 보면 될 것 같다.
반환 시간은 도착했음에도 불구하고 먼저 실행되고 있는 프로세스가 있다면 대기해야 되는 시간 + 실행 시간이 얼마나 걸리는 지 확인할 수 있다.
계산식 → 반환 시간 = 완료 시각 - 도착 시각
대기 시간
계산식 → 대기 시간 = 반환 시간 - 실행 시간
응답 시간 :
응답 시간은 대기 시간이랑 비슷하다고 생각이 든다.
사용자가 어떤 작업을 요청했을 때 첫 반응이 오기까지의 시간을 말한다고 한다.
계산식 → 응답 시간 = 첫 실행 시작 시각 - 도착 시각
fifo 스케줄링 기법으로 실행 시간이 2,5,8인 프로세스를 실행시킨 결과
ARG 정책 FIFO
ARG 작업 수 3
ARG 최대 길이 10
ARG 시드 100
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 2 )
작업 1 ( 길이 = 5 )
작업 2 ( 길이 = 8 )
** 해결책 **
실행 흔적:
[ 시간 0 ] 작업 0 실행 2.00 초 ( 완료 시간 2.00 )
[ 시간 2 ] 작업 1 실행 5.00 초 ( 완료 시간 7.00 )
[ 시간 7 ] 작업 2 실행 8.00 초 ( 완료 시간 15.00 )
통계:
평균 대기 시간: 3.00 초
평균 회전 시간: 8.00 초
평균 응답 시간: 3.00 초이 작업을 fifo 스케줄링 기법을 사용했을 때 효율적으로 작업을 하는가? 에 대해 묻는다면 잘 모르겠다고 답할 것 같다…. 그래서 똑같은 조건에서 SJF 스케줄링 기법으로 다시 돌려보았다.
ARG 정책 SJF
ARG 작업 수 3
ARG 최대 길이 10
ARG 시드 100
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 2 )
작업 1 ( 길이 = 5 )
작업 2 ( 길이 = 8 )
** 해결책 **
실행 흔적:
[ 시간 0 ] 작업 0 실행 2.00 초 ( 완료 시간 2.00 )
[ 시간 2 ] 작업 1 실행 5.00 초 ( 완료 시간 7.00 )
[ 시간 7 ] 작업 2 실행 8.00 초 ( 완료 시간 15.00 )
통계:
평균 대기 시간: 3.00 초
평균 회전 시간: 8.00 초
평균 응답 시간: 3.00 초SJF스케줄링 기법은 실행 시간이 짧은 프로세스를 먼저 실행하기 때문에 똑같은 결과가 나왔다.
마지막으로 RR 스케줄링 기법으로 변경해서 돌려보았다.
ARG 정책 RR
ARG 작업 수 3
ARG 최대 길이 10
ARG 시드 100
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 2 )
작업 1 ( 길이 = 5 )
작업 2 ( 길이 = 8 )
** 해결책 **
실행 흔적:
[ 시간 0 ] 작업 0 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 1 ] 작업 1 실행 1.00 초 ( 남은 시간 4.00 )
[ 시간 2 ] 작업 2 실행 1.00 초 ( 남은 시간 7.00 )
[ 시간 3 ] 작업 0 실행 1.00 초 ( 남은 시간 0.00 )
[ 시간 4 ] 작업 1 실행 1.00 초 ( 남은 시간 3.00 )
[ 시간 5 ] 작업 2 실행 1.00 초 ( 남은 시간 6.00 )
[ 시간 6 ] 작업 1 실행 1.00 초 ( 남은 시간 2.00 )
[ 시간 7 ] 작업 2 실행 1.00 초 ( 남은 시간 5.00 )
[ 시간 8 ] 작업 1 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 9 ] 작업 2 실행 1.00 초 ( 남은 시간 4.00 )
[ 시간 10 ] 작업 1 실행 1.00 초 ( 남은 시간 0.00 )
[ 시간 11 ] 작업 2 실행 1.00 초 ( 남은 시간 3.00 )
[ 시간 12 ] 작업 2 실행 1.00 초 ( 남은 시간 2.00 )
[ 시간 13 ] 작업 2 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 14 ] 작업 2 실행 1.00 초 ( 남은 시간 0.00 )
통계:
작업 0 회전 시간: 4 초
작업 1 회전 시간: 11 초
작업 2 회전 시간: 15 초
평균 회전 시간: 10.00 초결론 :
실행 시간이 짧은 작업 순으로 도착했을 경우 fifo 스케줄링 기법은 효율적이다.
위와 같은 결과를 봤을 때 응답시간 이외에 대기 시간, 반환 시간이 다른 스케줄링에 비해 느린 RR 방식은 어떤 상황에서 장점이 있는 걸까?
내 생각인데 특정한 한 개의 프로세스가 다른 프로세스들보다 작업 시간이 훨씬 길다면 RR 방식이 더 효율적이지 않을까?
ARG 정책 RR
ARG 작업 목록 20,5,3
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 20.0 )
작업 1 ( 길이 = 5.0 )
작업 2 ( 길이 = 3.0 )
** 해결책 **
실행 흔적:
[ 시간 0.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 19.00 )
[ 시간 1.000000 ] 작업 1 실행 1.00 초 ( 남은 시간 4.00 )
[ 시간 2.000000 ] 작업 2 실행 1.00 초 ( 남은 시간 2.00 )
[ 시간 3.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 18.00 )
[ 시간 4.000000 ] 작업 1 실행 1.00 초 ( 남은 시간 3.00 )
[ 시간 5.000000 ] 작업 2 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 6.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 17.00 )
[ 시간 7.000000 ] 작업 1 실행 1.00 초 ( 남은 시간 2.00 )
[ 시간 8.000000 ] 작업 2 실행 1.00 초 ( 남은 시간 0.00 )
[ 시간 9.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 16.00 )
[ 시간 10.000000 ] 작업 1 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 11.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 15.00 )
[ 시간 12.000000 ] 작업 1 실행 1.00 초 ( 남은 시간 0.00 )
[ 시간 13.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 14.00 )
[ 시간 14.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 13.00 )
[ 시간 15.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 12.00 )
[ 시간 16.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 11.00 )
[ 시간 17.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 10.00 )
[ 시간 18.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 9.00 )
[ 시간 19.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 8.00 )
[ 시간 20.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 7.00 )
[ 시간 21.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 6.00 )
[ 시간 22.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 5.00 )
[ 시간 23.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 4.00 )
[ 시간 24.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 3.00 )
[ 시간 25.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 2.00 )
[ 시간 26.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 1.00 )
[ 시간 27.000000 ] 작업 0 실행 1.00 초 ( 남은 시간 0.00 )
통계:
작업 0 회전 시간: 28.0 초
작업 1 회전 시간: 13.0 초
작업 2 회전 시간: 9.0 초
평균 회전 시간: 16.67 초응답 시간 : 1.0
대기 시간 : 7.33
ARG 정책 FIFO
ARG 작업 목록 20,5,3
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 20.0 )
작업 1 ( 길이 = 5.0 )
작업 2 ( 길이 = 3.0 )
** 해결책 **
실행 흔적:
[ 시간 0 ] 작업 0 실행 20.00 초 ( 완료 시간 20.00 )
[ 시간 20 ] 작업 1 실행 5.00 초 ( 완료 시간 25.00 )
[ 시간 25 ] 작업 2 실행 3.00 초 ( 완료 시간 28.00 )
통계:
평균 대기 시간: 15.00 초
평균 회전 시간: 24.33 초
평균 응답 시간: 15.00 초fifo는 먼저 도착한 프로세스의 실행시간이 길다면 성능이 좋지 않다.
ARG 정책 SJF
ARG 작업 목록 20,5,3
각 작업의 실행 시간을 포함한 작업 목록입니다:
작업 0 ( 길이 = 20.0 )
작업 1 ( 길이 = 5.0 )
작업 2 ( 길이 = 3.0 )
** 해결책 **
실행 흔적:
[ 시간 0 ] 작업 2 실행 3.00 초 ( 완료 시간 3.00 )
[ 시간 3 ] 작업 1 실행 5.00 초 ( 완료 시간 8.00 )
[ 시간 8 ] 작업 0 실행 20.00 초 ( 완료 시간 28.00 )
통계:
평균 대기 시간: 3.67 초
평균 회전 시간: 13.00 초
평균 응답 시간: 3.67 초아무래도 SJF 스케줄링 특성상 실행시간이 짧은 프로세스를 우선적으로 실행하다보니 RR 방식보다 성능이 좋을 수 밖에 없다.
하지만 현실에서 SJF 방식은 프로세스의 실행 시간을 정확히 알 수 있는 방법이 없고, 실행 시간이 긴 프로세스는 계속 후순위로 밀리면서 기아 현상이 발생한다. 반면 RR 방식은 모든 프로세스를 공평하게 실행하므로 기아 현상이 발생하지 않고, 응답 시간이 짧다.
Lottery 스케줄링 알고리즘
일단 실행해봤다.
List: [25] [100] [50]
List: [25] [100] [50]
winner: 8 25
List: [25] [100] [50]
winner: 11 25
List: [25] [100] [50]
winner: 2 25
List: [25] [100] [50]
winner: 40 100
List: [25] [100] [50]
winner: 43 100
List: [25] [100] [50]
winner: 10 25
List: [25] [100] [50]
winner: 136 50
List: [25] [100] [50]
winner: 142 50
List: [25] [100] [50]
winner: 99 100
List: [25] [100] [50]
winner: 171 50
List: [25] [100] [50]
winner: 37 100
List: [25] [100] [50]
winner: 152 50
List: [25] [100] [50]
winner: 90 100
List: [25] [100] [50]
winner: 109 100
List: [25] [100] [50]
winner: 13 25
List: [25] [100] [50]
winner: 126 50
List: [25] [100] [50]
winner: 115 100
List: [25] [100] [50]
winner: 1 25
List: [25] [100] [50]
winner: 72 100
List: [25] [100] [50]
winner: 86 100
List: [25] [100] [50]
winner: 136 50
List: [25] [100] [50]
winner: 168 50
List: [25] [100] [50]
winner: 117 100
List: [25] [100] [50]
winner: 79 100
List: [25] [100] [50]
winner: 107 100
List: [25] [100] [50]
winner: 5 25
List: [25] [100] [50]
winner: 12 25
List: [25] [100] [50]
winner: 48 100
List: [25] [100] [50]
winner: 92 100
List: [25] [100] [50]
winner: 110 100
List: [25] [100] [50]
winner: 54 100
List: [25] [100] [50]
winner: 77 100
List: [25] [100] [50]
winner: 122 100
List: [25] [100] [50]
winner: 33 100
List: [25] [100] [50]
winner: 94 100
List: [25] [100] [50]
winner: 142 50
List: [25] [100] [50]
winner: 43 100
List: [25] [100] [50]
winner: 56 100
List: [25] [100] [50]
winner: 86 100
List: [25] [100] [50]
winner: 142 50
List: [25] [100] [50]
winner: 29 100
List: [25] [100] [50]
winner: 123 100
List: [25] [100] [50]
winner: 96 100
List: [25] [100] [50]
winner: 119 100
List: [25] [100] [50]
winner: 34 100
List: [25] [100] [50]
winner: 87 100
List: [25] [100] [50]
winner: 48 100
List: [25] [100] [50]
winner: 149 50
List: [25] [100] [50]
winner: 65 100
List: [25] [100] [50]
winner: 120 100
List: [25] [100] [50]
winner: 38 100
List: [25] [100] [50]
winner: 26 100
List: [25] [100] [50]
winner: 91 100
List: [25] [100] [50]
winner: 155 50
List: [25] [100] [50]
winner: 106 100
List: [25] [100] [50]
winner: 23 25
List: [25] [100] [50]
winner: 137 50
List: [25] [100] [50]
winner: 95 100
List: [25] [100] [50]
winner: 71 100
List: [25] [100] [50]
winner: 31 100
List: [25] [100] [50]
winner: 30 100
List: [25] [100] [50]
winner: 125 50
List: [25] [100] [50]
winner: 109 100
List: [25] [100] [50]
winner: 152 50
List: [25] [100] [50]
winner: 136 50
List: [25] [100] [50]
winner: 5 25
List: [25] [100] [50]
winner: 96 100
List: [25] [100] [50]
winner: 4 25
List: [25] [100] [50]
winner: 38 100
List: [25] [100] [50]
winner: 7 25
List: [25] [100] [50]
winner: 124 100
List: [25] [100] [50]
winner: 45 100
List: [25] [100] [50]
winner: 107 100
List: [25] [100] [50]
winner: 45 100
List: [25] [100] [50]
winner: 164 50
List: [25] [100] [50]
winner: 142 50
List: [25] [100] [50]
winner: 109 100
List: [25] [100] [50]
winner: 14 25
List: [25] [100] [50]
winner: 93 100
List: [25] [100] [50]
winner: 0 25
List: [25] [100] [50]
winner: 112 100
List: [25] [100] [50]
winner: 108 100
List: [25] [100] [50]
winner: 26 100
List: [25] [100] [50]
winner: 28 100
List: [25] [100] [50]
winner: 88 100
List: [25] [100] [50]
winner: 109 100
List: [25] [100] [50]
winner: 28 100
List: [25] [100] [50]
winner: 51 100
List: [25] [100] [50]
winner: 29 100
List: [25] [100] [50]
winner: 99 100
List: [25] [100] [50]
winner: 82 100
List: [25] [100] [50]
winner: 60 100
List: [25] [100] [50]
winner: 26 100
List: [25] [100] [50]
winner: 168 50
List: [25] [100] [50]
winner: 14 25
List: [25] [100] [50]
winner: 162 50
List: [25] [100] [50]
winner: 151 50
List: [25] [100] [50]
winner: 111 100
List: [25] [100] [50]
winner: 144 50
List: [25] [100] [50]
winner: 14 25결과만보면 3개의 프로세스가 있고, 각 프로세스의 실행 시간을 list에 저장했다. 랜덤으로 티켓을 뽑으면서 뽑힌 티켓에 해당하는 프로세스를 실행하고 있다.
0 ~ 24 → 프로세스 1
25 ~ 124 → 프로세스 2
125 ~ 174 → 프로세스 3
이 된다.
특정 프로세스가 당첨될 확률 = (그 프로세스가 가진 티켓 수) ÷ (총 티켓 수)
결과를 따라 확률을 계산해봤을 때
프로세스 1 → 14%
프로세스 2 → 57%
프로세스 3 → 29%
100회 추첨을 진행했을 때
프로세스 1 → 16%
프로세스 2 → 63%
프로세스 3 → 21%
1000회도 돌려봤는데 터미널에 결과가 다 안나와서 패스…. 아무튼 1만회, 10만회 이렇게 추첨 횟수가 많아질 수록 예상했던 확률과 점차 가까워지게 된다.
간단하게 코드 분석
void insert(int tickets)
{
// 새로운 노드를 생성하고 메모리 할당
struct node_t *tmp = malloc(sizeof(struct node_t));
assert(tmp != NULL);
// 새로운 노드의 티켓 수를 설정하고 리스트의 헤드에 삽입
tmp->tickets = tickets;
tmp->next = head;
head = tmp;
// 전역 티켓 카운트 업데이트
gtickets += tickets;
}- 노드를 하나 생성하고, tmp에 ticket 부여
- tmp의 다음 노드로 head를 이동시키고, tmp가 head를 가리키도록 함.
- 티켓 하나 생성했으면 ticket 카운트를 1 up
void print_list()
{
struct node_t *curr = head;
printf("List: ");
// 리스트를 순회하며 각 노드의 티켓 수를 출력
while (curr)
{
printf("[%d] ", curr->tickets);
curr = curr->next;
}
printf("\n");
}주석에 적혀있는 게 다인 것 같다….
int main(int argc, char *argv[])
{
if (argc != 3)
{
fprintf(stderr, "usage: lottery <seed> <loops>\n");
exit(1);
}
// 명령행 인자에서 시드와 루프 횟수를 가져옴
int seed = atoi(argv[1]);
int loops = atoi(argv[2]);
// 랜덤 시드 설정
srandom(seed);
// 리스트에 작업들을 추가하고 각 작업에 티켓 수를 할당
insert(50);
insert(100);
insert(25);
// 리스트 출력
print_list();
int i;
for (i = 0; i < loops; i++)
{
int counter = 0;
// 전체 티켓 수 범위 내에서 랜덤한 당첨 번호 선택
int winner = random() % gtickets;
struct node_t *current = head;
// 티켓 수의 합이 당첨 번호보다 클 때까지 리스트를 순회
while (current)
{
counter = counter + current->tickets;
if (counter > winner)
break; // 당첨자 찾음
current = current->next;
}
// 당첨자 출력 및 스케줄링
print_list();
printf("winner: %d %d\n\n", winner, current->tickets);
}
return 0;
}
main함수에서는 명령행 인자로 시드와 루프 횟수를 받아옵니다.- 랜덤 시드를 설정하고, 리스트에 작업들을 추가합니다.
- 지정된 루프 횟수만큼 반복하면서 다음을 수행합니다:
- 전체 티켓 수 범위 내에서 랜덤한 당첨 번호를 선택합니다.
- 리스트를 순회하면서 티켓 수의 합이 당첨 번호보다 클 때까지 탐색합니다.
- 당첨된 작업을 출력하고 스케줄링합니다.
- 프로그램을 종료합니다.
이 코드는 lottery 스케줄링의 기본
친절하게 강의서에 설명을 해놨다…
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
// 전역 티켓 카운트
int gtickets = 0;
struct node_t
{
int tickets;
struct node_t *next;
};
struct node_t *head = NULL;
void insert(int tickets)
{
// 새로운 노드를 생성하고 메모리 할당
struct node_t *tmp = malloc(sizeof(struct node_t));
assert(tmp != NULL);
// 새로운 노드의 티켓 수를 설정하고 리스트의 헤드에 삽입
tmp->tickets = tickets;
tmp->next = head;
head = tmp;
// 전역 티켓 카운트 업데이트
gtickets += tickets;
}
void print_list()
{
struct node_t *curr = head;
printf("List: ");
// 리스트를 순회하며 각 노드의 티켓 수를 출력
while (curr)
{
printf("[%d] ", curr->tickets);
curr = curr->next;
}
printf("\n");
}
int main(int argc, char *argv[])
{
if (argc != 3)
{
fprintf(stderr, "usage: lottery <seed> <loops>\n");
exit(1);
}
// 명령행 인자에서 시드와 루프 횟수를 가져옴
int seed = atoi(argv[1]);
int loops = atoi(argv[2]);
// 랜덤 시드 설정
srandom(seed);
// 리스트에 작업들을 추가하고 각 작업에 티켓 수를 할당
insert(50);
insert(100);
insert(25);
// 리스트 출력
print_list();
int i;
for (i = 0; i < loops; i++)
{
int counter = 0;
// 전체 티켓 수 범위 내에서 랜덤한 당첨 번호 선택
int winner = random() % gtickets;
struct node_t *current = head;
// 티켓 수의 합이 당첨 번호보다 클 때까지 리스트를 순회
while (current)
{
counter = counter + current->tickets;
if (counter > winner)
break; // 당첨자 찾음
current = current->next;
}
// 당첨자 출력 및 스케줄링
print_list();
printf("winner: %d %d\n\n", winner, current->tickets);
}
return 0;
}전체 코드는 위와 같은데
구현 부분에 아래와 같이 설명해놨다..
- 연결 리스트를 사용하여 작업 큐를 구현합니다.
- 각 작업에는 티켓 수가 할당되며, 전체 티켓 수는
gtickets변수에 저장됩니다.insert함수를 사용하여 새로운 작업을 큐에 추가하고 티켓 수를 할당합니다.print_list함수를 사용하여 현재 작업 큐의 상태를 출력합니다.main함수에서는 명령행 인자로 시드와 루프 횟수를 받아와 Lottery 스케줄링을 수행합니다.
- 랜덤 번호를 생성하여 당첨된 티켓을 선택합니다.
- 선택된 티켓에 해당하는 작업을 찾아 스케줄링합니다.
- 지정된 루프 횟수만큼 스케줄링을 반복합니다.
원래는 이것만 보고 구현해보라고 작성해놓은 것 같은데… 솔직히 나는 못한다… 나는 가짜 중에서도 가짜인 듯…
과제
3개의 작업과 난수 시드 1, 2, 3으로 시뮬레이션한 솔루션을 계산하세요.
난수 시드 3 :
ARG jlist
ARG jobs 3
ARG maxlen 10
ARG maxticket 100
ARG quantum 1
ARG seed 3
Here is the job list, with the run time of each job:
Job 0 ( length = 2, tickets = 54 )
Job 1 ( length = 3, tickets = 60 )
Job 2 ( length = 6, tickets = 6 )
Here is the set of random numbers you will need (at most):
Random 13168
Random 837469
Random 259354
Random 234331
Random 995645
Random 470263
Random 836462
Random 476353
Random 639068
Random 150616
Random 634861일단 결과가 어떤 의미를 가지고 있는 지 알아야 한다…
3개의 프로세스가 작업을 하고 있고, 실행 시간과 부여 받은 티켓 목록을 표시하고 있다.
